聚类专题

线性代数|机器学习-P36在图中找聚类
文章目录 1. 常见图结构2. 谱聚类 感觉后面几节课的内容跨越太大,需要补充太多的知识点,教授讲得内容跨越较大,一般一节课的内容是书本上的一章节内容,所以看视频比较吃力,需要先预习课本内容后才能够很好的理解教授讲解的知识点。 1. 常见图结构 假设我们有如下图结构: Adjacency Matrix:行和列表示的是节点的位置,A[i,j]表示的第 i 个节点和第 j 个

Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering)
Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering) Power Iteration Clustering (PIC) 是一种基于图的聚类算法,用于在大规模数据集上进行高效的社区检测。PIC 算法的核心思想是通过迭代图的幂运算来发现数据中的潜在簇。该算法适用于处理大规模图数据,特别是在社交网络分析、推荐系统和生物信息学等领域具有广泛应用。Spa

用Pytho解决分类问题_DBSCAN聚类算法模板
一:DBSCAN聚类算法的介绍 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,DBSCAN算法的核心思想是将具有足够高密度的区域划分为簇,并能够在具有噪声的空间数据库中发现任意形状的簇。 DBSCAN算法的主要特点包括: 1. 基于密度的聚类:DBSCAN算法通过识别被低密
Spark2.x 入门: KMeans 聚类算法
一 KMeans简介 KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。 ML包下的KMeans方法位于org.apache.spark.ml.clustering包下,其过程大致如下: 1.根据给定的k值,选取k个样本点作为初始划分中心;2.计算所有样本点到每
【ML--13】聚类--层次聚类
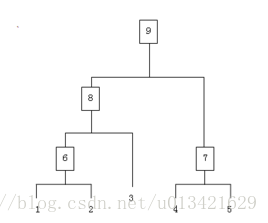
一、基本概念 层次聚类不需要指定聚类的数目,首先它是将数据中的每个实例看作一个类,然后将最相似的两个类合并,该过程迭代计算只到剩下一个类为止,类由两个子类构成,每个子类又由更小的两个子类构成。 层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足或者达到最大迭代次数。具体又可分为: 凝聚的层次聚类(AGNES算法):一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来

第L8周:机器学习|K-means聚类算法
本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 | 接辅导、项目定制 🚀 文章来源:K同学的学习圈子深度学习 聚类算法的定义: 聚类就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。“相似”这一概念,是利用距离标准来衡量的,我们通过计算对象与对象之间的距离远近来判断它们是否属于同一类别,即是否是同一个簇。 聚类是

自然语言处理系列五十三》文本聚类算法》文本聚类介绍及相关算法
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列五十三文本聚类算法》文本聚类介绍及相关算法K-means文本聚类算法原理 总结 自然语言处理系列五十三 文本聚类算法》文本聚类介绍及相关算法 分类和聚类都是文本挖掘中常使用的方法,他们的目的都是将相

Python计算机视觉编程——第六章 图像聚类
目录 1 K-means聚类1.1 Scipy聚类包1.2 图像聚类1.3 在主成分上可视化图像1.4 像素聚类 2 层次聚类3 谱聚类 聚类可以用于识别,划分图像数据集,组织与导航。 1 K-means聚类 K-means是一种将输入数据划分为k个簇的简单的聚类算法。步骤如下: (1) 以随机或猜测的方式初始化类中心 u i , i = 1 ⋯ k ; u_i,i=1\cd

Python计算机视觉第六章-图像聚类
目录 6.1 K-means聚类 6.1.1 SciPy聚类包 6.1.2 图像聚类 6.1.3 在主成分上可视化图像 6.1.4 像素聚类 6.2 层次聚类 6.3 谱聚类 6.1 K-means聚类 K-means 是一种将输入数据划分成 k 个簇的简单的聚类算法。K-means 反复提炼初 始评估的类中心,步骤如下: (1) 以随机或猜测

基于Python的机器学习系列(20):Mini-Batch K均值聚类
简介 K均值聚类(K-Means Clustering)是一种经典的无监督学习算法,但在处理大规模数据集时,计算成本较高。为了解决这一问题,Mini-Batch K均值聚类应运而生。Mini-Batch K均值聚类通过使用数据的子集(mini-batch)来更新簇中心,从而减少了计算量,加快了处理速度。 Mini-Batch K均值算法 Mini-Batch
开放题:如何利用深度学习来重参数化 K-means 聚类,这样的思路要做出效果,它的前向传播、反向传播以及优化目标最好是什么样的?
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 传统的 K-means 算法直接处理数据点与聚类中心。重参数化技术的核心在于利用神经网络来学习一个从输入空间映射到聚类分配的转换函数。深度学习重参数化 K-means 聚类的核心思想在于,将传统 K-means 算法中的硬分配机制转化为可微分的软分配,进而利用神经网络学习并优化特征表示。此方法巧妙融合了

neural-admixture:基于AI的快速基因组聚类
最近学习祖源分析方面的内容,发现已经有了GPU版的软件,可以几十倍地加快运算速度,推荐使用!小数据集的话家用显卡即可hold住,十分给力! ADMIXTURE 是常用的群体遗传学分析工具,可以估计个体的祖先成分。使用neural-admixture 可以将一个月的连续计算时间缩短到几个小时。多头方法允许神经 ADMIXTURE 通过在单个集群中计算多个集群数来进一步加速 在一次运行中计算多个集群数

机器学习西瓜书笔记(九) 第九章聚类+代码
第九章 第九章聚类9.1 聚类任务小结 9.2 性能度量小结 9.3 距离计算小结 9.4 原型聚类9.4.1 k均值算法9.4.2 学习向量量化9.4.3 高斯混合聚类小结 9.5 密度聚类小结 9.6 层次聚类小结 代码K-means层次聚类DBSCAN 总结 第九章聚类 9.1 聚类任务 在"无监督学习"中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来

基于Python的机器学习系列(19):K均值聚类(K-Means Clustering)
简介 K均值聚类(K-Means Clustering)是一种常用的无监督学习算法,用于将数据样本划分为若干个“簇”,使得同一簇内的数据点彼此相似,而不同簇的数据点之间差异较大。由于K均值不依赖于标签,因此它是一种无监督学习方法。常见的应用包括客户细分、图像分割和数据可视化等。 K均值算法 K均值算法的基本步骤如下: 定义簇的数量 k(需手动设定)。初始化簇的质心,这些质心

各种聚类算法介绍和比较
各种聚类算法介绍和比较 一、简要介绍 1、聚类概念 聚类就是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。 2、聚类和分类的区别 聚类技术通常又被称为无监督学习,因为与监

sheng的学习笔记-AI-半监督聚类
AI目录:sheng的学习笔记-AI目录-CSDN博客 半监督学习:sheng的学习笔记-AI-半监督学习-CSDN博客 聚类:sheng的学习笔记-AI-聚类(Clustering)-CSDN博客 均值算法:sheng的学习笔记-AI-K均值算法_k均值算法怎么算迭代两次后的最大值-CSDN博客 什么是半监督聚类 聚类是一种典型的无监督学习任务,然而在现实聚类任务中我们往往能获得

Python计算机视觉 第6章-图像聚类
Python计算机视觉 第6章-图像聚类 6.1 K-means聚类 K-means 聚类 是一种常用的无监督学习算法,用于将数据集划分为 ( K ) 个簇。 算法步骤 选择 ( K ) 个初始簇中心(可以是随机选择或其他启发式方法)。将每个数据点分配到距离其最近的簇中心所属的簇。计算每个簇的新簇中心,通常是簇中所有点的均值。重复步骤 2 和 3,直到簇中心不再改变或达到预设的迭代次数。
从K-Means到K-Medoid:聚类算法在缺陷报告分析中的性能比拼与优化探索
本文分享自华为云社区《聚类:k-Means 和 k-Medoid》作者: Uncle_Tom 1. 前言 在《对静态分析缺陷报告进行聚类,以降低维护成本》 提到使用 k-Medoid 通过相似缺陷的聚类,来减少程序员对大量缺陷分析的工作量。 k-Medoid 和传统的 k-Means 聚类算法有什么差别呢? 简单的说,K-Medoid 算法是一种基于 K-Means 算法的聚类方法,它
Python 点云K-means聚类算法
一、概述 K-means聚类算法(Intrinsic Shape Signatures):是一种无监督学习算法,主要用于数据聚类。该算法的主要目标是找到一个数据点的划分,使得每个数据点与其所在簇的质心(即该簇所有数据点的均值)之间的平方距离之和最小。 基本思想: 首先需要预定义簇的数量K,然后随机选择K个对象作为初始的聚类中心。算法会遍历数据集中的每个对象,根据对象与各个聚类中心的距离,将每个

【机器学习】(5.4)聚类--密度聚类(DBSCAN、MDCA)
1. 密度聚类方法 2. DBSCAN DBSCAN(Density-Based Spatial Clustering of Applications with Noise)。一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为 密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有“噪声”的数据中发现任意形状的聚类。 2.1 DBSCAN算

【机器学习】(5.3)聚类--层次聚类
无监督模型。 聚类算法需要度量样本间的距离,距离度量的方式可以参考【机器学习】(5)聚类--距离度量_mjiansun的博客-CSDN博客 一般会使用欧氏距离。 起步 层次聚类( Hierarchical Clustering )是聚类算法的一种,通过计算不同类别的相似度类创建一个有层次的嵌套的树。(分为凝聚的和分裂的两种方式,常用的方式是凝聚的方式) 层次聚类算法介绍 假设有

【机器学习】(5.2)聚类--Kmeans
无监督模型。 聚类算法需要度量样本间的距离,距离度量的方式可以参考【机器学习】(5)聚类--距离度量_mjiansun的博客-CSDN博客 一般会使用欧氏距离。 1. K-means 1.1 基本思想 1.2 算法步骤 注意点与思考: 1. 初始值该怎么选择? 共有如下几种选择方式: (1)根据人的先验知识得到K个初始值,比如男女身高,假定男性身高175cm,女性165cm
模糊C均值聚类算法及实现
模糊C均值聚类算法的实现 研究背景 https://blog.csdn.net/liu_xiao_cheng/article/details/50471981 聚类分析是多元统计分析的一种,也是无监督模式识别的一个重要分支,在模式分类 图像处理和模糊规则处理等众多领域中获得最广泛的应用。它把一个没有类别标记的样本按照某种准则划分为若干子集,使相似的样本尽可能归于一类,而把不相似的样本划