遗忘专题

大模型全量微调和LoRA微调详细说明,如何避免灾难性遗忘
在使用大模型进行微调时,特别是在语音识别、自然语言处理等任务中经常会遇到两个主要方法:全量微调和LoRA微调。全量微调涉及更新模型的所有参数,而LoRA(Low-Rank Adaptation)则专注于更新少量的参数来适应新的任务。这两种方法各有优缺点,并有不同的应用场景。 全量微调 1. 什么是全量微调? 全量微调是指在微调阶段,更新模型中所有参数。这个过程通常在大规模数据集上进行,以适应

遗忘linux的root密码,怎么修改?
1.重启Linux系统,在开机界面出现时按e进入编辑模式。 2.找到以ro开头的字母,删除ro及后面同行的指令,然后在这个位置添加指令rw rd.break然后按ctrl+x就会进入到RAM Disk的环境。 rw rd.break 是 Linux 系统引导参数,用于在引导过程中挂载根文件系统为可读写模式(read-write),并在加载初始 RAM 磁盘(initramfs)阶段中断引导。

LoRAMoE:缓解大模型的世界知识遗忘问题
人工智能咨询培训老师叶梓 转载标明出处 大模型(LLMs)在进行SFT时,通过增加指令数据量来提升其在多个下游任务中的性能或显著改善特定任务的表现。但研究者们发现,这种大规模的数据增加可能会导致模型遗忘其预训练阶段学习到的世界知识。这种遗忘现象在封闭书籍问答等任务中尤为明显,这些任务通常用来衡量模型的世界知识水平。 为了应对这一挑战,复旦大学的研究团队提出了LoRAMoE框架。LoRAMoE是

0.0 C语言被我遗忘的知识点
文章目录 位移运算(>>和<<)函数指针函数指针的应用场景 strcmp的返回值合法的c语言实数表示sizeof 数组字符串的储存 —— 字符数组与字符指针字符串可能缺少 '\0' 的情况 用二维数组储存字符串数组其他储存字符串数组的方法 位移运算(>>和<<) 右移(>>) 数值变为原数值÷2 右端移出的二进制数舍弃,左端(高位)移入的二进制数分两种情况: 对于无符号

【Windows】被遗忘的宝藏:Windows 10 LTSC 2021 官方精简版
当Windows 11如火如荼地推广之际,许多用户开始怀念Windows 10带来的流畅体验。虽然Windows 11以其现代化的界面和改进的性能吸引了不少用户,但在实际使用中,一些用户还是觉得它在响应速度上稍显不足。今天,就让我们来重新认识一个被微软“雪藏”的系统——Windows 10 LTSC 2021官方精简版。 什么是Windows 10 LTSC? LTSC,全称为Long-Ter

(2024,示例记忆,模型记忆,遗忘,差分评估,概率评估)深度学习中的记忆:综述
Memorization in deep learning: A survey 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0 摘要 1 引言 0 摘要 深度神经网络(DNNs)驱动的深度学习(DL)已经在各个领域引发了革命性变化,但理解 DNN 决策和学习过程的复杂性仍然是一个重大挑战。最近的研究发现了


遗忘在角落的好看瓶子中的幸运星
遗忘在角落的好看瓶子中的幸运星 幸运星的折法 这么久 还是没有忘记 或许就像某些记忆 放在心底 未曾忘怀 直到某一天 看见某个遗忘在角落的好看瓶子中的幸运星 刹那想起 在我的记忆中 曾经有过你 2015/10/29
装修10个容易被遗忘的开关插座位置
雅静说家里开关插座哪些最容易忘记了留? 一共10个,你看看有少的吗,我家水电师父就没有留够 来了又重新补的很麻烦,记得收藏 1,大门口上边留一个,后期可以安装监控 特别家里有老人和小孩,以及经常来快递的 2,弱电箱留一个,可以放光猫路由器,用电方便 3,阳台离地30公分留一个,方便后期充电或跑步机使用 4,浴室柜上边留个电线

网络遗忘权的实现方法
网络遗忘权的实现方法 目录 从禁书说起 从销毁硬件信息的方法得到的启示 现在网络遗忘权的实现方法 从禁书说起 古代有禁书的需求,直接的方法就是贴出告示,强行收缴,然后付之一炬. 这个方法的问题在于只要有一个人敢冒死藏书,再次手抄或者是印刷,就 会让之前的禁书努力,付之东流. 后来,有篡改书的方法,让改过的伪书 大量流行于市,把真书淹没于伪书的汪洋大海之中.这方法真妙啊.效果 出
乔纳森-弗莱彻:被遗忘的搜索引擎之父
转载自:http://tech.qq.com/a/20130905/000852.htm 腾讯科技 腾讯科技 瑞雪 9月5日编译 在谷歌(微博)庆祝其15周年诞辰之际,这家网络巨头已经成为信息检索的代名词。 但是,如果你在谷歌搜索引擎中输入乔纳森·弗莱彻(Jonathon Fletcher)的名字,那么在马上得出的搜索结果中不会找到什么线索指向他曾在万维网发展的过程中所扮演
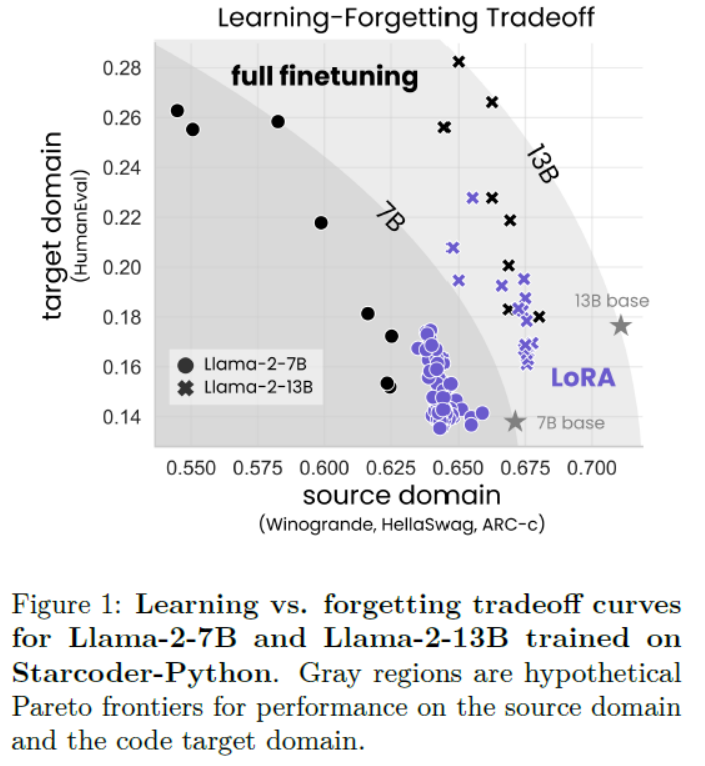
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读 导读:该论文比较了LoRA与完全微调在代码与数学两个领域的表现。 背景问题:微调大规模语言模型需要非常大的GPU内存。LoRA这一参数高效微调方法通过仅微调选择性权重矩阵的低秩扰动来节省内存。 解决方案:LoRA假设微调后的权重矩阵的变化可以近
记录一些容易遗忘的东西
文章目录 native、sync 修饰符this.$nextTick native、sync 修饰符 native :在对子组件使用 @click 的时候若不使用该修饰符,那么就不能执行点击事件,会被判断为子向父组件传的值sync : 类似于 v-model 的响应式修饰符,在 父向子、子向父 传值的时候,若父更改,子能接收,子用 props 接收,从理论上来说,不能直接更改 p

通过创新的MoE架构插件缓解大型语言模型的世界知识遗忘问题
在人工智能领域,大型语言模型(LLM)的微调是提升模型在特定任务上性能的关键步骤。然而,一个挑战在于,当引入大量微调数据时,模型可能会遗忘其在预训练阶段学到的世界知识,这被称为“世界知识遗忘”。为了解决这一问题,复旦大学自然语言处理实验室的研究人员提出了LoRAMoE,这是一种创新的微调框架,通过类混合专家(MoE)架构来缓解这一问题。 LoRAMoE:一种新型微调框架 LoRAMoE的核心思
一些背我遗忘又比较有用的C++语法知识
一,STL http://net.pku.edu.cn/~yhf/UsingSTL.htm 二,C++重载各种运算符 http://blog.csdn.net/durongjian/archive/2008/12/26/3613120.aspx
烂笔头,记录一年遗忘
nacos-server:2.0.3 docker 部署 docker run --name nacos -d -p 8848:8848 -p 9848:9848 -p 9849:9849 --privileged=true --restart=always -e JVM_XMS=512m -e JVM_XMX=512m -e MODE=standalone -e MYSQL_SERVICE_D
大脑和人工智能克服遗忘
大脑和人工智能克服遗忘 在人类大脑和人工神经网络(ANN)中,遗忘是一个共通挑战。人类大脑通过声明性记忆与非声明性记忆,并通过睡眠中的记忆巩固,有效管理信息并克服遗忘。相比之下,ANN在学习新信息时常遭遇灾难性遗忘,丧失先前掌握任务的能力。为解决这一问题,研究人员寻求大脑启发的解决方案,包括网络重激活和连接权重重叠减少策略。 大脑记忆机制与人工智能的启示 大脑通过声明性和非声明性记忆,并利用
10.暂时遗忘的表达
I forget it. 1.Where was I? == What was I saying. 2.It's on the tip of my tongue.我差点就想起来了 the mother tongue 母语 tongue twister 绕口令 tip: n.尖端 3.It's slipped my mind.我想不起来
某些之前的漏洞的遗忘的记录
某些之前的漏洞的遗忘的记录 前段时间进行了一次WEB方向的面试,我发现我对于很多知识点有不少的欠缺的点,因此,我打算写这次的内容来记录下我没答上或者需要复习一下的知识: PHP反序列化的基础知识: 1.__wakeup()方法绕过方式: __wakeup()是一个特殊的魔术方法,它在对象进行反序列化的时候调用,当然,根据某些POP链的特殊之处,有的时候是放了有一个干扰点在__wak

CSS系列——那些容易被人遗忘的列表属性
在之前我们学过CSS的列表,有有序列表、无序列表、自定义列表,接下来拿无序列表来举例。 1.list-style-image 设置列表项标记的图像(项目符号) 只有一个属性url,引到一个图片 ul{list-style-image:url("images/icon.png");} 示例 用list-style-image重置项目符号示例 .test{list-style-image

【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
针对图像到图像生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据 提出背景如何在不重训练模型的情况下从I2I生成模型中移除特定数据? 超高效的机器遗忘方法子问题1: 如何在图像到图像(I2I)生成模型中进行高效的机器遗忘?子问题2: 如何确定哪些数据需要被遗忘?子问题3: 如何保持对其他数据的记忆不受影响? 评估与效果子问题: 机器遗忘算法如何平衡保留集和遗忘集之间的性能?
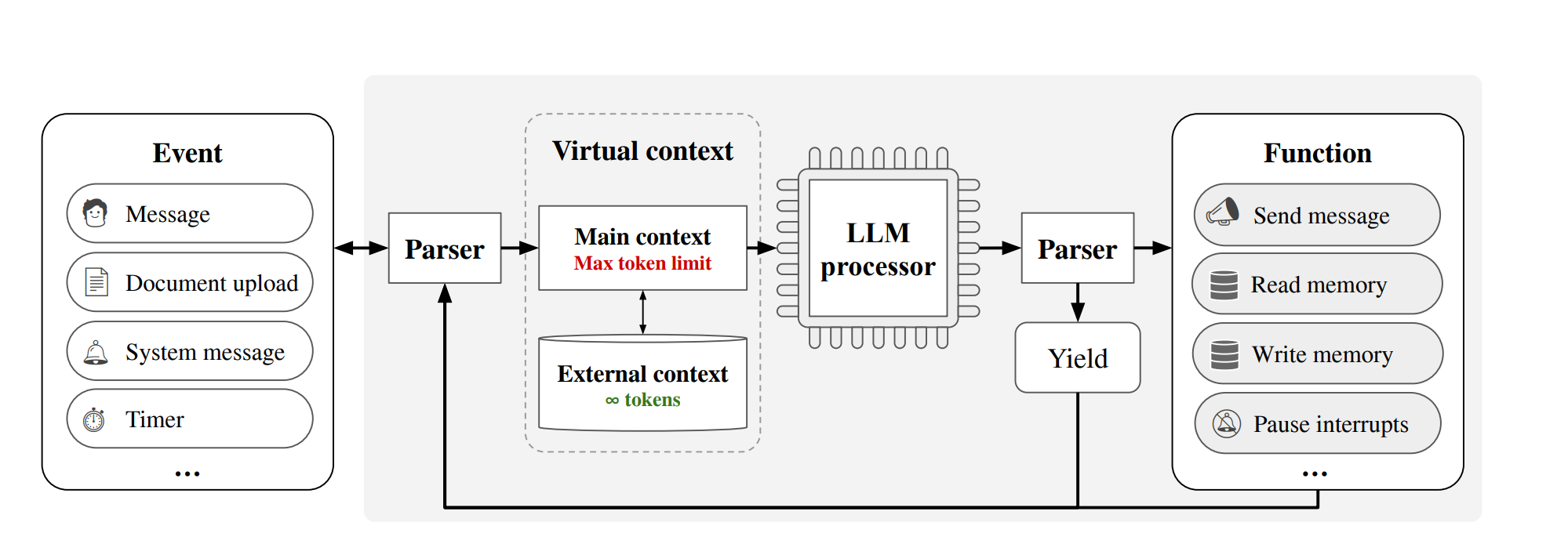
【大模型上下文长度扩展】MedGPT:解决遗忘 + 永久记忆 + 无限上下文
MedGPT:解决遗忘 + 永久记忆 + 无限上下文 问题:如何提升语言模型在长对话中的记忆和处理能力?子问题1:有限上下文窗口的限制子问题2:复杂文档处理的挑战子问题3:长期记忆的维护子问题4:即时信息检索的需求MemGPT 结构图 问题:如何提升语言模型在长对话中的记忆和处理能力? 论文:https://arxiv.org/abs/2310.08560 代码:

大模型增量预训练新技巧:解决灾难性遗忘
大家好,目前不少开源模型在通用领域具有不错的效果,但由于缺乏领域数据,往往在一些垂直领域中表现不理想,这时就需要增量预训练和微调等方法来提高模型的领域能力。 但在领域数据增量预训练或微调时,很容易出现灾难性遗忘现象,也就是学会了垂直领域知识,但忘记了通用领域知识,之前介绍过增量预训练以及领域大模型训练技巧。 今天给大家带来一篇增量预训练方法-Llama-Pro,对LLMs进行Transform
那些年我们遗忘的数学符号
∑:求和符号,西格玛 1 微积分 微分符号:dx 积分符号:∫ 2 复数 复数:z=a+bi. 共轭复数:z*=a-bi.(或者=a-bi) 3 指数和对数 指数:a^n;a的n次幂(a叫做底数,n叫做指数,结果叫幂) 对数:log(a)(b); 定义:如果a的n次幂等于b,则n=log(a)(b)。读作以a为底b的对数。其中a叫底数,b叫真数,结果叫对数。
学会遗忘是一件很容易的事情
此文由 想念沙发的土豆 发表: 当你心里还残存着一点点和好的希望时,你永远都不会忘掉任何有关于她的一切细节!反之,如果你自认为已经没有希望了,或者已经你心里有人来代替她的位置了,那么遗忘就是一件很容易的事情!希望你能看开这些才好! www.SonicChat.com 被你点到死穴了。。。 前些天得知同学和他四年前的GF和好了,好羡慕,不知道人生有多少个4年可以等待。。。。
前端三件套遗忘基础复习(四)
前端三件套遗忘基础复习(一)_江河地笑的博客-CSDN博客 前端三件套遗忘基础复习(二)_江河地笑的博客-CSDN博客 前端三件套遗忘基础复习(三)_江河地笑的博客-CSDN博客 前端三件套遗忘基础复习(四)_江河地笑的博客-CSDN博客 目录 1、处理数组的几个方法 filter 是具有根据条件过滤数组中某些值的作用 map 具有把这个数组转化为另一个数组的作用 reduce 具