本文主要是介绍构建家庭NAS之二:TrueNAS Scale规划、安装与配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先声明一下,我用的版本是TrueNAS SCALE 24.04.1.1(目前的最新版本),其它版本的界面和操作方式或有不同。我安装使用过程中网上的一些教程里的操作方式和这个版本不一样,造成了一些困扰。
TrueNAS SCALE的最低硬件需求:
- 双核64位CPU
- 8 GB内存(推荐16GB)
- 16 GB SSD 系统盘
- 2个相同容量的数据盘(其实1个盘也可以,后面细讲)
- 不需要硬件RAID卡
存储规划
TrueNAS SCALE对家庭用户不太友好的地方就是它的存储设计。家庭用户很多时候希望用一块硬盘快速跑起来,后续再根据需要逐步增加硬盘。然而官方文档里提到最低配置是1块系统盘+2块数据盘,也就是最少也要3块盘,这个最低要求其实是相当高。不过经过一番学习和尝试之后,我发现基本上用一块硬盘(的费用)也是可以用起来的,只是没有数据冗余和保护。不过后期也可以方便地转换为镜像方式,从而提供额外的数据保护。
系统盘
首先就是系统盘,官方要求必须是一块单独的SSD,上面不能存用户数据。这个要求对于企业不是大事,但对于普通玩家不仅意味着要多花一笔钱,还要额外占用一个宝贵的硬盘接口。想想心里就不爽,有没有其它办法呢?
后来发现一个接近完美的解决方案:Intel的傲腾M10 SSD 16GB,海鲜市场上只要十几块钱包邮。说“接近”完美,是因为这个方案虽然花钱很少,但是仍然需要占用一个M.2接口。

额外的补充:
- 购买的时候也考虑过海鲜市场的质量和可靠性问题,后来觉得一是系统盘坏了恢复起来不难,二是价格很便宜,翻车了损失也不大。读者可以自行斟酌。
- 不需要考虑那些32G/64G或者更高容量的傲腾,因为价格贵了很多,而且多出来的容量装系统也用不上。
- 从第 12 代和第 13 代开始,英特尔处理器将不再支持傲腾技术。虽然我用的是12代处理器,但这个消息对我其实没有影响,因为上面写的停止支持是指把傲腾作为机械硬盘的加速缓存。把它作为独立的SSD硬盘使用是没有问题的。
- 因为针对需要一块单独的系统盘这个问题吐槽的用户太多,TrueNAS官方专门做了一个回应。意思就是这才是我们(企业)的应用场景,我们要把宝贵的开发资源用在服务客户上,巴拉巴拉,所以请不要再提这个需求给我们了。如果你觉得不爽,欢迎你选择其它更合适的系统或自己开发一个。详情见:
I have to waste an entire drive just for booting?
实际上我个人是挺理解官方立场的,毕竟人家不是专门做慈善,也要挣钱养家。感谢iXsystems开发和分享了这么好的产品。 - 个别高手会从数据硬盘里划出一个分区来安装系统。这个方案在技术上可以操作,但是后续故障恢复等比较麻烦,需要对Linux非常了解。所以普通用户还是算了吧。好奇心强的读者可以参考这篇文章:
Install TrueNAS SCALE on a partition instead of the full disk
- 如果硬盘接口比较少的话,把系统装在U盘上也是一个选项。有兴趣的读者可以试试。
数据盘
TrueNAS的存储是基于ZFS的。简单来说,ZFS是一个超大容量(个人用户基本用不上)、数据高度可靠的文件系统。RAIDZ是基于ZFS的RAID实现,和传统的RAID很类似,但也有一些自己的特点。比如RAIDZ的块大小是可变的。希望对ZFS/RAIDZ有更多了解的读者请参考:
- 初学者指南:ZFS 是什么,为什么要使用 ZFS?
- What is RAIDZ
ZFS的一些特性很酷,但也有一些不那么讨人喜欢的地方。最典型的就是至少需要两块盘!
下面是RAIDZ 级别比较表:
| - | Strip | Mirror | RAIDZ1 | RAIDZ2 | RAIDZ3 | Strip+Mirror |
|---|---|---|---|---|---|---|
| 最小磁盘数量 | 1 | 2 | 2 | 4 | 5 | 4 |
| 允许坏掉的磁盘数量 | 无 | N-1 | 1 | 2 | 3 | N个磁盘组成的Mirror中的 (N-1) 个磁盘 |
| 磁盘空间开销 | 无 | (N-1)/N | 1 | 2 | 3 | (N-1)*P 基于N个磁盘组成Mirror再组成P个Strip |
| 读取速度 | 快 | 快 | 慢 | 慢 | 慢 | 快 |
| 写入速度 | 快 | 一般 | 慢 | 慢 | 慢 | 一般 |
| 硬件成本 | 便宜 | 最高 | 高 | 很高 | 很高 | 最高 |
其实上面这么复杂的表格可以简化成下面几种场景:
- 只有1个硬盘:只能选strip。也就是说只有一个数据盘也是可以用的,和前面提到的官方最低推荐配置有点不同。预算紧张的用户可以用strip起步,后期有钱了买一个相同大小的盘升级为mirror。所以前面“至少需要2块盘”的说法更准确一点的话可以改成:如果要发挥ZFS的全部特性,至少需要2块盘。
- 有2个相同大小的硬盘:追求性能的用户组strip;需要可靠性的用户组mirror。
- 有4个相同大小的硬盘:推荐strip+mirror。
- 有更多硬盘的用户:土豪你想怎么玩都可以。
我自己因为有2个4TB+2个2TB,所以组了两个mirror。
系统安装
TrueNAS SCALE的安装过程简单明了。我这里不会手把手地写每个步骤,只是把要点简单说一下:
- 下载官方的镜像文件
- 用rufus(或其它工具)把下载的镜像文件烧录到一个U盘上,烧录的时候不要选ISO模式,选DD模式。
- 用烧录好的U盘启动,按照提示一步一步操作就好,基本只需要按回车。需要详细步骤和截图的读者可以参考这篇文章:
How to Get Started with TrueNAS Scale
配置存储
ZFS的基本概念
ZFS存储的基本概念有如下4个。注意这里只说我自己简化后的理解,实际ZFS比这个复杂。
- 磁盘(disk):这个就不用多做解释了。
- 虚拟设备(vdev):可以理解成多个磁盘组成的RAID设备。升级一个vdev要把vdev里所有磁盘一起升级(换掉)。当然也有例外,后面再说。
- 池(pool):多个虚拟设备组成一个池,我理解主要是把较小而便于管理的vdev组成更大的存储。为什么说便于管理呢,如果整个NAS只有一个大的vdev的话,要升级磁盘容量就需要把所有磁盘全部换掉,这是很麻烦而且很费钱的动作。有多个vdev的话,就可以按照vdev一个一个地升级。组成池的虚拟设备的RAIDZ模式必须相同,不能把一个条带化的虚拟设备(striped vdev)和一个镜像的虚拟设备(mirrored vdev)组成一个池。
- 数据集(dataset):可以理解成UNIX/Linux里的文件系统或windows里的盘符,把pool划分成dataset的目的在于设置不同的用途和存储参数,比如块的大小,是否压缩等。另外在设置文件共享的时候,只能共享一个dataset,不能共享pool。
可以借用trueNAS网站上的一张图来说明这几个概念:
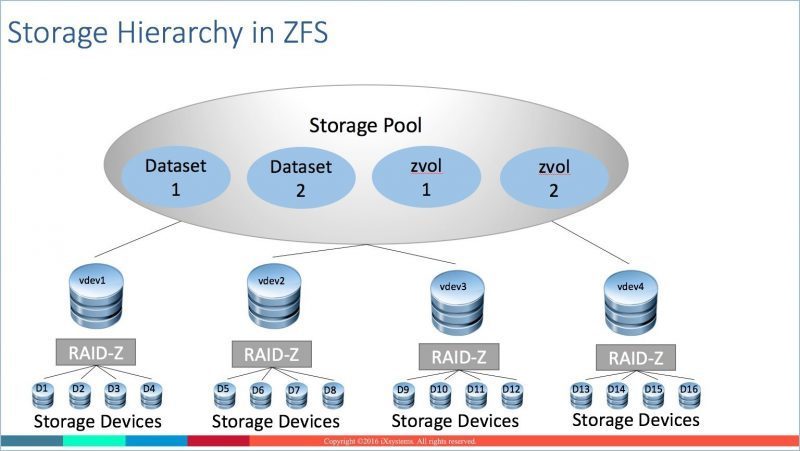
明白上面这几个概念之后,再去配置存储就会比较直观明了。
配置存储池和数据集
这部分我也不打算一步一步地讲。可以参考下列资料:
- 【干货】小白快速上手TrueNAS!第二期:基础设置+存储池建立+快照建立
- 官方文档:Creating Pools
值得单独说一下的是:
- ZFS的pool在系统间可以很方便地迁移,如果在一台机器上创建了一个pool,可以把组成这个pool的磁盘卸下来安装到另外一台机器上,再导入(import)这个pool,你的数据就全部回来了。和单个磁盘的迁移几乎一样,不需要处理配置信息这些比较麻烦的事情。
- 这个特性带来的一个好处是你的NAS装好以后,可以放心地重装系统而不用担心数据丢失。比如我在测试速度的时候就把系统从TrueNAS改成Ubuntu,再把在TrueNAS中创建的pool导入到Ubuntu中进行测试,非常方便。
关于存储的一些碎碎念
因为NAS最重要的功能就是数据存储和数据安全,所以对这部分就多说几句。不感兴趣或没时间的读者可以直接跳过。
- 可以只用一个硬盘玩TrueNAS吗?答案是“可以”。可以像我一样找一个傲腾做系统盘,或者把系统装在U盘上。数据盘只用一个盘,使用条带模式。后期方便的时候可以再买一块盘升级为镜像模式。升级镜像模式的操作很简单,原来的数据也不会损坏。
- 只有一块数据盘又想实现数据可靠性怎么办?可以用一个外置移动硬盘备份重要文件。或者把文件从NAS备份到网盘上。后面这个方法也是TrueNAS SCALE官方推荐方案(之一),我有时间准备试一下。
- 同一个虚拟设备(vdev)是否可以混用不同容量的硬盘?答案其实是“可以”,官方说不行,但其实只是不推荐。因为这么做的话,系统会按照这个vdev里所有磁盘里面容量最小的那个盘来使用这一组盘。比如你把一个1TB和一个2TB组成mirror,系统会把它们当成两个1TB的盘,组完后的实际可用容量只有1TB。
这个特性其实可以用在容量升级场景里面。比如我有一个2TBx2的镜像vdev,我想升级为4TBx2,但是硬盘接口有限,不能同时安装新旧4块硬盘,这时可以先拆下一块2TB硬盘,把一块4TB装上去,然后把这个4T的盘加入镜像vdev,让系统进行数据恢复。恢复完成之后系统有一个2T+4T的镜像vdev(实际可用容量2TB)。然后再把另外一个4TB替换2TB,再次恢复。第二次恢复完成后把整个vdev做一次expand操作。这样就可以在有限的接口情况下把原来的磁盘组进行容量升级,并且不需要额外的数据备份。 - 一个池里面是否可以混用不同容量的vdev。答案是“可以”。但建议各vdev的RAID模式保持一致。
- 系统盘要不要做镜像?我的选择是不要,理由是对我来说没有必要。系统坏了可以重装,重装之后把原来的ZFS池导入进来也很方便。
- 像slog/ZIL这样的高级功能有什么用,要不要配一个?slog我的理解是用来降低写入延迟的,一般用在高并发的数据库存储这样的场景,家用的文件共享和备份用不上。
- L2ARC有没有必要?这个是用SSD硬盘作为缓存来提高读取速度的,通常是有部分数据需要经常访问的场景下用到。家用也基本没必要。如果反复读取的数据不是很大,可以增加内存,把这些数据缓存到内存里。如果这部分数据大到内存放不下,设置L2ARC才有意义。
设置用户和权限
TrueNAS的权限管理其实和Linux是一样的(似乎是废话)。我的做法是这样的:
- 为家庭成员建一个组(group),比如"myfamily"。
- 每个家庭成员建一个用户,用户组(Primary Group)设置为上面建立的"myfamily"。创建用户的时候,如果需要让用户通过SSH远程登录,就把“允许SSH密码登录”勾选上。
设置共享和权限
这部分也比较直观,直接按照界面的提示来就可以了,也可以参考上面那个司波图的视频。
需要注意的是:共享的路径必须要选池下面创建的数据集,不能直接共享池。比如,我的池名称叫“test”,这个池会自动挂载到系统路径/mnt/test下面。我在池里创建了一个叫做“downloads”的数据集,这样在共享的时候,就需要选择/mnt/test/downloads作为共享路径,不能选择/mnt/test。

小结
安装和配置TrueNAS SCALE的时候,最重要的是规划存储方案。对家庭用户来说,如果追求性能、不怕数据丢失、那就用条带化(strip)方案,但对于大多数人来说,镜像才是最实用的。
家庭用户完全可以用一块数据盘起步,后期根据需要添加硬盘。操作也比较简单。当然也有一些限制,比如一个vdev里的所有磁盘容量要保持一致,要替换或者升级最好一起做,不然会有容量的浪费。
接下来,准备结合自己的下载需求,说一下如何使用在TrueNAS SCALE上使用docker。
这篇关于构建家庭NAS之二:TrueNAS Scale规划、安装与配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








