moe专题
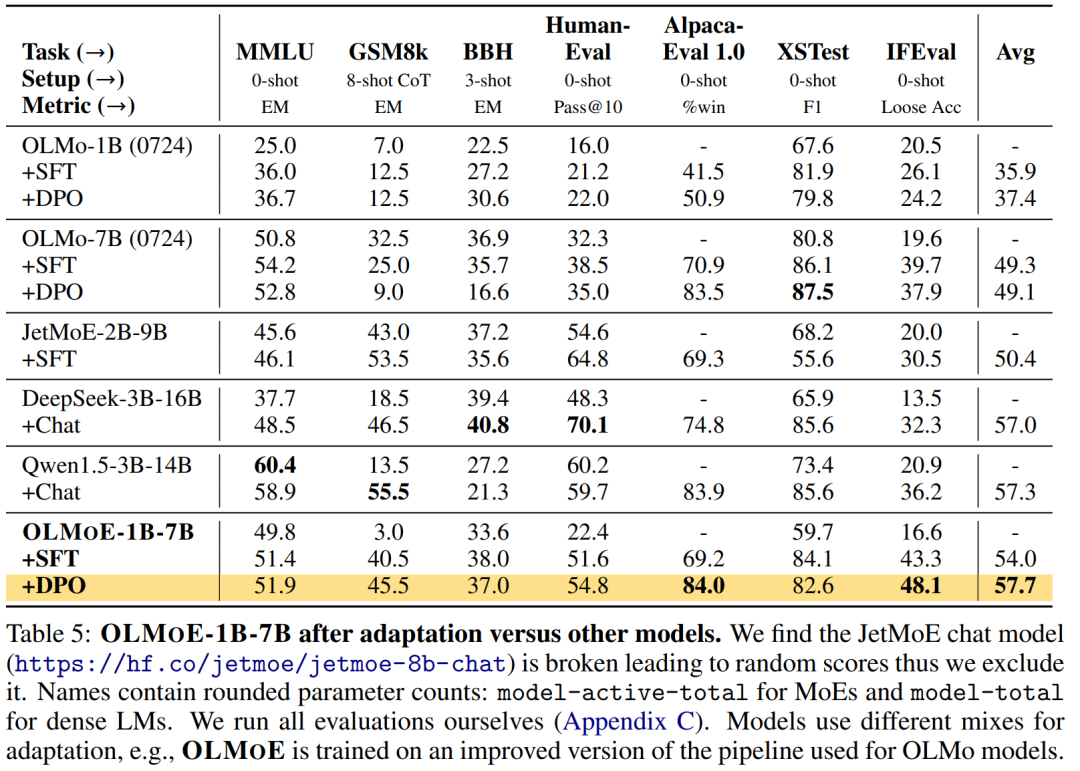
第一个100%开源的MoE大模型,7B的参数,1B的推理成本
尽管大语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。 对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建和部署成本过高。改善成本 - 性能的一种方法是使用稀疏激活混合专家 (MoE)。MoE 在每一层都有几个专家,每次只激活其中的一个子集(参见图 2)。这使得 MoE 比具有相似参数量的密集模型更有效,因为密集模型为每个

最强MoE完全开源模型发布啦~
这篇文章介绍了OLMOE(Open Mixture-of-Experts Language Models)系列模型,这是一款开源的稀疏混合专家模型。OLMOE-1B-7B拥有70亿参数,但每个输入令牌仅使用10亿参数。该模型在5万亿令牌上进行预训练,并进一步适应以创建OLMOE-1B-7B-INSTRUCT。这些模型在相似活跃参数的模型中表现最佳,甚至超越了更大的模型,如Llama2-13B-

推动专家混合模型的极限:用于指令调优的极端参数高效MoE
人工智能咨询培训老师叶梓 转载标明出处 MoE是一种在特定子任务上具有专门化子模型(专家)的神经网络架构,这些子模型可以独立优化,以提高整体性能。然而,传统的MoE在大规模应用时面临挑战,因为需要在内存中存储所有专家。这不仅增加了内存的需求,而且在完全微调(full fine-tuning)时计算成本极高。为了克服这些限制,Cohere for AI的研究团队提出了一种极端参数高效的MoE方法。
一文通透DeepSeek-V2(改造Transformer的中文模型):从DeepSeek LLM到DeepSeek-V2的MLA与MoE
前言 成就本文有以下三个因素 24年5.17日,我在我司一课程「大模型与多模态论文100篇」里问道:大家希望我们还讲哪些论文 一学员朋友小栗说:幻方发布的deepseek-v224年5.24日,我司一课程「大模型项目开发线上营1」里的一学员朋友问我:校长最近开始搞deepseek了吗?刚看了论文,没搞懂MLA那块的cache是怎么算的,我总觉得他的效果应该类似MQA才对,但是反馈是挺好的 我当

【大模型理论篇】Mixture of Experts(混合专家模型, MOE)
1. MoE的特点及为什么会出现MoE 1.1 MoE特点 Mixture of Experts(MoE,专家混合)【1】架构是一种神经网络架构,旨在通过有效分配计算负载来扩展模型规模。MoE架构通过在推理和训练过程中仅使用部分“专家”(子模型),优化了资源利用率,从而能够处理复杂任务。 在具体介绍MoE之前,先抛出MoE的一些表现【2】: 与密集模型相

大话MoE混合专家模型
MoE(Mixture of Experts),专家混合,就像是人工智能界的超级团队。想象一下,每个专家都有自己的拿手好戏,比如医疗问题找医生,汽车故障找机械师,做饭找大厨。MoE也是这样,它把难题拆分成小块,交给擅长处理特定问题的专家小组。这样一来,整个团队就能更高效、更精准地搞定各种复杂任务。就像是一群各有所长的专家联手,比单打独斗的通才解决问题的能力要强得多。 让我们看看下面的图表——我们

微软发布 Phi-3.5 系列模型,涵盖端侧、多模态、MOE;字节 Seed-ASR:自动识别多语言丨 RTE 开发者日报
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@SSN,@鲍勃 01 有话题的新闻

![[大模型]XVERSE-MoE-A4.2B Transformers 部署调用](https://img-blog.csdnimg.cn/direct/0ce237e542bd4989bd1e903d7efa40c3.png#pic_center)
[大模型]XVERSE-MoE-A4.2B Transformers 部署调用
XVERSE-MoE-A4.2B介绍 XVERSE-MoE-A4.2B 是由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),使用混合专家模型(MoE,Mixture-of-experts)架构,模型的总参数规模为 258 亿,实际激活的参数量为 42 亿,本次开源的模型为底座模型 XVERSE-MoE-A4.2B,主要特点如下: 模型结构:XVERSE
MoE大模型大火,AI厂商们在新架构上看到了什么样的未来?
文 | 智能相对论 作者 | 陈泊丞 很久以前,在一个遥远的国度里,国王决定建造一座宏伟的宫殿,以展示国家的繁荣和权力。他邀请了全国最著名的建筑师来设计这座宫殿,这个人以其卓越的才能和智慧闻名。 然而,这位建筑师设计的宫殿虽然精美绝伦,却因为过于复杂和精细,以至于在实际施工过程中遇到了重重困难,许多技艺高超的工匠也感到力不从心。 这时,国王手下有三位普通的石匠,他们虽然没有显赫的名

DeepSpeed MoE
MoE概念 模型参数增加很多;计算量没有增加(gating+小FNN,比以前的大FNN计算量要小);收敛速度变快; 效果:PR-MoE > 普通MoE > DenseTransformer MoE模型,可视为Sparse Model,因为每次参与计算的是一部分参数; Expert并行,可以和其他并行方式,同时使用: ep_size指定了MoE进程组大小,一个模型replica的所

Qwen2-MOE-57B-A14B模型结构解读
Qwen2-MOE-57B-A14B模型结构解读 模型代码文件下载 该模型总的参数为57B,激活参数为14B,推理速度比32B的快,而且性能更好。 Qwen2-MOE-57B-A14B模型总体结构 <class 'transformers.models.qwen2_moe.modeling_qwen2_moe.Qwen2MoeForCausalLM'>Qwen2MoeForCausa
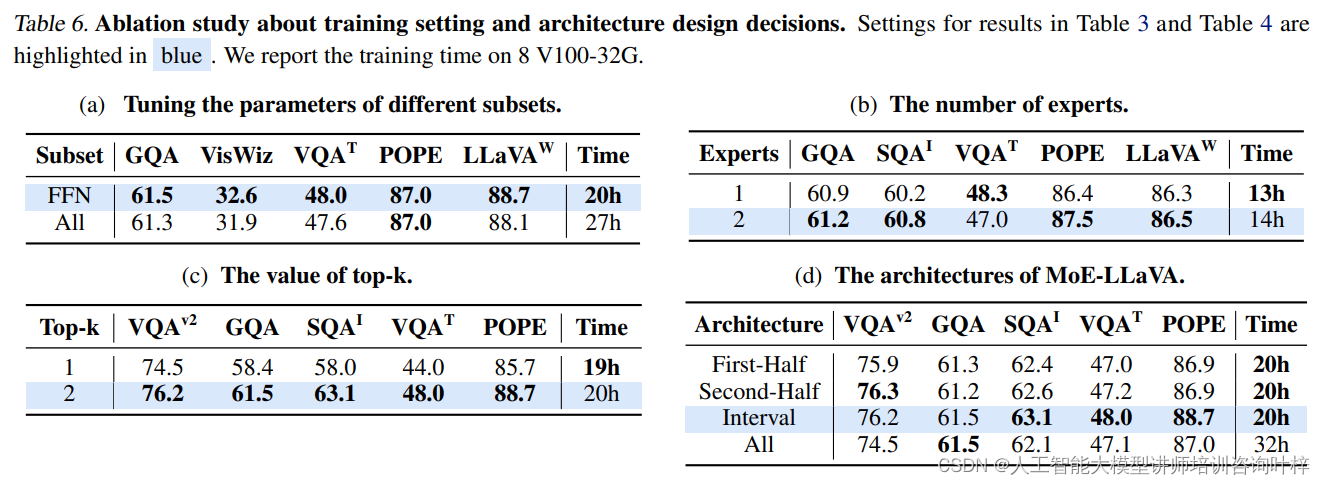
MoE-LLaVA:为大型视觉-语言模型引入专家混合
随着人工智能技术的飞速发展,大型视觉-语言模型(LVLMs)在图像理解和自然语言处理方面展现出了巨大的潜力。这些模型通过结合图像编码器和语言模型,能够处理包括图像描述、视觉问答和图像字幕生成等在内的多种任务。然而,现有模型在训练和推理时存在巨大的计算成本,这限制了它们的应用范围和效率。 方法 为了解决这一挑战,本文提出了一种名为MoE-LLaVA的新型LVLM架构,它基于专家混合(MoE)的概

hdu 4730 We Love MOE Girls(水题)
题目链接:hdu 4730 We Love MOE Girls 题目大意:给定一个字符串,如果末尾存在desu,就删除。然后统一加上nanodesu. 解题思路:水题。 #include <cstdio>#include <cstring>#include <algorithm>using namespace std;const int maxn = 205;const char

昆仑万维官宣开源2000亿稀疏大模型Skywork-MoE
6月3日,昆仑万维宣布开源2千亿稀疏大模型Skywork-MoE,性能强劲,同时推理成本更低。 据「TMT星球」了解,Skywork-MoE基于之前昆仑万维开源的Skywork-13B模型中间checkpoint扩展而来,是首个完整将MoE Upcycling技术应用并落地的开源千亿MoE大模型,也是首个支持用单台4090服务器推理的开源千亿MoE大模型。 开源地址: Skywork-M

MoE模型大火,源2.0-M32诠释“三个臭皮匠,顶个诸葛亮”!
文 | 智能相对论 作者 | 陈泊丞 近半年来,MoE混合专家大模型彻底是火了。 在海外,OpenAI的GPT-4、谷歌的Gemini、Mistral AI的Mistral、xAI的Grok-1等主流大模型都采用了MoE架构。而在国内,浪潮信息也刚刚发布了基于MoE架构的“源2.0-M32”开源大模型。 为什么MoE大模型备受瞩目,并逐步成为AI行业的共识? 知名科学杂志《N

ShowMeAI | 全球最有前途的100家AI公司,中国2家上榜;混合专家模型MoE详解;人大最新《大语言模型》电子书开放下载;斯坦福最新AI指数报告
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 1. CB Insights 发布「AI 100 2024」榜单,评选出全球最有前途的 100 家人工智能公司 CB Insights 是全球知名的市场情报分析机构,以其深入的数据分析、前瞻性的行业洞察而著称。CB Insights 最近发布了「AI 100 2024」榜单,综合

大语言模型从Scaling Laws到MoE
1、摩尔定律和伸缩法则 摩尔定律(Moore's law)是由英特尔(Intel)创始人之一戈登·摩尔提出的。其内容为:集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍;而经常被引用的“18个月”,则是由英特尔首席执行官大卫·豪斯(David House)提出:预计18个月会将芯片的性能提高一倍(即更多的晶体管使其更快),是一种以倍数增长的观测。[1] 然而,由于受到晶体管的散热问
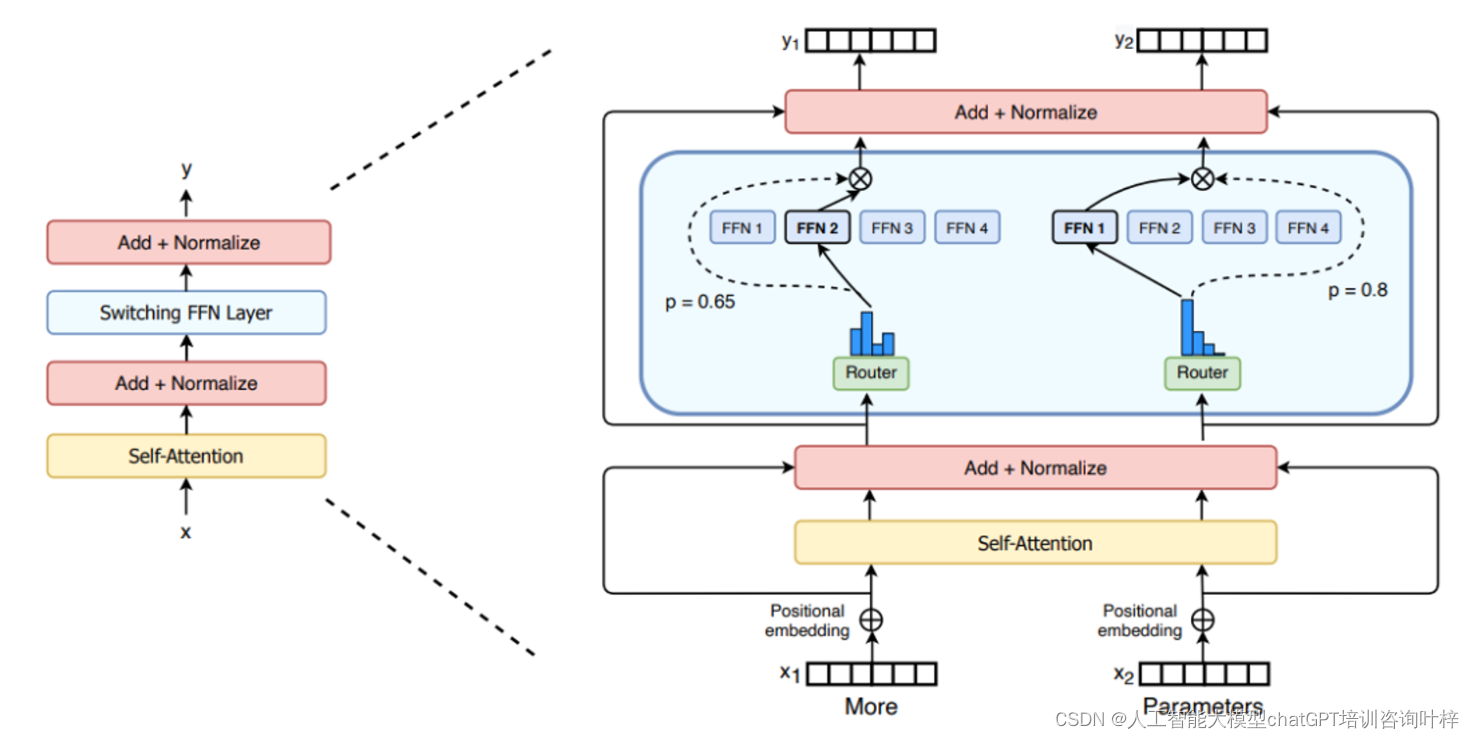
深度学习突破:LLaMA-MoE模型的高效训练策略
在人工智能领域,大模型(LLM)的崛起带来了前所未有的进步,但随之而来的是巨大的计算资源需求。为了解决这一问题,Mixture-of-Expert(MoE)模型架构应运而生,而LLaMA-MoE正是这一架构下的重要代表。 LLaMA-MoE是一种基于LLaMA系列和SlimPajama的MoE模型,它通过将LLaMA的前馈网络(FFNs)划分为稀疏专家,并为每层专家插入top-K个门,从而显

详解Mixtral-8x7B背后的MoE!
高端的模型往往只需最朴素的发布方式。 这个来自欧洲的大模型团队在12月8日以一条磁力链接的方式发布了Mixtral-8x7B,这是一种具有开放权重的**「高质量稀疏专家混合模型」**(SMoE)。 该模型在大多数基准测试中都优于Llama2-70B,相比之下推理速度快了6倍,同时在大多数标准基准测试中匹配或优于GPT-3.5。 之后,Mixtral AI将模型权重推送至Hug

通过创新的MoE架构插件缓解大型语言模型的世界知识遗忘问题
在人工智能领域,大型语言模型(LLM)的微调是提升模型在特定任务上性能的关键步骤。然而,一个挑战在于,当引入大量微调数据时,模型可能会遗忘其在预训练阶段学到的世界知识,这被称为“世界知识遗忘”。为了解决这一问题,复旦大学自然语言处理实验室的研究人员提出了LoRAMoE,这是一种创新的微调框架,通过类混合专家(MoE)架构来缓解这一问题。 LoRAMoE:一种新型微调框架 LoRAMoE的核心思
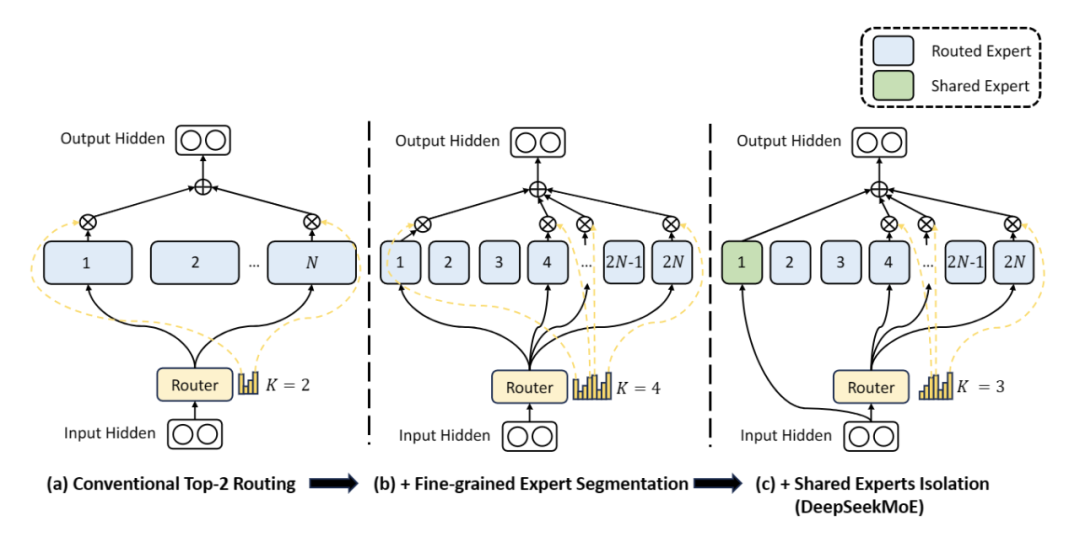
幻方量化开源国内首个MoE大模型,全新架构、免费商用
幻方量化开源国内首个MoE大模型,全新架构、免费商用 OSC OSC开源社区 2024-01-12 19:01 广东 幻方量化旗下组织深度求索发布了国内首个开源 MoE 大模型 —— DeepSeekMoE,全新架构,免费商用。 今年 4 月,幻方量化发布公告称,公司将集中资源和力量,全力投身到服务于全人类共同利益的人工智能技术之中,成立新的独立研究组织,探索 AGI 的本质。幻方将
元象4.2B参数 MoE大模型实战
01 简介 近期,元象公司推出了其首个Moe大模型XVERSE-MoE-A4.2B。该模型采用了混合专家模型架构(Mixture of Experts),并拥有4.2B的激活参数,其性能可与13B模型相媲美。值得一提的是,这个模型是完全开源的,可以无条件免费商用,这对于中小企业、研究者和开发者来说无疑是一个巨大的福音。他们可以在元象高性能“全家桶”中按需选用,以推动低成本部署。 在元象自研的过

阿里Qwen1.5-32B开源,评测超Mixtral MoE,挑战SOTA性价比
前言 阿里巴巴近日震撼开源其最新力作——Qwen1.5-32B大语言模型。在当前AI领域,大模型的开发与应用已成为评估技术进步的重要标尺。Qwen1.5-32B的问世,不仅再次证明了阿里在AI技术研发领域的深厚实力,更是在性能与成本之间找到了一个新的平衡点。 Qwen1.5-32B模型简介 Qwen1.5-32B继承了Qwen系列模型的卓越传统,拥有320亿参数,是在Qwen1.5系列中规模
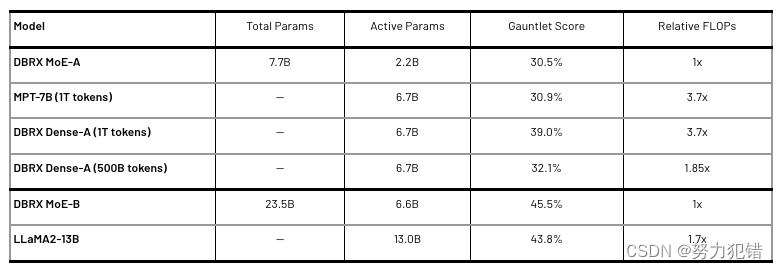
Databricks发布MoE大模型DBRX:1320亿参数开源模型,推理速度提升2倍,评测超越ChatGPT和LLama
前言 在人工智能领域,大型语言模型(LLM)的研发一直是技术竞争的前沿。最近,Databricks公司推出的DBRX模型,以其1320亿参数的规模和创新的细粒度MoE(混合专家)架构,成为开源社区的焦点。本文将深入探讨DBRX模型的关键技术细节、性能评测、以及它在推理速度、成本效率和多模态处理能力上的显著优势。 DBRX模型简介 DBRX是一种基于Transformer架构的混合专家模型
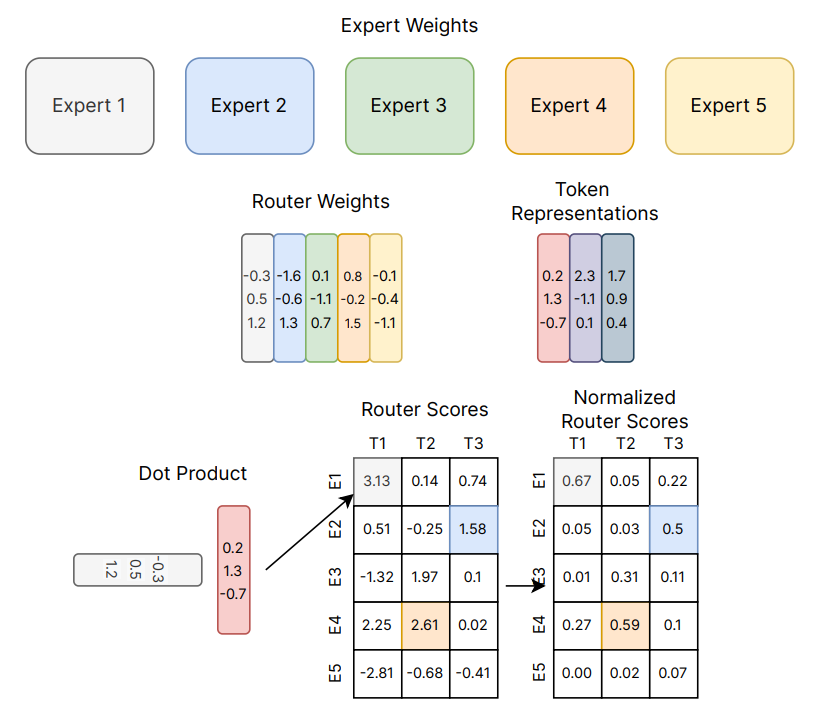
大模型面试准备(九):简单透彻理解MoE
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这里:《大模型面试宝典》(2024版) 正式发布! LLM 时代流传着一个法则:Scaling Law,即通过某种维度的指数上升可以带来指标的线性提升。 如下图所示