本文主要是介绍Building3D An Urban-Scale Dataset and Benchmarks 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章主页
Building3D
任务
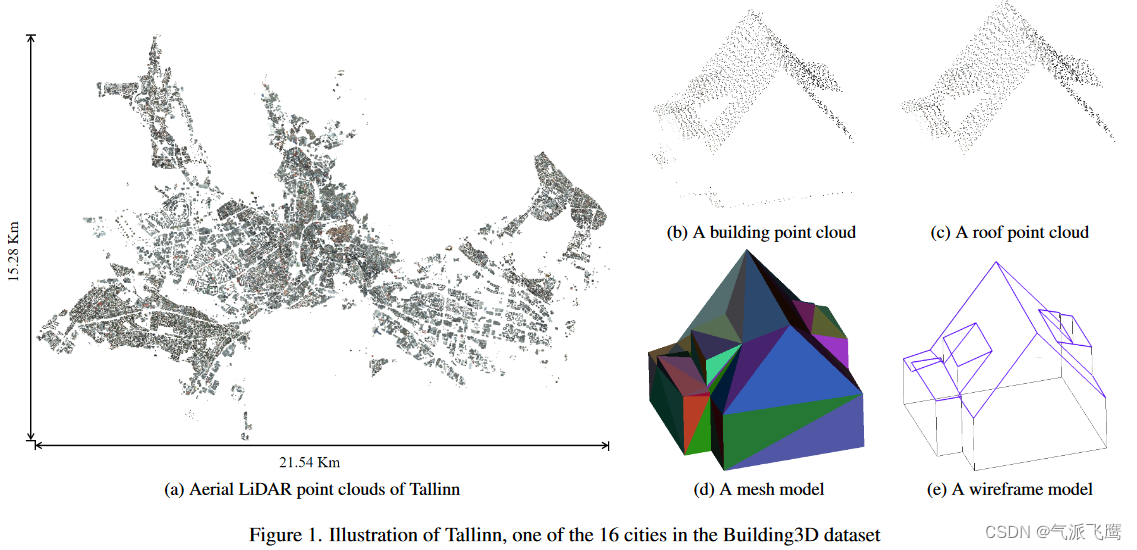
提出了一个城市规模的数据集,由超过 16 万座建筑物以及相应的点云、网格和线框模型组成,覆盖爱沙尼亚的 16 个城市,面积约 998 平方公里。
动机
现有的3D建模数据集主要集中在家具或汽车等常见物体上。缺乏建筑数据集已成为将深度学习技术应用于城市建模等特定领域的主要障碍。
要点
数据集包含原始点云,建筑物点云,屋顶点云,以及网格模型和线框模型。
贡献
Building3D 是第一个也是最大的城市规模建筑建模基准,可以对监督学习方法和自监督学习方法进行比较。
相关工作
只考虑相关的 3D 建模数据集,重点关注基于点云的城市建模数据集。
- ShapeNet 是目前最流行的用于零件分割、点云补全和重建的 3D 对象数据集之一。
- RoofN3D 是为 3D 建筑重建而设计的。
- City3D 是一个大规模建筑重建数据集,由约2万个建筑网格模型和航空LiDAR点云组成。
- UrbanScene3D 涵盖 10 个合成场景和 6 个真实世界场景。
方法
- 建筑物点云 原始LiDAR点云由高精度RIEGL VQ-1560i扫描仪在海拔2600米处收集,然后以LAZ格式存储。点云的相对精度为20毫米。点云密度为每平方米30.314点,点到点距离为0.1816m。对于 3D 建筑物重建,删除不相关的点云,仅保留建筑物点云。每个建筑物点云均以 XYZ 格式存储,包括 XYZ 坐标、RGB 颜色、近红外信息、强度和反射率。
- 屋顶点云 删除所有代表立面的点。基本上,几乎所有立面都垂直于 XY 平面。计算每个网格面的法线,并删除所有法线与 XY 平面平行的网格面,以生成屋顶网格模型。如果一个点到屋顶网格模型的距离在给定阈值内,则该点被分类为屋顶。
- 网格模型 建筑网格模型是通过使用 Terrasolid 软件进行手动编辑,根据航空 LiDAR 点云和建筑足迹创建的。这些网格模型是典型的 LoD2 模型,包括详细且真实的屋顶表示。
- 线框模型 计算每个网格的法线。如果两个相邻三角形网格的法线近似平行,则表明它们共面,共享边将被移除。删除所有共享边后,获得具有冗余顶点的粗线框模型。粗线框模型还包含可以合并为长边的短边。最后,通过去除所有冗余顶点并合并短边生成精细线框模型,然后由专业技术人员审核和调整。
实验
评估指标
平均角偏移 (ACO)、精度、召回率和 F1 分数、3D 网格 IoU 和均方根误差 (RMSE)。
ACO 是预测角点和真实角点之间的平均偏移量。
通过混淆矩阵计算角点精度(CP)、边缘精度(EP)、角点召回率(CR)和边缘召回率(ER),以评估角点和边缘分类的准确性。
本文提出了一种自监督方法和一种无监督方法,与现在常用的点云神经网络提取特征点做基准测试,实验结果见论文原文第4章。
应用
- 构建语义和部分分割
- 网格简化
- 足迹检测
- 空中路径规划
这篇关于Building3D An Urban-Scale Dataset and Benchmarks 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)