西瓜专题

机器学习(西瓜书)第 4 章决策树
4.1 决策树基本流程 决策树模型 基本流程 在第⑵种情形下,我们把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别;在第⑶种情形下,同样把当前结点标记为叶结点,但将其类别设定为其父结点所含样本最多的类别.注意这两种情形的处理实质不同:情形⑵是在利用当前结点的后验分布,而情形⑶则是把父结点的样本分布作为当前结点的先验分布. 基本算法 由算法4 .2可看出,决策树学习

《西瓜书》第六章 公式6.6 凸二次规划问题
1. 凸优化问题 对于一般的非线性规划,若目标函数是凸函数,约束集合 D D D 是凸集,则称该非线性规划是凸规划。 若上述约束规划中只含有不等式约束,又 c i ( x ) ( i ∈ I ) c_i(x)(i∈I) ci(x)(i∈I)是凸函数,则约束集 D D D 是凸集。 对于混合约束问题,若 c i ( x ) ( i ∈ E ) c_i(x)(i∈E) ci(x)(i∈E

《西瓜书》第六章 SVM支持向量机 笔记
文章目录 6.1 间隔与支持向量6.1.1 超平面6.1.2 支持向量6.1.3 间隔6.1.4 最大间隔 6.2 对偶问题6.2.1 凸二次规划6.2.2 对偶问题6.2.3 支持向量机的一个重要性质 6.3 核函数6.3.1 支持向量展开式6.3.2 核函数定理6.3.3 常用的核函数6.3.4 核函数特点 6.4 软间隔与正则化6.4.1 硬间隔6.4.2 软间隔6.4.3 替代损失6

《西瓜书》第四章 决策树 笔记
文章目录 4.1 基本流程4.1.1 组成4.1.2 目的4.1.3 策略4.1.4 算法 4.2 划分选择4.2.1信息增益-ID3决策树4.2.1.1 信息熵4.2.1.1 信息增益 4.2.2 增益率-C4.5决策树4.2.3 基尼指数-CART决策树4.2.3.1 基尼值4.2.3.2 基尼指数 4.3 剪枝处理4.3.1 预剪枝4.3.2 后剪枝 4.4 连续与缺失值4.4.1

《西瓜书》第三章 线性模型 手写版笔记
《西瓜书》第三章 线性模型 手写版笔记 文章目录 《西瓜书》第三章 线性模型 手写版笔记3.0 知识点总览3.1 线性回归(Linear Regression)求解的推导过程3.1.1 单变量线性回归3.1.2 多变量线性回归3.1.3 对数线性回归 3.2 逻辑回归(Logistic Regression)3.3 线性判别(LDA)3.4 多分类学习的拆分策略3.5 处理类别不平衡问题三

机器学习西瓜书笔记(九) 第九章聚类+代码
第九章 第九章聚类9.1 聚类任务小结 9.2 性能度量小结 9.3 距离计算小结 9.4 原型聚类9.4.1 k均值算法9.4.2 学习向量量化9.4.3 高斯混合聚类小结 9.5 密度聚类小结 9.6 层次聚类小结 代码K-means层次聚类DBSCAN 总结 第九章聚类 9.1 聚类任务 在"无监督学习"中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来

机器学习西瓜书笔记(八) 第八章集成学习+代码
第八章 第8章集成学习8.1 个体与集成小结个体学习(Individual Learning)集成学习(Ensemble Learning)比较 8.2 Boosting小结 8.3 Bagging与随机森林8.3.1 Bagging8.3.2随机森林小结 8.4 结合策略8.4.1 平均法8.4.2 投票法8.4.3 学习法小结 8.5多样性8.5.1 误差-分歧分解8.5.2 多样性度量
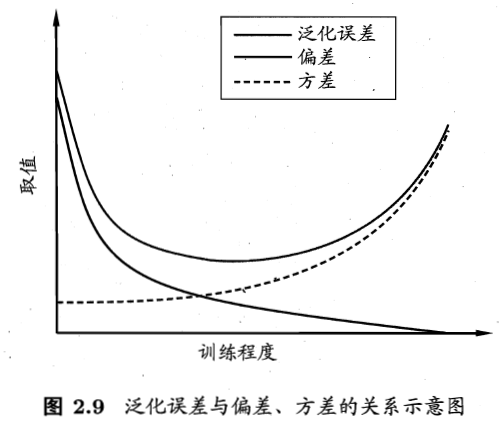
【机器学习】西瓜书第二章——模型评估与选择
参考资料:[1]周志华.机器学习[M].清华大学出版社,2016. 一、经验误差与过拟合 通常我们把分类错误的样本数占样本总数的比例称为“错误率”(erroe rate),即如果在 m m m 个样本中有 a a a 个样本分类错误,则错误率 E = a / m E=a/m E=a/m;相应地, 1 − a / m 1-a/m 1−a/m 称为“精度”(accuracy)。 更一般地,


【西瓜书】第一二章笔记
耽于学业,选择速记,后续再补。本笔记质量不高,敬请谅解。 关键词: 监督学习(Supervised Learning):一种机器学习范式,其中模型在带有标签的数据集上进行训练。标签提供了正确的答案,算法通过对比预测结果与实际标签,调整模型参数以最小化误差。监督学习主要包括分类和回归两种任务。 模型(Model):在机器学习中,模型是用来表示输入数据与输出结果之间关系的数学结构。模型可

东明第19届西瓜节背后的秘密
中共东明县委书记孙迁国致辞 6月16日,随着华灯初上,东明县小井镇沉浸在一片欢乐祥和的氛围中。备受瞩目的第十九届西瓜节在这里盛大开幕,数万观众汇聚一堂,共同见证了东明县以西瓜为纽带,连接传统与现代、文化与经济的甜蜜盛事。 开幕式现场气氛热烈而喜庆。活动邀请了众多知名歌手演员,其中梦然、甘苹和周晓鸥等艺人的精彩表演赢得了观众的阵阵掌声和喝彩声。相声、舞蹈、戏曲等多

类别朴素贝叶斯CategoricalNB和西瓜数据集
CategoricalNB 1 CategoricalNB原理以及用法2 数据集2.1 西瓜数据集2.2 LabelEncoder2.3 OrdinalEncoder 3 代码实现 1 CategoricalNB原理以及用法 (1)具体原理 具体原理可看:贝叶斯分类器原理 sklearn之CategoricalNB对条件概率的原理如下: P ( x i = k ∣ y ) =

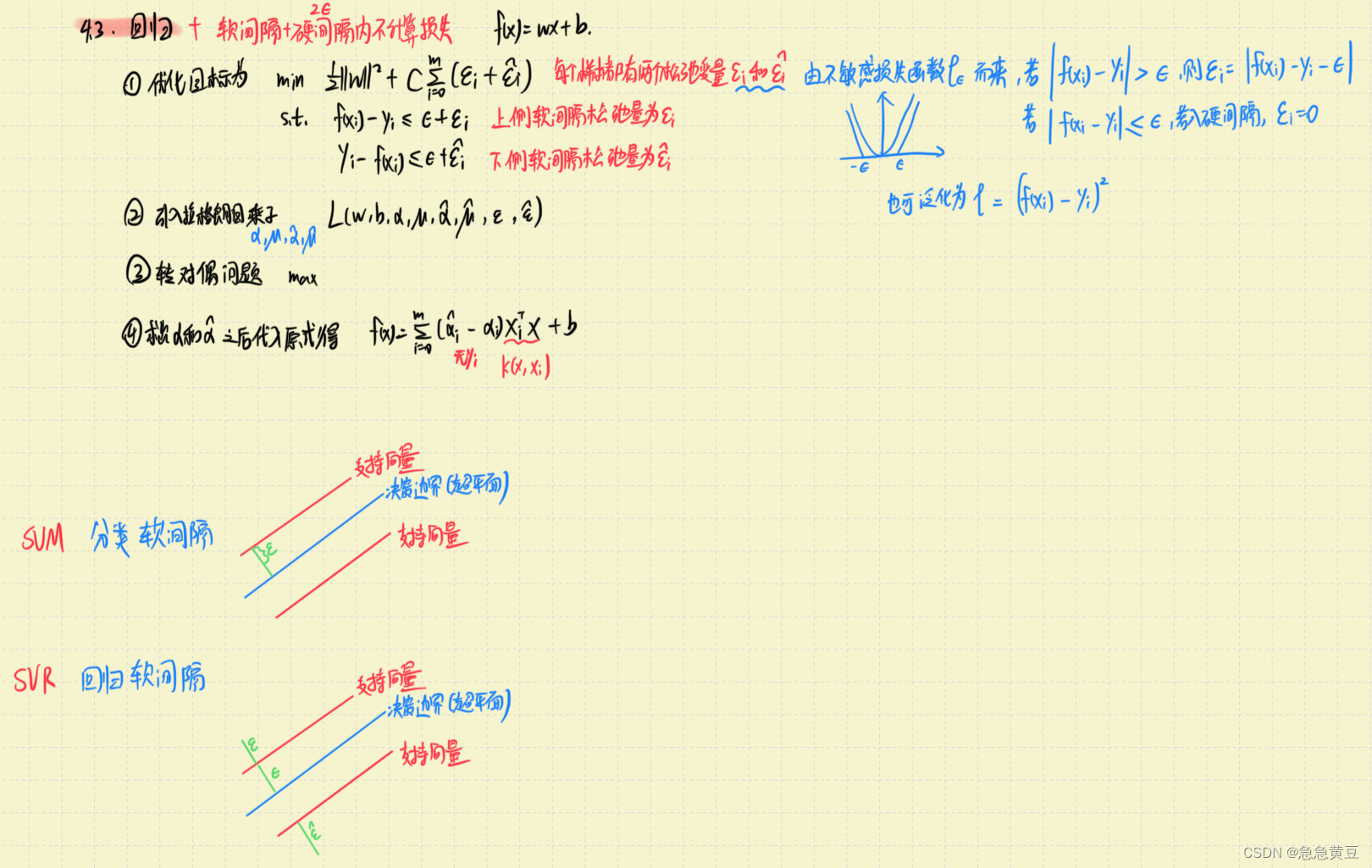
【西瓜书】6.支持向量机
目录: 1.分类问题SVM 1.1.线性可分 1.2.非线性可分——核函数 2.回归问题SVR 3.软间隔——松弛变量 3.1.分类问题:0/1损失函数、hinge损失、指数损失、对率损失 3.2.回归问题:不敏感损失函数、平方 4.正则化
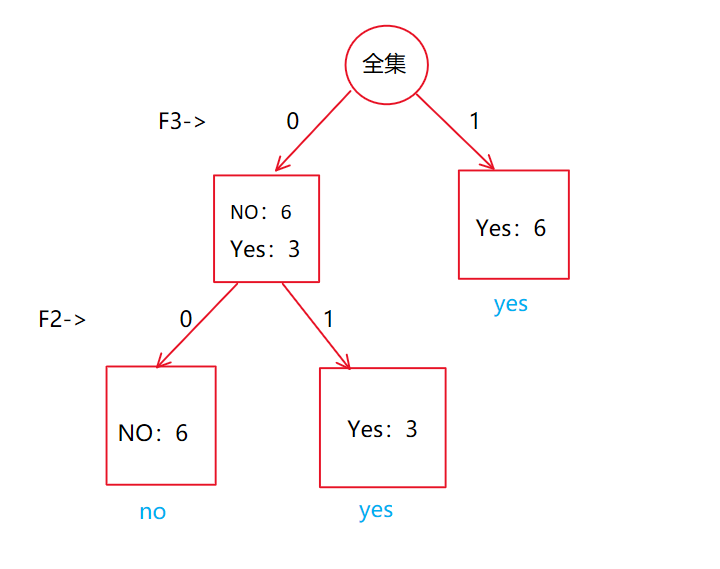
西瓜书总结——决策树原理+ID3决策树的模拟实现
西瓜书总结——决策树原理+ID3决策树的模拟实现 前言1. 决策树结构2. 决策树的生成(注意区分属性和类别)3. 划分选择3.1 信息熵和信息增益3.2 增益率3.3 基尼指数(鸡你指数) 4. 剪枝处理4.1 预剪枝4.2 后剪枝 5. 连续值与缺失值处理5.1 连续值处理5.2 缺失值处理 6. 模拟实现ID3决策树7. ID3决策树完整代码8. 添加缺失值处理功能的ID3决策树
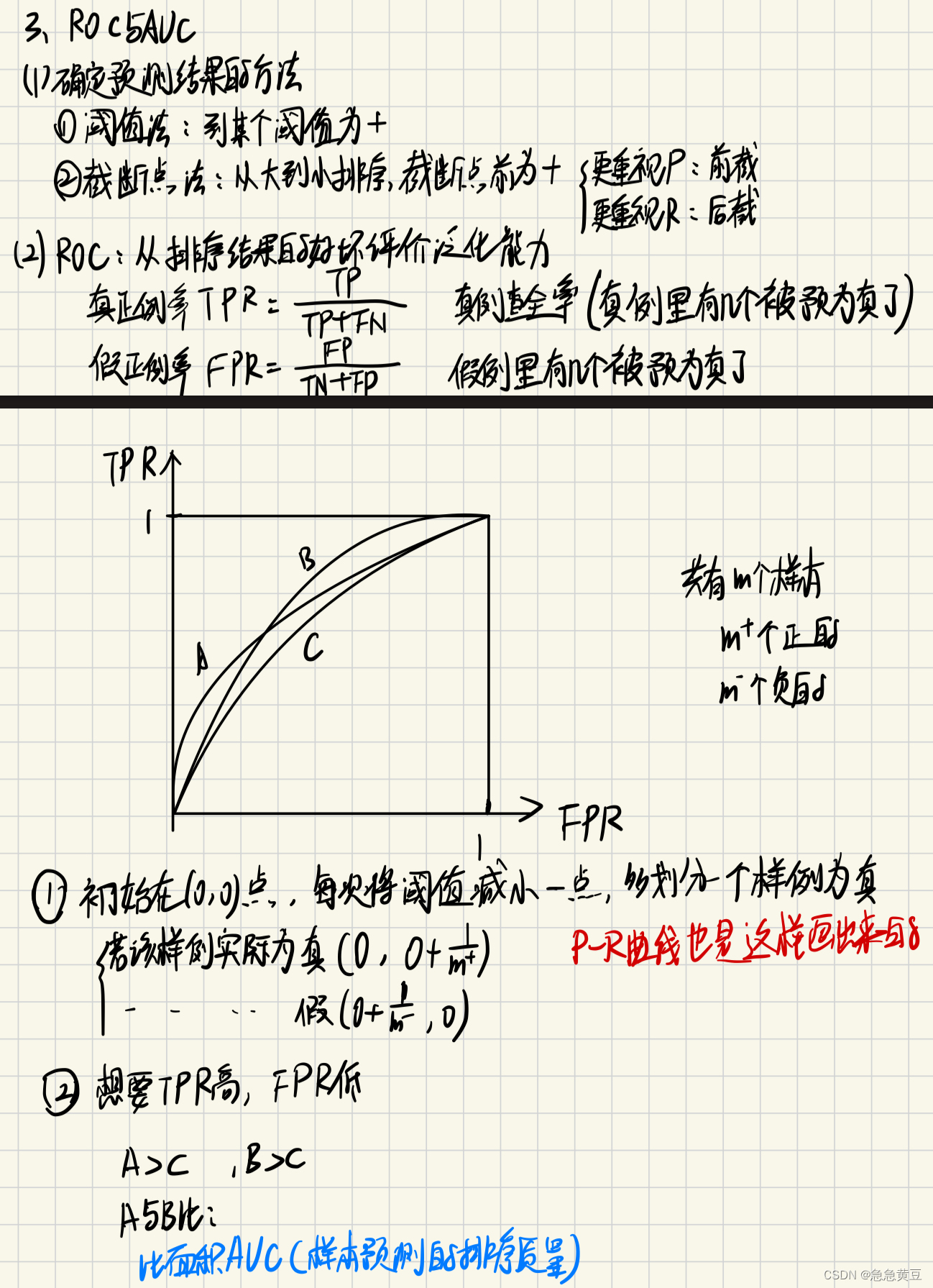
【西瓜书】2.模型评估与选择
1.经验误差与过拟合 (1)错误率、精度 (2)误差:训练误差/经验误差、泛化误差 (3)过拟合、欠拟合 欠拟合好克服,过拟合无法彻底避免 2.三大任务——评估方法 泛化误差的评估方法,即将测试误差作为泛化误差的近似 注意:测试样本不要出现在训练集中 对于一个数据集,划分为训练集和测试集,方法如下: (1)留出法: 分层采样(保留

【西瓜书】5.神经网络
1.概念 有监督学习正向传播:输入样本---输入层---各隐层---输出层反向传播:误差以某种形式在通过隐层向输入层逐层反转,并将误差分摊给各层的所有单元,以用于修正各层的权值激活函数:也叫阶跃函数,目的是引入非线性因素,有很多种激活函数,如sigmoid,relu,使用情景如下 激活函数作用:如果没有激活函数,则不管有几个隐藏层,都只能表示线性切割,即与单层神经网络相同,而通过使用激活函

西瓜播放器xgplayer设置自动播放踩坑
上图是官网(西瓜视频播放器官方中文文档)的介绍,相信大家都是按照官网配置去做的,但是并没有什么用,插件很好用,但是属性不全,真的很悔恨,找遍 api 都没有找到自动播放的属性!!最终看了大佬的文章发现了autoplayMuted属性 'autoplayMuted':true, 允许自动播放 设置了这一属性,立马生效,都不需要什么 autoplay

机器学习-利用信息熵来学习如果分辨好西瓜
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。 我们通常用Entropy(信息熵来度量划分的凌乱程度)。 Ent(D)越小,则信息熵的复杂程度越低,D的纯度(一

Qt 之图形(简笔画-绘制漂亮的西瓜)
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 Summer is coming…我们呢,为大家准备了丰盛的佳果-西瓜,清爽解渴,甘味多汁。 一笔一划学简笔画,分分钟让你掌握一门新技能,下面我们来绘制一个“盛夏之王”-西瓜,赶快一起来试试吧。 简笔画 我们先简单看看西瓜的基本组成,一步步进行拆分、组合。 绘制 效果 具体的效果如下所示,我们可以
【西瓜书机器学习】第五章 神经网络
一起啃西瓜书(5)-神经网络《机器学习-周志华》 - 知乎 (zhihu.com)参考进行自我复习整理,侵删! 1、神经元模型 神经网络定义:神经网络是由 具有适应性 的 简单单元 组成的广泛 并行互连 的网络。M-P神经元模型:输入、处理、输出 第二步超过阈值则兴奋(做出反应),否则不兴奋(没反应) ,通过f(x)阶跃函数实现,但阶跃函数不连续,使用sigmo
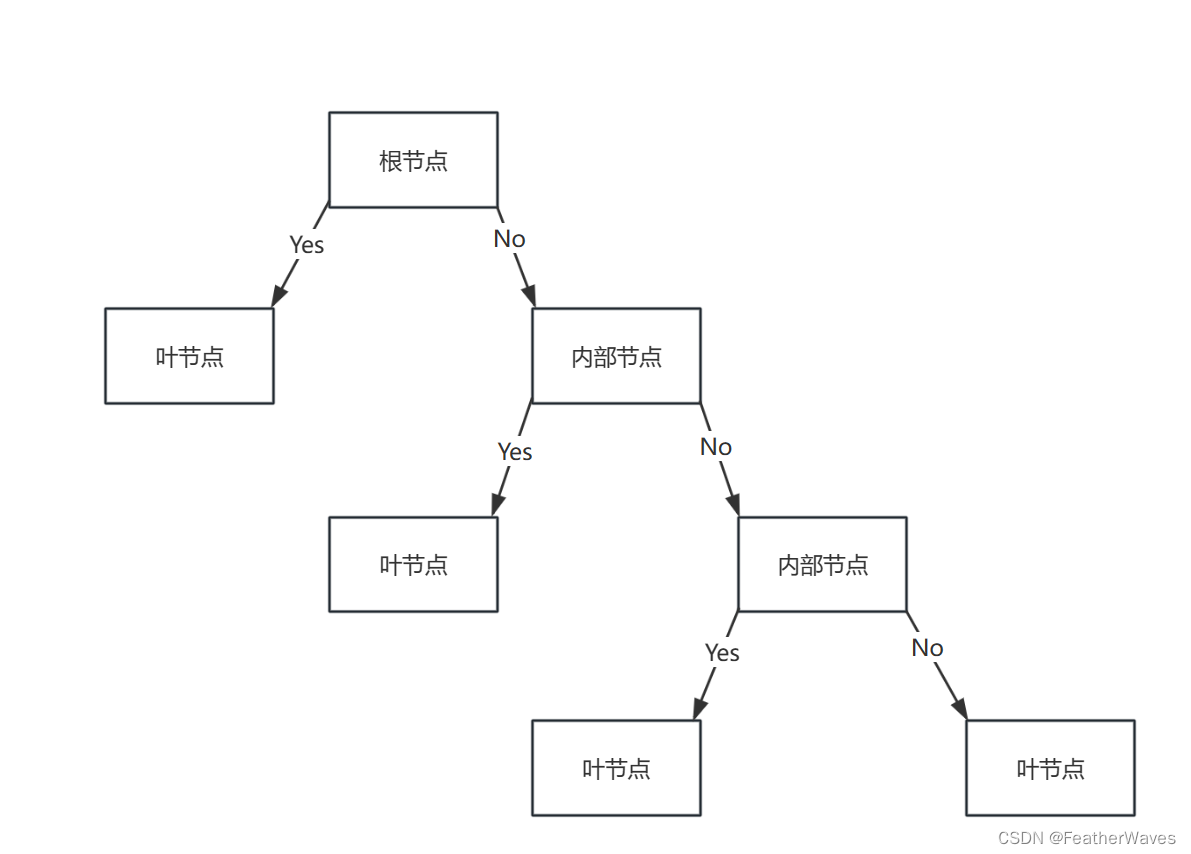
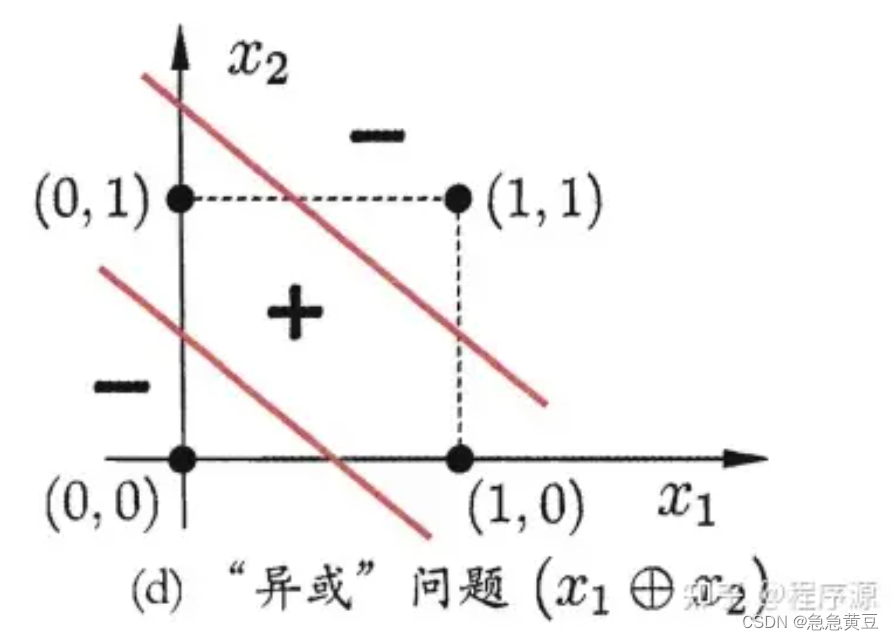
西瓜书学习——决策树形状、熵和决策树的本质
文章目录 决策树形状监督学习算法分类与回归 熵信息熵香农熵 (Shannon Entropy) - H(X)联合熵 (Joint Entropy) - H(X, Y)条件熵 (Conditional Entropy) - H(Y|X)互信息 (Mutual Information) - I(X; Y)相对熵 (Relative Entropy) / KL散度 (Kullback-Leible
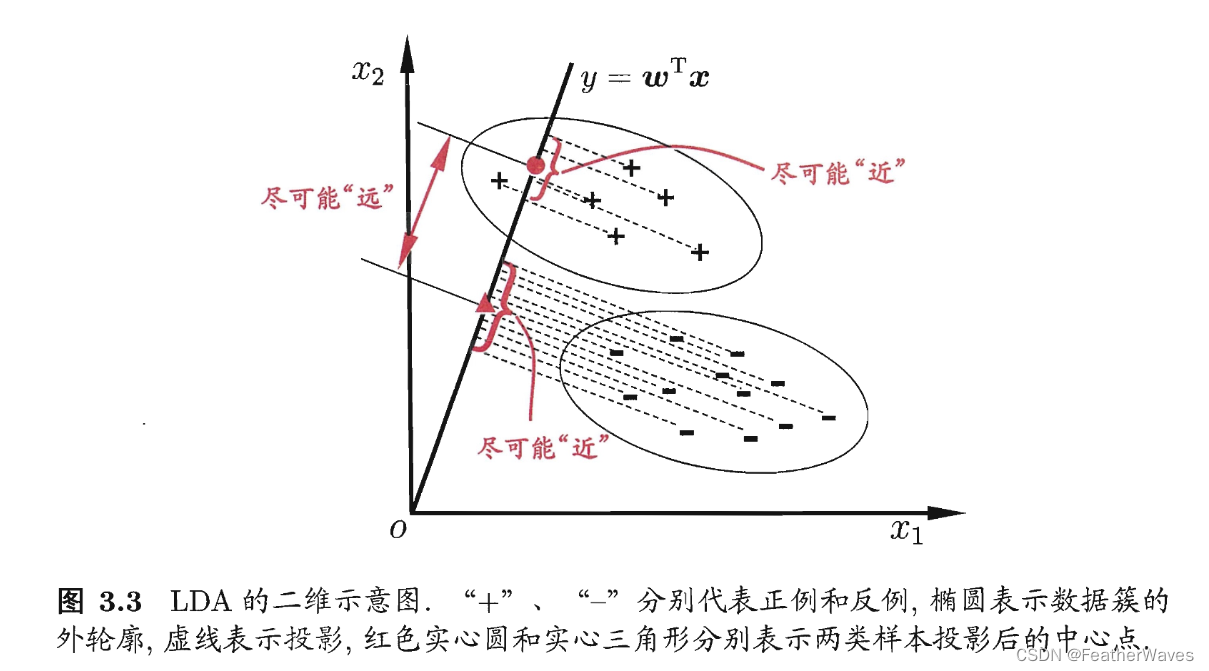
西瓜书学习——线性判别分析
文章目录 定义LDA的具体步骤1. 计算类内散布矩阵(Within-Class Scatter Matrix)2. 计算类间散布矩阵(Between-Class Scatter Matrix)3. 求解最佳投影向量4. 数据投影5. 分类 定义 线性判别分析(Linear Discriminant Analysis,简称LDA)是一种常用的监督学习降维技术,主要应用于模式识别和

西瓜书学习——对数几率回归
对数几率回归(Logistic Regression)是一种广泛应用于分类问题的统计方法,特别是用于二分类问题。尽管它的名字中包含“回归”,但它实际上是一种分类算法,用于估计一个样本属于某个类别的概率。 对数几率回归的核心是使用逻辑函数(Logistic Function),也称为 sigmoid 函数,将线性回归的输出映射到 0 和 1 之间的概率。sigmoid 函数定义为: S ( x

隐马尔可夫模型(HMM)硬啃西瓜书
隐马尔可夫模型(HMM) 好吧隐马尔可夫模型出现的次数实在有点多;今天来讲讲吧 先来四个概念: 可见状态链 观测结果隐含状态链 产生结果的实体类型转换概率 相邻实体之间转换的概率输出概率 实体输出结果的概率 两个基本假设: 1) 齐次马尔科夫链假设。即任意时刻的隐藏状态只依赖于它前一个隐藏状态。 2) 观测独立性假设;实体输出结果的概率完全独立 本来说的是参考几篇文章来写,t