本文主要是介绍【西瓜书】2.模型评估与选择,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.经验误差与过拟合
(1)错误率、精度
(2)误差:训练误差/经验误差、泛化误差
(3)过拟合、欠拟合
欠拟合好克服,过拟合无法彻底避免
2.三大任务——评估方法
泛化误差的评估方法,即将测试误差作为泛化误差的近似
注意:测试样本不要出现在训练集中
对于一个数据集,划分为训练集和测试集,方法如下:
(1)留出法:
- 分层采样(保留类别比例)
- 划分不同结果差别很大,所以随机划分若干次如100次,每次获得一个测试评估结果,取100次的平均值。
- 划分比例:若训练集大,评估结果稳定性差;若测试集大,评估结果的保真性差。一般留出1/5~3/1用于测试。
(2)交叉验证法:
- 数据集划分为k组,每组用k-1个子集训练,剩余1个子集进行测试,也就是每个子集都被作为过k-1次训练集,作为过1次测试集,得到k个测试结果,返回均值。叫做K折交叉验证
- k的取值决定了评估的稳定性和保真性
- 不同的划分重复p次,取p次k折交叉验证结果的均值
- 特例:若数据集中有m个样例,当k=m则称为留一法
- 不受随机样本划分方式影响,且评估结果往往比较准确(注意是往往,但没有免费的午餐 )
- 当数据集较大时,训练开销太大
(3)自助法:
- 有放回的采样:有放回的采样m个样本放入D‘,有些样本可能在D'中出现多次,D'作为训练集。而约有36.8%的样本没在D'中出现过,这些样本作为测试集。
- 适用于数据集小难以划分的情况。
- 会引入估计偏差,如果数据量足够还是使用留出法和交叉验证法好一些。
(4)调参与最终模型
- 参数:算法参数(超参数)、模型参数(如迭代次数)
- 参数选择:选择范围和步长,得到的不是最优的
- 1.模型评估:从训练集中划分验证集;2.实际使用:测试集
- 验证集:进行超参数调优(如学习率、批次大小、迭代次数等)、模型选择(例如,选择神经网络中的层数和神经元数量)
- 测试集:评估最终模型的性能,确保模型在未知数据上的泛化能力

3.三大任务——性能度量
性能度量是评估模型泛化能力的标准
3.1.回归任务:均方误差
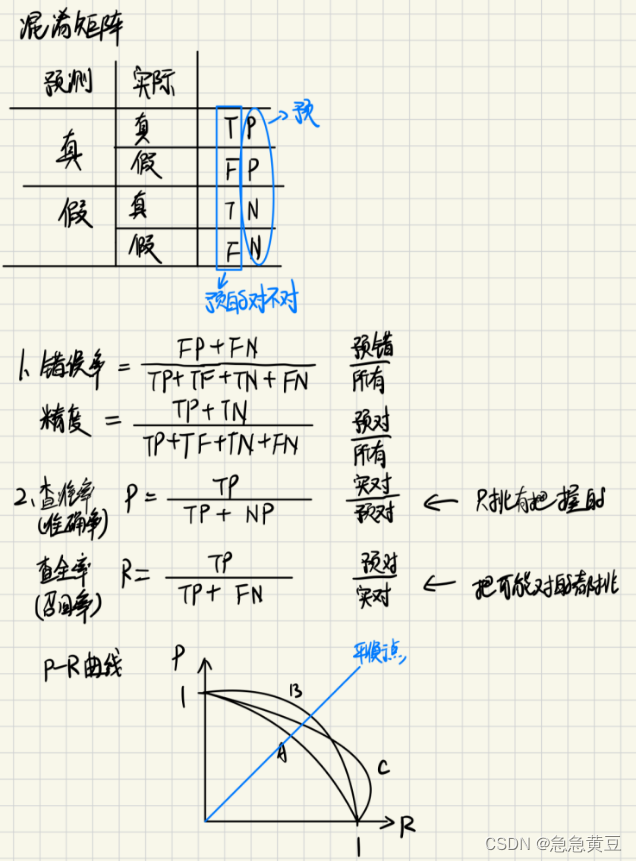
3.2.分类任务:错误率与精度(关心查的有几个是对的)
3.3.分类任务:查准率/准确率P、查全率/召回率R (关心查出来的有多少比例是好的)
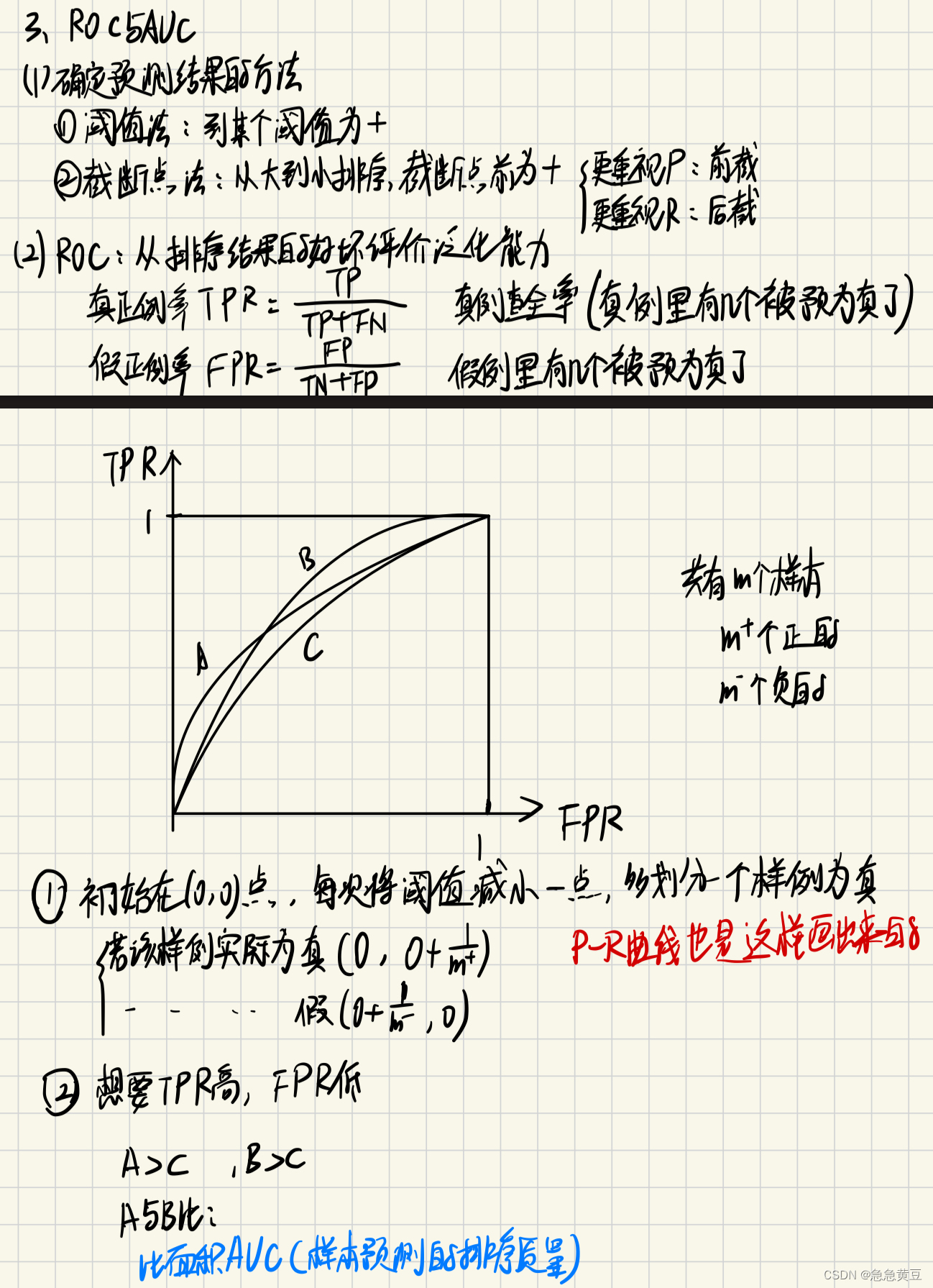
3.4.ROC和AUC

4.三大任务——比较检验
这篇关于【西瓜书】2.模型评估与选择的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







