benchmarks专题

BubbleML: A Multiphase Multiphysics Dataset and Benchmarks for Machine Learning
我们使用以下六个分类标准: 研究方法: 这个标准根据如何收集和分析数据来区分研究方法。 实验研究,如参考文献[64]中的研究,涉及在受控环境中研究人员操纵变量并观察结果的物理实验。这种方法对于收集真实世界的数据很有价值,但可能成本高且耗时。模拟研究利用计算模型来模拟相变现象。本文介绍的 BubbleML 数据集就是这种方法的一个例子,它提供了一种经济有效的方法来生成具有精确地面真实信息的大量数据
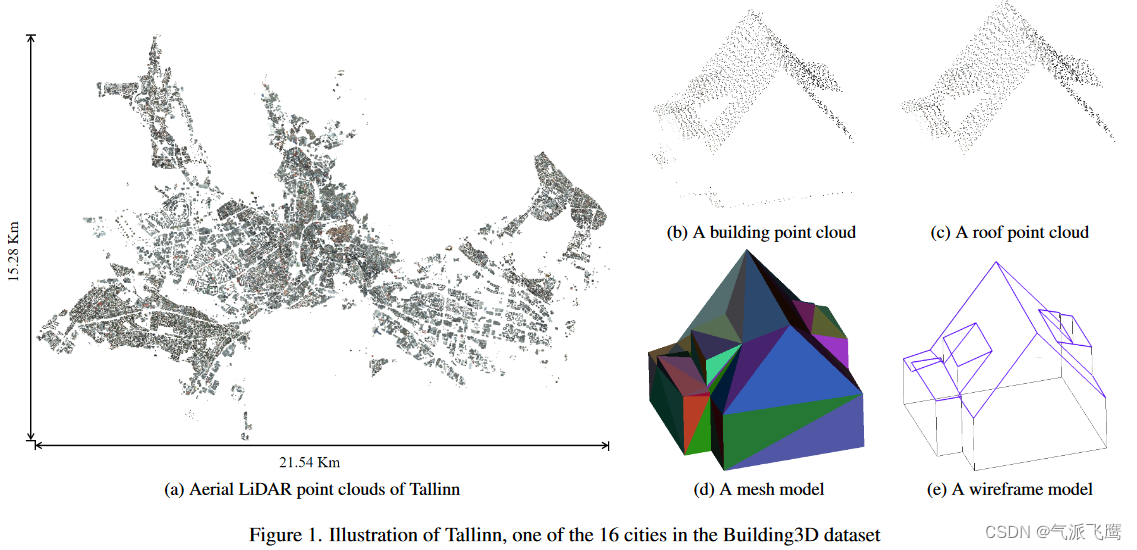
Building3D An Urban-Scale Dataset and Benchmarks 论文阅读
文章主页 Building3D 任务 提出了一个城市规模的数据集,由超过 16 万座建筑物以及相应的点云、网格和线框模型组成,覆盖爱沙尼亚的 16 个城市,面积约 998 平方公里。 动机 现有的3D建模数据集主要集中在家具或汽车等常见物体上。缺乏建筑数据集已成为将深度学习技术应用于城市建模等特定领域的主要障碍。 要点 数据集包含原始点云,建筑物点云,屋顶点云,以及网格模型和线框模
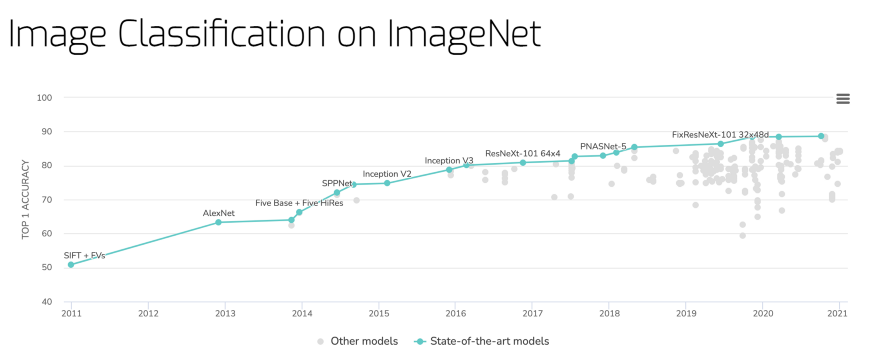
Papers with Code 2020 全年回顾(顶流论文+顶流代码+Benchmarks)
点击上方“计算机视觉工坊”,选择“星标” 干货第一时间送达 本文转载自:AI公园 作者:Ross Taylor 编译:ronghuaiyang 导读 2020年Papers with Code 中最顶流的论文,代码和benchmark。 Papers with Code 中收集了各种机器学习的内容:论文,代码,结果,方便发现和比较。通过这些数据,我们可以了解ML社区中,今年哪些东西最有意
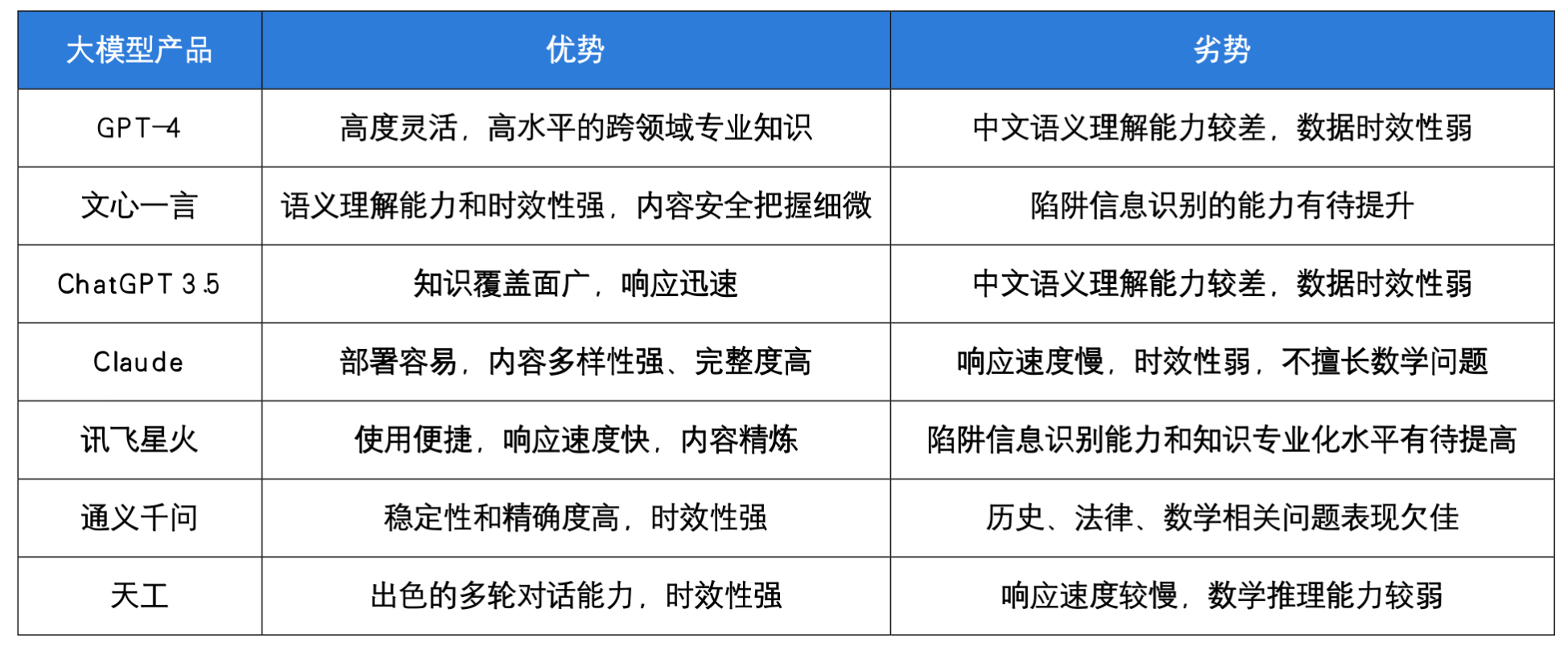
【LLM评估篇】Ceval | rouge | MMLU benchmarks
note 一些大模型的评估基准benchmark:多轮:MTBench关注评估:agent bench长文本评估:longbench,longeval工具调用评估:toolbench安全评估:cvalue,safetyprompt等 文章目录 note常见评测benchmarkMMLUSuperCLUE:中文通用大模型综合性评测基准知识评估:C-EvalC-EvalGSM8KBBH 工具

为何需关注各ZKP方案的benchmarks?
1. 引言 近期,研究人员和工程人员有大量关于谁是最好的证明系统的争论: 2023年8月29日,StarkWare团队对比了FRI和KZG2023年8月30日,JustinThaler和Srinath Setty讨论FRI和KZG谁的性能更佳? 不过,在深入benchmark细节之前,需有一些更明确的标准来说明是什么使某些东西在工程方面更具性能或更有用。此外,性能和适用性有时取决于应用场