本文主要是介绍【西瓜书】9.聚类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 聚类任务是无监督学习的一种
- 用于分类等其他任务的前驱过程,作为数据清洗,基于聚类结果训练分类模型
1.聚类性能度量(有效性指标)
- 分类任务的性能度量有错误率、精度、准确率P、召回率R、F1度量(P-R的调和平均)、TPR、FPR、AUC
- 回归任务的性能度量有均方误差MSE、根均方误差RMSE、平均绝对误差MAE、R-Squared
- 聚类任务的性能度量分为三个外部指标+两个内部指标
外部指标:和一个参考模型比
若对m个样本聚类,分成了k个簇,两两样本比较,可组为m(m-1)/2组,每组要么位于相同簇(1)要么位于不同簇(0),对参考模型做同样操作,我们希望两个模型对于m(m-1)/2组样本组合划分的结果都为1或都为0的尽可能多,则分为如下三个外部指标(都是越大越好):
- Jaccard系数:JC=a/(a+b+c)(在两个模型中都为同一个簇的尽可能多)
- FM指数:FMI=sqrt(a/(a+b)+a/(a+c))
- Rand指数:RI=(a+d)/(a+b+c+d)(在两个模型中都为同一个簇或都不为同一个簇的尽可能多)
内部指标:内部簇间距离大,簇内距离小
- DB指数:越小越好
- Dumn指数:越大越好
2.距离计算
2.1.连续属性:具有非负性、直递性、对称性、同一性
计算闵可夫斯基距离:
- 曼哈顿距离:绝对值相加
- 欧氏距离:绝对值平方相加开根号
2.2.离散属性: VDM法(没太理解不确定)

3.原型聚类
3.1.k-means
3.2.DBSCAN密度聚类
由核心对象出发,找到与该核心对象密度可达的所有样本形成一个聚类簇。
(1)概念:邻域参数 eps (每个点的方圆eps内有几个样本)和 Minpts(eps的一个分界点)
(2)样本点之间的三种关系:
密度可达和密度相连区别在于方向不同:
- x1—>x2—>x3的x1到x3是密度可达
- x1<—x2—>x3的x1和x3是密度相连
其中密度可达是不一定对称的,密度相连是对称的,如下题目:
x1到x2直接密度可达;x1到x3密度可达;x3与x4密度相连(通过x1)
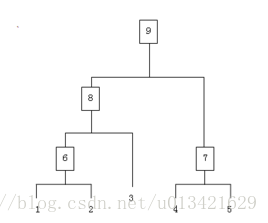
3.3.AGNES层次聚类
自底向上聚合的层次聚类算法,它先会将数据集中的每个样本看作一个初始簇,然后在算法运行的每一步中找出距离最近的两个簇进行合并,直至达到预设的簇的数量。





这篇关于【西瓜书】9.聚类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!