本文主要是介绍ShowMeAI | 全球最有前途的100家AI公司,中国2家上榜;混合专家模型MoE详解;人大最新《大语言模型》电子书开放下载;斯坦福最新AI指数报告,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!
1. CB Insights 发布「AI 100 2024」榜单,评选出全球最有前途的 100 家人工智能公司

CB Insights 是全球知名的市场情报分析机构,以其深入的数据分析、前瞻性的行业洞察而著称。CB Insights 最近发布了「AI 100 2024」榜单,综合考虑了公司交易活动、行业合作伙伴关系、团队实力、投资者实力、专利活动、专项评分等数据维度,并结合 CB Insights 调研和访谈,最终评选出了全球Top 100 的AI公司。
CB Insights 同时公布了这 100 家公司得详细数据 (Excel 文件),包括公司名、官网、分类、属地、关键角色、投资人/机构、最新融资轮次、融资金额等。中国入选公司有两家,分别是零一万物 (01.AI)、深势科技 (DP Technology),大家可以重点关注下~
2. 斯坦福 HAI 研究所最新「AI指数」报告,全面追踪全球AI发展趋势

4月15日,斯坦福大学 (Stanford University) 以人为本人工智能研究所 (Human-Centered Artificial Intelligence, HAI) 发布了最新版「(Artificial Intelligence Index Report 2024 (2024 年人工智能指数报告)」,全面追踪了2023年全球人工智能的发展趋势。
今年的报告多达 500 页,分成9个章节展示了制作团队对全球AI发展的了解和判断。以下是报告每章的重点内容。感兴趣可以直接跳转浏览。
- 第一章 研究与开发
- 第二章 技术性能
- 第三章 负责任的AI
- 第四章 经济
- 第五章 科学与医学
- 第六章 教育
- 第七章 政策与治理
- 第八章 多样性
- 第九章 公众意见
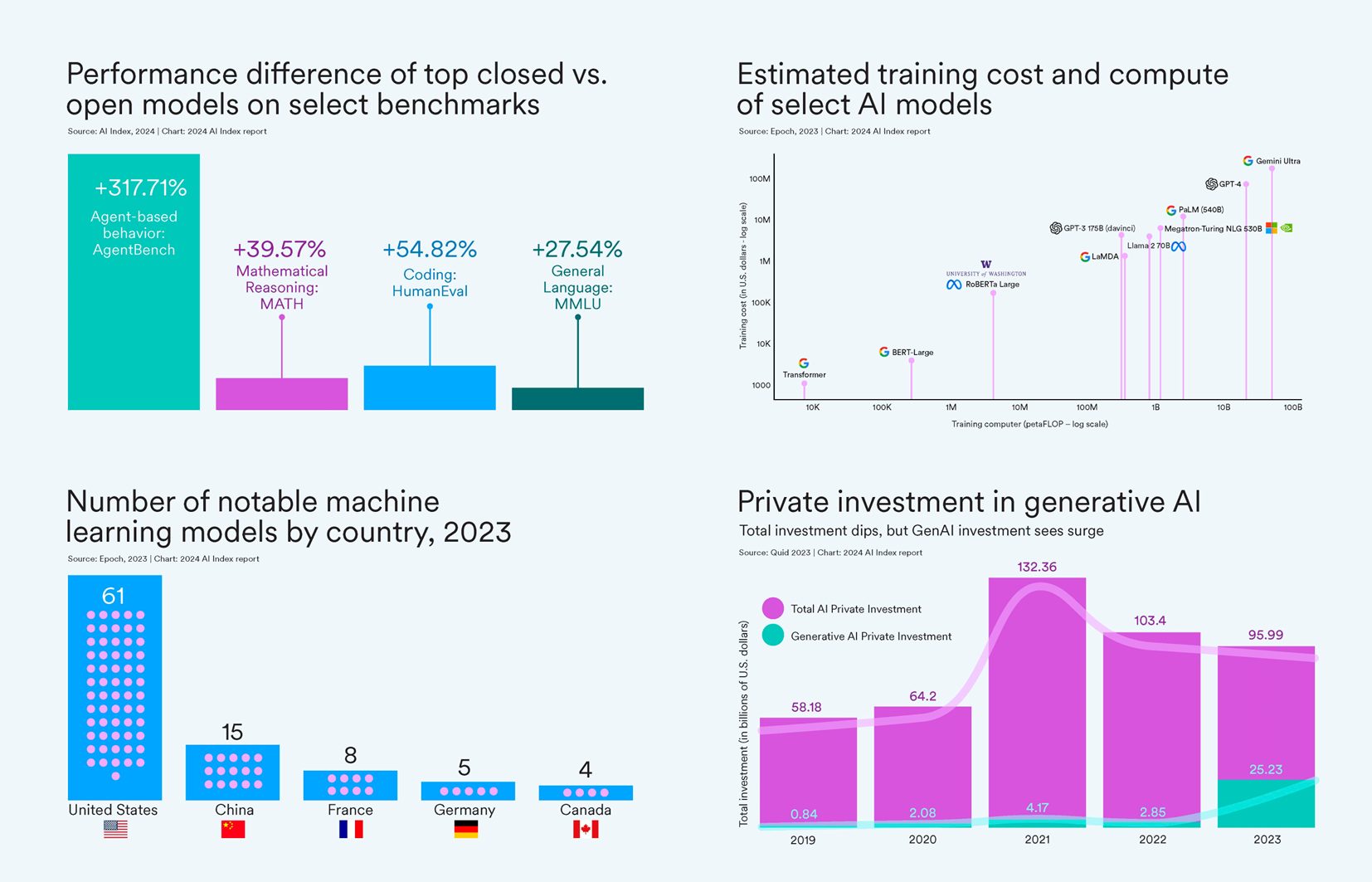
斯坦福 HAI 官网也发文,精炼了报告最重要的10 条结论,并对齐进行了详细解释。以下是最主要的结论。
- AI的局限性与超越:人工智能在某些任务上已超越人类,如图像分类、视觉推理和英语理解等领域。
- 工业对前沿AI研究的主导地位:2023年,工业界产出了 51 个显著的机器学习模型,而学术界仅贡献了15个。
- 前沿模型的成本急剧上升:据人工智能指数估计,最先进的AI模型的培训成本已达到前所未有的水平。
- 美国在顶尖AI模型开发中领先:2023年,有 61 个重要的AI模型起源于美国机构,远超欧盟的21个和中国的15个。
- 对 LLM 责任性的评估缺乏严格与标准化:最新研究显示,负责任的AI报告在标准化方面存在显著不足。
- 生成式AI的投资激增:尽管去年整体的人工智能私人投资有所下降,但生成式AI的融资额却激增,从2022年起几乎增长了八倍,达到252亿美元。
- 数据显示:AI提升工作效率与质量:2023年的多项研究评估了AI对劳动力的影响,结果表明AI帮助工作者更快完成任务并提高了工作质量。
- AI进一步加速科学进展:2022年,AI开始推动科学发现。
- 美国AI相关法规的数量大幅增加:过去一年,以及过去五年内,美国的AI相关法规数量显著增加。
- 全球对AI影响的认识加深,同时担忧也增加:Ipsos 的一项调查显示,过去一年内认为AI将在未来三到五年内极大影响其生活的人的比例从 60% 增加到 66%。
3. Full Steam Ahead: The 2024 MAD (Machine Learning, AI & Data) Landscape

FirstMark Capital 是一家早期风险投资公司,位于美国纽约,成立于2008年,热衷投资那些有望成为行业标杆的公司,然后加速其成长。
3月底,FirstMark 公布了其2024年「Mad Landscape」,即Machine Learning 机器学习、Artificial Intelligence 人工智能、Data数据领域的行业全景图。这也是 FirstMark 自2012年以来第10次发布 MAD 报告。

4. 《大语言模型》书籍中文版开放下载!还配套代码工具库~
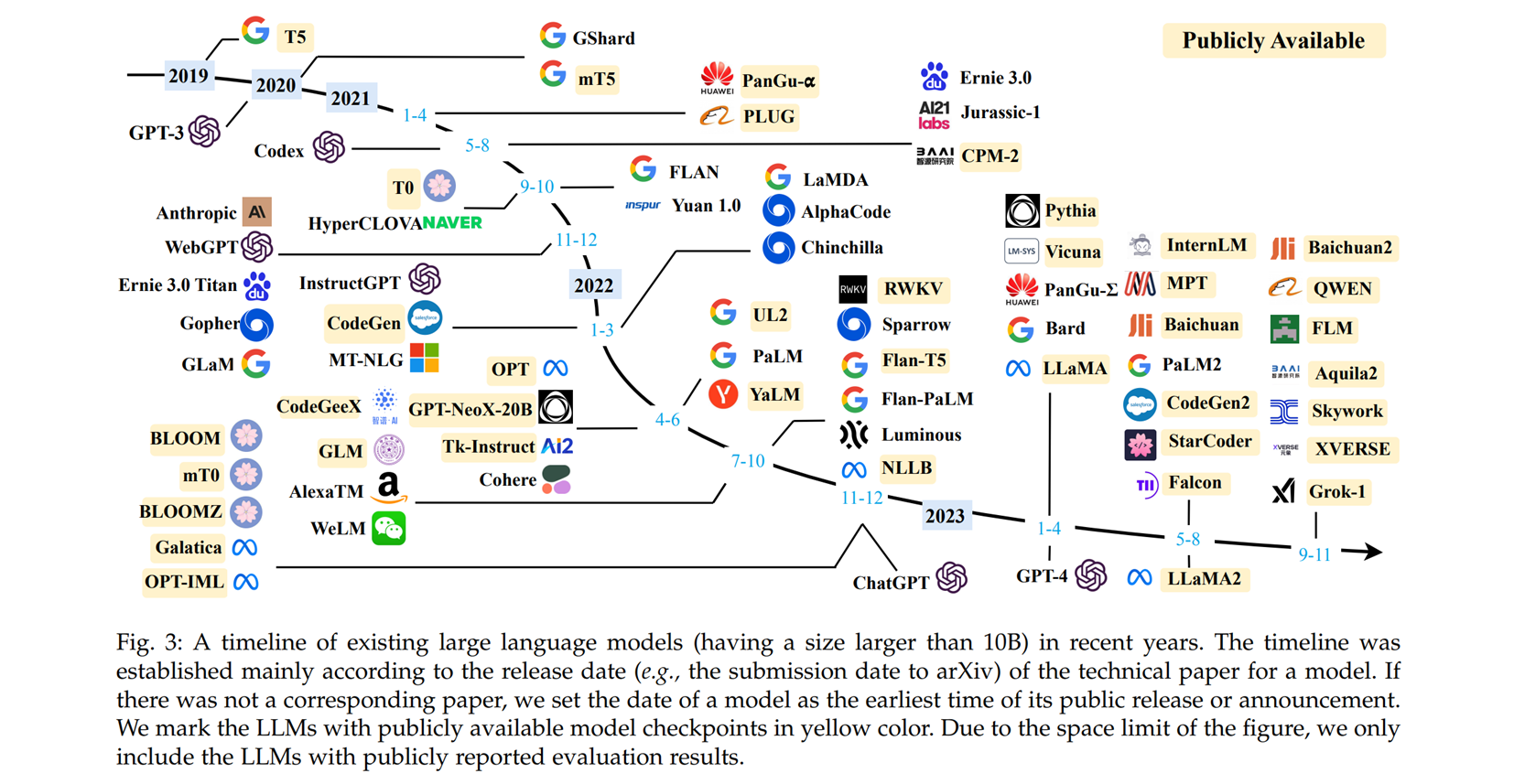
上面这张图出自大语言模型综述文章《A Survey of Large Language Models》,被广泛引用和转发。这篇论文首发于2023年3月,目前已经更新到了第13个版本,包含了83页的正文内容,并收录了900余篇参考文献。此外,团队还在2023年8月发布了该综述(v10)的中文翻译版。

然后!这个团队终于出书啦!而且是中文版——《大语言模型》!这本书整理呈现了大模型技术框架和路线图,是一本非常好的入门书籍。此外,官方不仅发布了电子版 PDF 下载链接,还提供了配套资源。点赞 👍 📚 官方介绍与图书下载
以下是书籍大纲,如果有你感兴趣的内容,可以直接下载和阅读啦!
第一部分 背景与基础知识
- 第一章 引言
- 第二章 基础介绍
- 第三章 大语言模型资源
第二部分 预训练
- 第四章 数据准备
- 第五章 模型架构
- 第六章 模型预训练
第三部分 微调与对齐
- 第七章 指令微调
- 第八章 人类对齐
第四部分 大模型使用
- 第九章 解码与部署
- 第十章 提示学习
- 第十一章 规划与智能体
第五部分 评测与应用
- 第十二章 评测
- 第十三章 应用
- 第十四章 总结
5. 混合专家模型(MoE)会是大模型新方向吗
混合专家模型 (Mixture of Experts, MoE) 逐渐成为大模型的热门框架。最新的 LlaMa 3 没有由于采用 MoE 架构,激起了AI社区里一些「表示失望」的声音。日报选择几篇文章和视频,由浅入深讲清楚 MoE 到底是什么。 ⋙ 阅读原文
🎨 MoE 前世今生
- 2017 年,谷歌首次将 MoE 引入自然语言处理领域,通过在 LSTM 层之间增加 MoE 实现了机器翻译方面的性能提升。
- 2020 年,Gshard 首次将 MoE 技术引入 Transformer 架构中,并提供了高效的分布式并行计算架构,而后谷歌的 Swtich Transformer 和 GLaM 则进一步挖掘 MoE 技术在自然语言处理领域中的应用潜力,实现了优秀的性能表现。
- 2021 年的 V-MoE 将 MoE 架构应用在计算机视觉领域的 Transformer 架构模型中,同时通过路由算法的改进在相关任务中实现了更高的训练效率和更优秀的性能表现。
- 2022 年的 LIMoE 是首个应用了稀疏混合专家模型技术的多模态模型,模型性能相较于 CLIP 也有所提升。
- 近期 Mistral AI 发布的 Mistral 8x7B 模型是由 70 亿参数的小模型组合起来的 MoE 模型,直接在多个跑分上超过了多达 700 亿参数的 Llama 2。
- 将混合专家模型 (MoE) 应用于大模型中似乎是不一个不错的想法,Mistral AI 发布的 Mistral 8x7B 模型在各项性能和参数上证明了这一点,使用了更少的参数却获得了远超于 Llama 2 的效果,这为大模型的发展提供了一种新的思路。
🎨 MoE 简单介绍
- 混合专家模型 (MoE) 是一种稀疏门控制的深度学习模型,它主要由一组专家模型和一个门控模型组成。
- MoE 的基本理念是将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配一个或多个专家模型。每个专家模型可以专注于处理输入这部分数据,从而提高模型的整体性能。
- MoE 架构的基本原理非常简单明了,它主要包括两个核心组件:GateNet 和 Experts。GateNet 的作用在于判定输入样本应该由哪个专家模型接管处理。而 Experts 则构成了一组相对独立的专家模型,每个专家负责处理特定的输入子空间。
🎨 MoE 优势
- 任务特异性:MoE通过专业化的专家模型,针对不同任务或数据部分进行处理,提升准确性和泛化能力。
- 灵活性:根据任务需求,MoE能够灵活选择和组合专家模型,动态处理输入数据。
- 高效性:MoE的稀疏性设计减少了计算开销,提高了计算效率。
- 表现能力:通过组合专家模型,MoE增强了对复杂数据结构的建模能力。
- 可解释性:专家模型的独立性使得MoE的决策过程更易于理解和解释。
- 大规模数据处理:MoE利用稀疏矩阵和GPU并行计算,有效处理大规模数据集,提升训练和推理效率。
🎨 MoE 问题
- 训练复杂性:MoE的训练涉及复杂的门控网络参数调整,可能需要较长时间。
- 超参数调整:确定合适的超参数,特别是门控网络相关参数,是一个技术挑战。
- 专家模型设计:选择和设计表现力强的专家模型结构是关键。
- 稀疏性失真:需要平衡门控网络的稀疏性,避免过度激活或不激活专家模型。
- 动态性适应:MoE需要灵活调整以适应动态变化的数据分布。
- 噪声敏感性:MoE可能对数据噪声较为敏感,有时可能不如简单模型稳健。
- 通信瓶颈:在分布式部署中,MoE可能面临通信宽带瓶颈问题。
🎨 MoE 相关论文
- Adaptive mixtures of local experts, Neural Computation’1991
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, ICLR’17
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, ICLR’21
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, JMLR’22
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts, 2021
- Go Wider Instead of Deeper, AAAI’22
- MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation, NAACL’22
6. HuggingFace 深度好文 | 混合专家 (MoE) 模型详解

HuggingFace 这篇 MoE 最新专题长文,深度了解MoE 的核心组件、训练方法,以及在推理过程中需要考量的各种因素。而且 官方中文版 的翻译质量也质量非常好,可以说是了解 MoE 的必读文章了!
🎨 MoE 要点小结
- 与稠密模型相比,预训练速度更快。
- 与具有相同参数数量的模型相比,具有更快的推理速度。
- 需要大量显存,因为所有专家系统都需要加载到内存中。
- 在微调方面存在诸多挑战,但近期的研究表明,对 MoE 进行指令调优具有很大的潜力。
🎨 什么是 MoE?
- MoE 是一种在 Transformer 模型中引入的创新架构,它通过将模型中的前馈网络 (FFN) 层替换为包含多个专家的稀疏层来提高训练和推理效率。这些专家可以是简单的神经网络,也可以是更复杂的结构。
- MoE 的关键组件包括门控网络 (用于决定哪些 token 被发送到哪个专家) 和专家本身。
- 这种架构允许模型在较少的计算资源下进行有效的预训练,并在推理时实现更快的速度。
🎨 MoE 简史
- MoE 的历史可以追溯到1991年的「自适应局部专家混合」概念,它与集成学习方法相似,旨在通过门控网络来优化多个单独网络的性能。
- 近年来,MoE在自然语言处理 (NLP) 领域得到了广泛应用,尤其是在大规模模型训练中。
🎨 什么是稀疏性?
- 稀疏性是 MoE 的一个核心概念,它允许模型仅对输入的特定部分执行计算,而不是像传统稠密模型那样处理所有数据。
- 这种条件计算的思想使得MoE能够在不增加额外计算负担的情况下扩展模型规模。
🎨 MoE 中token的负载均衡
- 在 MoE 中,token 的负载均衡是一个关键问题,因为如果所有 token 都被发送到少数几个专家,训练效率会降低。
- 研究者们引入了辅助损失来确保所有专家接收到大致相等数量的训练样本,从而平衡专家之间的选择。
🎨 MoE and Transformers
- MoE 基于 Transformer,但替换了 FFN 层。
- MoE 层包含多个专家,用于处理输入,这也就是其稀疏层。
🎨 Switch Transformers
- MoE 在 Transformer 模型中的应用,特别是在 Switch Transformers 中,通过简化的单专家策略和专家容量的概念,提高了训练的稳定性和效率。
- Switch Transformers 还探索了混合精度训练和负载均衡损失的简化版本,以提高模型性能。
🎨 用 Router z-loss 稳定模型训练
在训练 MoE 时,稳定性是一个挑战,但通过引入 Router z-loss 等机制可以提高稳定性。
🎨 专家如何学习?
- 专家学习的方式也有所不同,编码器中的专家倾向于专注于特定类型的 token 或概念。
- 解码器中的专家则具有较低的专业化程度。
🎨 专家的数量对预训练有何影响?
- 增加更多专家可以提升处理样本的效率和加速模型的运算速度。
- 但边际效应递减,并且影响模型的泛化能力和训练效率。
🎨 微调 MoE
- MoE在微调时面临挑战,但最近的研究表明,对MoE进行指令调优具有很大的潜力。
- 微调策略包括冻结非专家层的权重,使用辅助损失,以及调整微调超参数。
🎨 稀疏 VS 稠密,如何选择?
- 在选择稀疏模型还是稠密模型时,需要考虑计算资源、显存需求和吞吐量要求。
- MoE 适用于多台机器且要求高吞吐量的场景,而稠密模型则适用于显存较少且吞吐量要求不高的场景。
🎨 让 MoE 起飞
- 并行计算:MoE 适用于多台机器并行训练。
- 容量因子和通信开销:通过技术如预先蒸馏和任务级别路由简化模型结构。
- 部署技术:降低推理时的参数数量,提高部署效率。
- 高效训练:为了提高 MoE 的效率,研究者们探索了并行计算、容量因子和通信开销的优化,以及部署技术;例如,通过预先蒸馏、任务级别路由和专家网络聚合等技术,可以简化模型结构并降低推理时的参数数量。
🎨 开源 MoE
平台:如 Megablocks、Fairseq 和 OpenMoE,提供研究和训练 MoE 的资源。
🎨 一些有趣的研究方向
- 蒸馏到稠密模型:MoE 到稠密模型的蒸馏技术。
- 合并专家模型技术:将多个专家模型合并为一个。
- 极端量化:探索 MoE 的极端量化技术。
7. Mixtral-8x7B 模型源码解读 & 结构流程图演示:彻底搞懂 MoE 实现细节
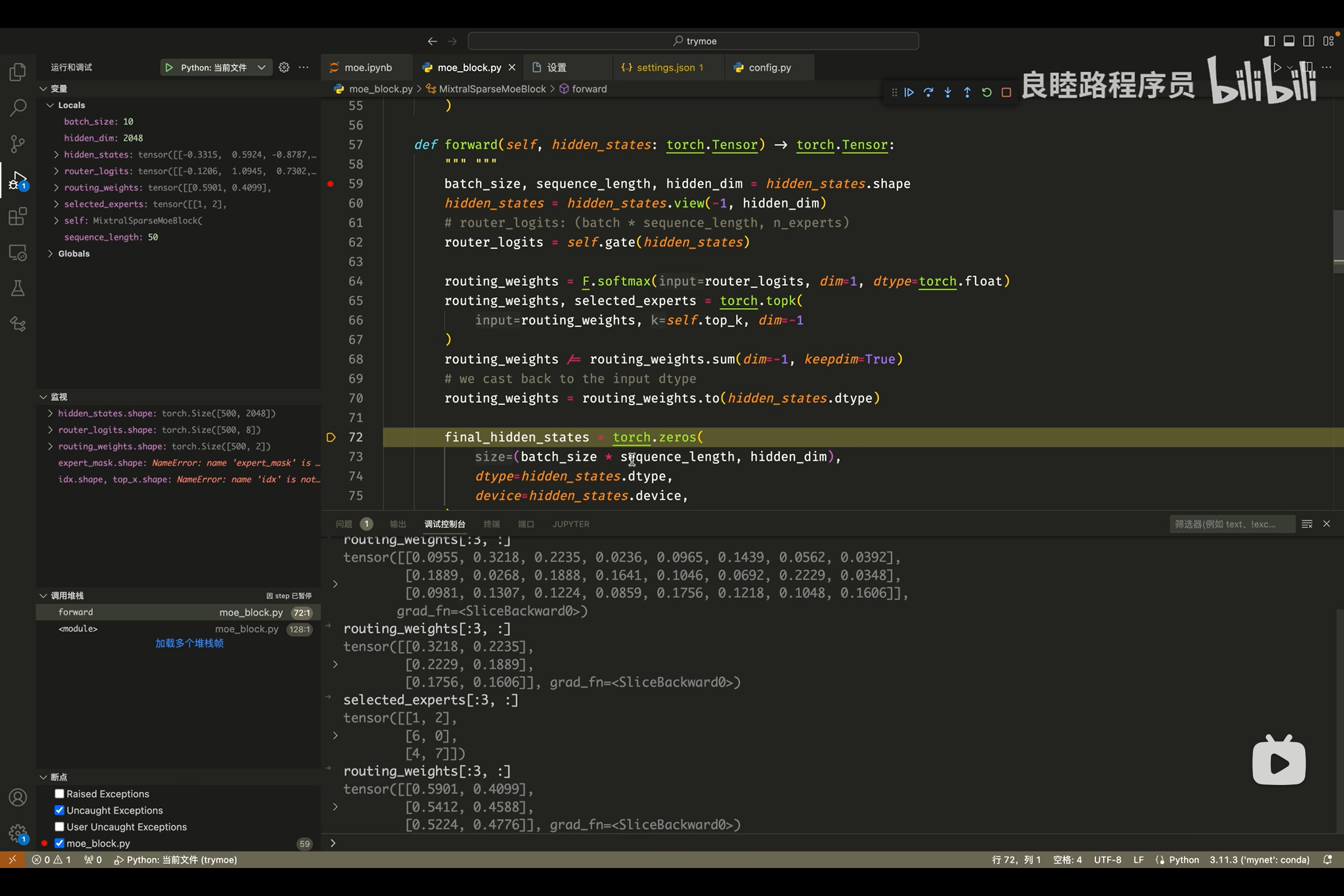
如果你想通过视频演示、源码讲解的方式,更深入了解 MoE 模型,那么B站 @良睦路程序员 的视频则一定要不要错过~
UP主在这期视频里,用30分钟的时间,对照着源代码,非常清晰地讲解了 MoE的网络架构细节、MoE是否具备彻底颠覆LLaMa的潜力、MoE 与传统 LLaMa 架构的区别是什么…… 📺 MoE实现细节·视频讲解
而且!非常难得的是,UP可以把很技术的内容讲成大!白!话! 比如,为了帮助大家理解 MoE 的工作原理,他举了一个非常生活化的例子:
把模型的8个 Expert 理解成我们吃饭时的8个工具,比如锅铲、筷子、叉子、剪刀、手…… 手撕羊肉想吃爽的话,首选的2个工具是「手」和「叉子」;而喝汤的时候,最合适的2个工具就变成了「勺子」「筷子」。
这其实就对应着 MoE 的调度机制:在不同的维度里,从8个 MoE 里选择最合适的2个,然后把二者输出的权重相加。然后无限次重复。

为了方便大家理解,@良睦路程序员 还画了一张 Mixtral 模型的框架图,帮助我们清晰地理解 MoE 到底是什么架构,以及内部的细节原理。搭配作者专门录制的第二期讲解视频,就可以彻底搞清楚MoE 啦!!📺 图解MoE细节·视频讲解

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ > 前往 🎡ShowMeAI,获取结构化成长路径和全套资料库,用知识加速每一次技术进步!
这篇关于ShowMeAI | 全球最有前途的100家AI公司,中国2家上榜;混合专家模型MoE详解;人大最新《大语言模型》电子书开放下载;斯坦福最新AI指数报告的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





