本文主要是介绍Databricks发布MoE大模型DBRX:1320亿参数开源模型,推理速度提升2倍,评测超越ChatGPT和LLama,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在人工智能领域,大型语言模型(LLM)的研发一直是技术竞争的前沿。最近,Databricks公司推出的DBRX模型,以其1320亿参数的规模和创新的细粒度MoE(混合专家)架构,成为开源社区的焦点。本文将深入探讨DBRX模型的关键技术细节、性能评测、以及它在推理速度、成本效率和多模态处理能力上的显著优势。

DBRX模型简介
DBRX是一种基于Transformer架构的混合专家模型,总参数达到1320亿,其中每次推理只激活360亿参数。这种细粒度的MoE架构不仅大幅提高了模型的处理速度,还显著降低了训练成本。Databricks声称,使用这种架构,DBRX的推理速度比LLaMA 2-70B快了2倍,同时训练成本直接减半,仅需1000万美元和3072块NVIDIA H100 GPU。
-
Huggingface模型下载:https://huggingface.co/databricks/dbrx-instruct
-
AI快站模型免费加速下载:https://aifasthub.com/models/databricks
技术亮点
DBRX模型采用了多项创新技术来实现其卓越性能:
-
细粒度MoE架构:DBRX拥有16个不同的专家,在每层为每个token选择4个专家进行处理,大大增加了处理效率和模型质量。
-
旋转位置编码(RoPE)、门控线性单元(GLU)和分组查询注意力(GQA):这些技术的使用进一步提高了模型的准确性和响应速度。
-
高效预训练策略:DBRX模型在12万亿Token的文本和代码上进行预训练,支持的最大上下文长度为32K。
性能评测
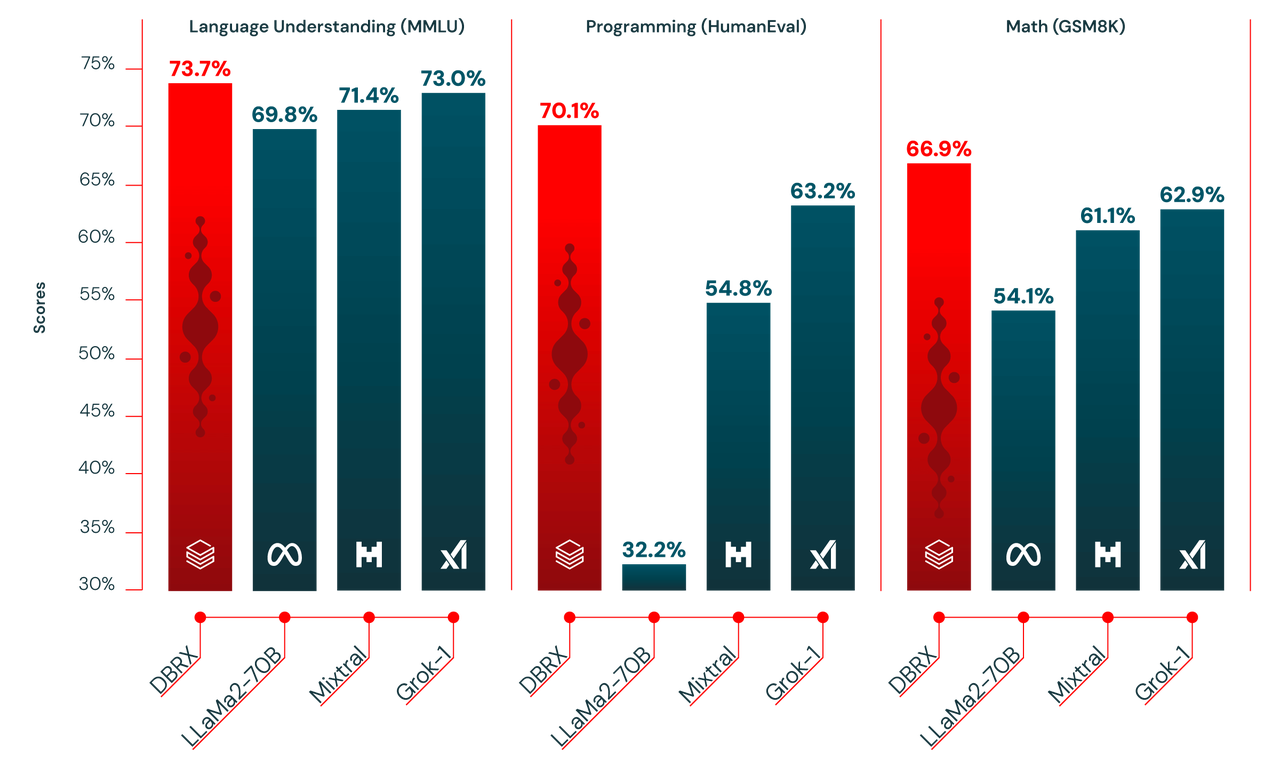
在多个基准测试中,DBRX模型表现出色,超越了当前开源模型的SOTA(State of the Art)水平,甚至在某些方面超越了闭源的大模型如ChatGPT和Llama。尤其在语言理解、编程和数学方面的任务,DBRX模型展现了其强大的处理能力和准确性。
-
DBRX 与开源模型比较

-
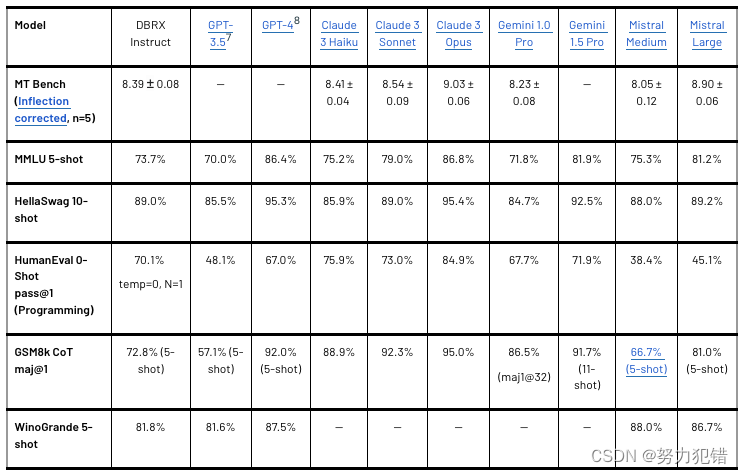
DBRX 与闭源模型比较
-
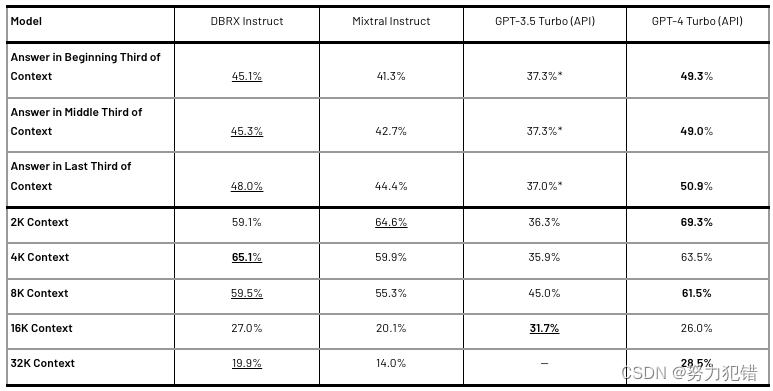
长下文任务和 RAG
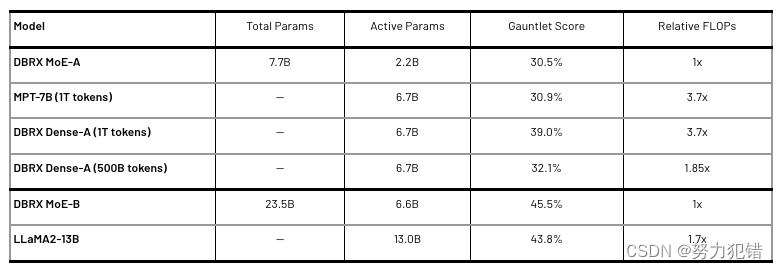
推理速度与成本效率
DBRX模型的另一个突出优势是其推理速度和成本效率。利用细粒度MoE架构,DBRX在保持高模型质量的同时,实现了更快的处理速度和更低的训练成本。这对于需要处理大量数据和复杂计算任务的企业和研究机构来说,具有极大的吸引力。
结论
Databricks发布的DBRX模型是开源大模型发展的一个重要里程碑。其创新的细粒度MoE架构、高效的预训练策略和显著的性能优势,为AI领域的发展提供了新的动力。随着DBRX模型的进一步优化和应用,预计会在多个领域带来突破性的进展。
模型下载
Huggingface模型下载
https://huggingface.co/databricks/dbrx-instruct
AI快站模型免费加速下载
https://aifasthub.com/models/databricks
这篇关于Databricks发布MoE大模型DBRX:1320亿参数开源模型,推理速度提升2倍,评测超越ChatGPT和LLama的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





