本文主要是介绍通过创新的MoE架构插件缓解大型语言模型的世界知识遗忘问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在人工智能领域,大型语言模型(LLM)的微调是提升模型在特定任务上性能的关键步骤。然而,一个挑战在于,当引入大量微调数据时,模型可能会遗忘其在预训练阶段学到的世界知识,这被称为“世界知识遗忘”。为了解决这一问题,复旦大学自然语言处理实验室的研究人员提出了LoRAMoE,这是一种创新的微调框架,通过类混合专家(MoE)架构来缓解这一问题。
LoRAMoE:一种新型微调框架
LoRAMoE的核心思想是在微调阶段引入局部平衡约束损失(Localized balancing constraint),以协调模型中的多个专家(experts),确保一部分专家专注于下游任务,而另一部分专家则利用模型中存储的世界知识,从而避免知识遗忘。
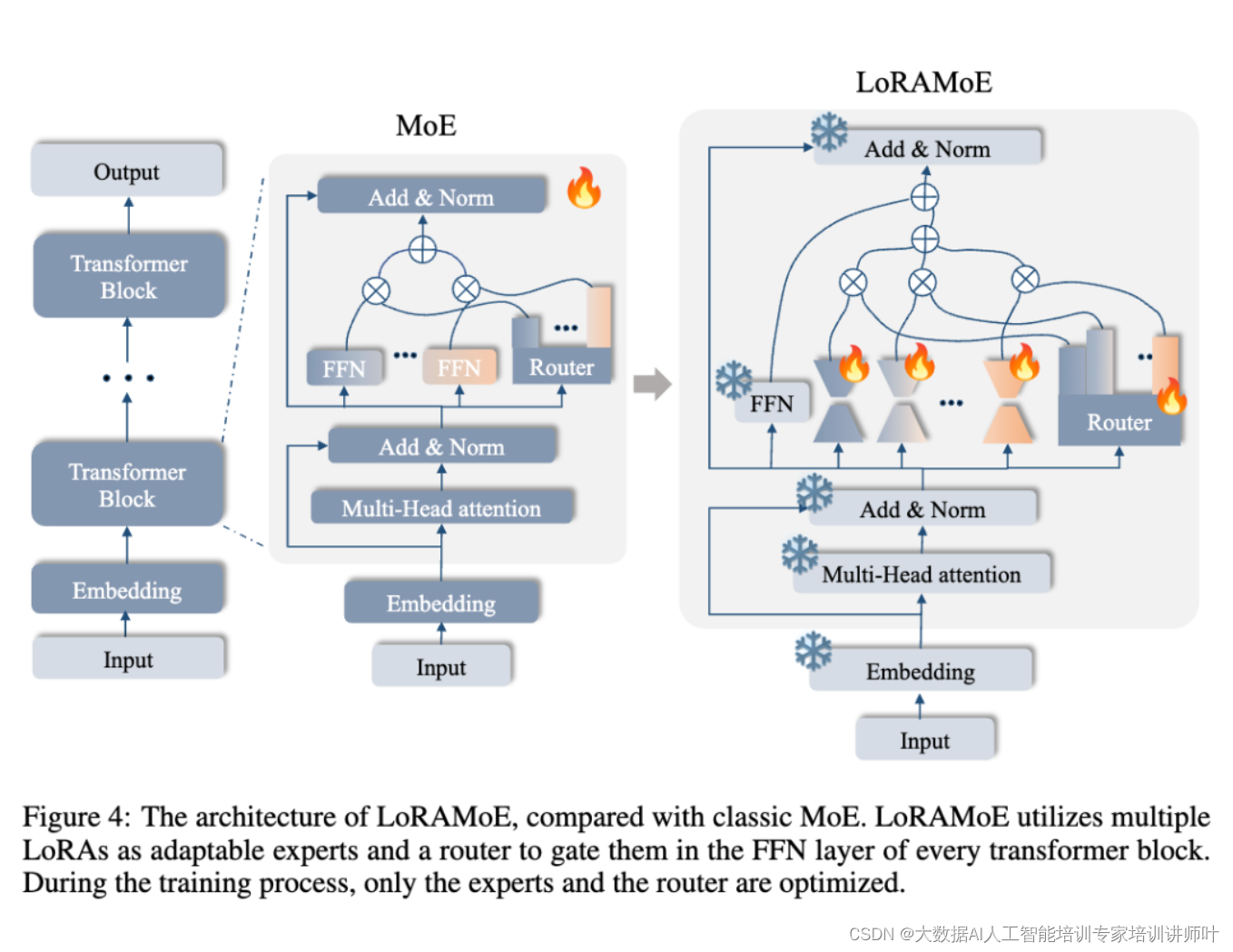
LoRAMoE的核心机制
LoRAMoE框架的核心在于它对专家的使用和管理方式。在传统的MoE架构中,路由器根据输入数据动态地选择最合适的专家进行处理。然而,这种方式可能导致专家之间的不平衡,即一些专家可能会被频繁使用,而其他专家则可能被忽视。为了解决这一问题,LoRAMoE引入了局部平衡约束损失(Localized balancing constraint loss),它允许模型根据数据的类型和任务的需求,合理地分配专家的工作负载。
LoRAMoE的工作流程
-
参数冻结与专家引入:在LoRAMoE中,主模型的参数在微调阶段被冻结,以保持其世界知识不变。同时,引入了多个专家,这些专家通过路由器网络进行管理和调用。
-
专家的低秩表示:为了提高训练和推理的效率,LoRAMoE使用低秩矩阵来表示专家的参数矩阵,这大大减少了可训练参数的数量。
-
局部平衡约束:LoRAMoE的训练阶段采用了局部平衡约束,这种约束机制鼓励一部分专家专注于处理与世界知识相关的任务,而另一部分专家则专注于提升模型在其他下游任务上的性能。
-
动态权重分配:在推理过程中,路由器根据输入数据的类型和当前任务的需求,动态地为不同的专家分配权重,从而实现对专家的灵活调用。
LoRAMoE的优势
- 减少知识遗忘:通过局部平衡约束,LoRAMoE能够在模型微调过程中减少对原有世界知识的破坏。
- 提升多任务性能:LoRAMoE通过专家的协作,提升了模型在多个下游任务上的性能。
- 灵活性和泛化能力:LoRAMoE的动态权重分配机制使得模型能够灵活地适应不同的任务需求,增强了模型的泛化能力。
LoRAMoE的工作原理
LoRAMoE(Localized Mixture of Experts)的工作原理围绕其创新的架构设计,旨在解决大型语言模型(LLM)在微调过程中可能遇到的世界知识遗忘问题。以下是LoRAMoE工作原理的详细解释:
1. 架构设计
LoRAMoE采用了混合专家(MoE)风格的架构,其中“混合”指的是模型不是单一的专家,而是由多个专家组成,每个专家负责处理一部分输入数据。这些专家通过一个路由器网络进行协调,路由器负责将输入分配给最合适的专家。
2. 参数冻结与专家引入
在LoRAMoE中,主模型(即大型语言模型的主体部分)的参数在微调阶段被冻结,以保护其在预训练阶段学到的世界知识。然后,引入了一组低秩适配器(LoRA),这些适配器作为可训练的专家,与主模型并行工作。
3. 低秩适配器(LoRA)
每个专家使用LoRA结构,这是一种低秩矩阵近似方法,可以显著减少模型的参数数量和计算复杂度。在LoRAMoE中,专家的参数矩阵被表示为两个低秩矩阵的乘积,这样做可以在保持模型性能的同时,减少训练和推理时的资源消耗。
4. 路由器网络
路由器网络是LoRAMoE中的一个关键组件,它根据输入数据的特征动态地为每个输入分配最合适的专家。路由器的决策基于输入数据和专家的权重,这些权重在训练过程中不断更新。
5. 局部平衡约束损失
LoRAMoE引入了局部平衡约束损失,这是一种新的损失函数,用于平衡不同专家的工作负载,并防止路由器总是选择相同的少数专家。这种约束确保了专家们在训练过程中都能得到充分的利用和训练。
6. 训练与推理
在训练阶段,只有专家和路由器的参数会被更新,而主模型的参数保持不变。这种训练策略使得LoRAMoE能够在微调时减少对主模型世界知识的破坏。在推理阶段,路由器根据输入数据的类型和当前任务的需求,动态地为不同的专家分配权重,实现灵活的专家调用。
7. 多任务性能提升
通过上述设计,LoRAMoE能够在处理各种下游任务时,根据任务的需要合理地协调不同专家的工作,从而在保持世界知识的同时,提升模型在多个任务上的性能。
实验结果
研究人员在包括知识问答、代词消歧、摘要、阅读理解、自然语言推理(NLI)、机器翻译和文本分类等七种任务上进行了广泛的实验。实验结果表明,LoRAMoE能够在大幅增加指令数据量时,显著提高模型处理下游任务的能力,同时保持模型中存储的世界知识。

LoRAMoE作为一种新型的微调框架,为解决大规模微调数据导致的世界知识遗忘问题提供了有效的解决方案。通过在微调阶段引入局部平衡约束损失,LoRAMoE不仅保持了模型的世界知识,还提高了模型在多任务上的性能,展示了在大型语言模型微调中的潜力。
参考文献
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin。
这篇关于通过创新的MoE架构插件缓解大型语言模型的世界知识遗忘问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




