本文主要是介绍LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读
导读:该论文比较了LoRA与完全微调在代码与数学两个领域的表现。
背景问题:微调大规模语言模型需要非常大的GPU内存。LoRA这一参数高效微调方法通过仅微调选择性权重矩阵的低秩扰动来节省内存。
解决方案:LoRA假设微调后的权重矩阵的变化可以近似表示成基模型权重矩阵的低秩扰动。LoRA仅微调选择模块的A和B矩阵来学习这个低秩扰动。
核心步骤:实验使用Llama-2语言模型,在代码和数学两个领域下比较LoRA与完全微调。包括继续预训练和指令微调两个训练场景,使用不同数据集和轮数进行训练,并用专业评估指标如HumanEval和GSM8K评估学习效果。
结果和分析:LoRA在代码领域明显劣于完全微调,在数学领域效果更近。但LoRA相对来说遗忘源领域知识较少。LoRA相比常见正则如dropout和权重衰减起到更强的正则作用。完全微调找到的权重扰动秩远大于LoRA配置的秩。
最佳实践:LoRA适用于指令微调,学习率的选择很关键;优先选择所有模块作为目标,以低秩16为妥协。
优势:LoRA相对完全微调节省内存开销,并能在一定程度上保留基模型的广泛能力,避免过分专注于目标领域。
总之,这篇论文系统、全面地比较了LoRA与完全微调在代码和数学领域的表现,提出了LoRA的最佳实践方法。它为参数高效微调提供了有价值的参考。
目录
《LoRA Learns Less and Forgets Less》翻译与解读
Abstract摘要
1 Introduction引言
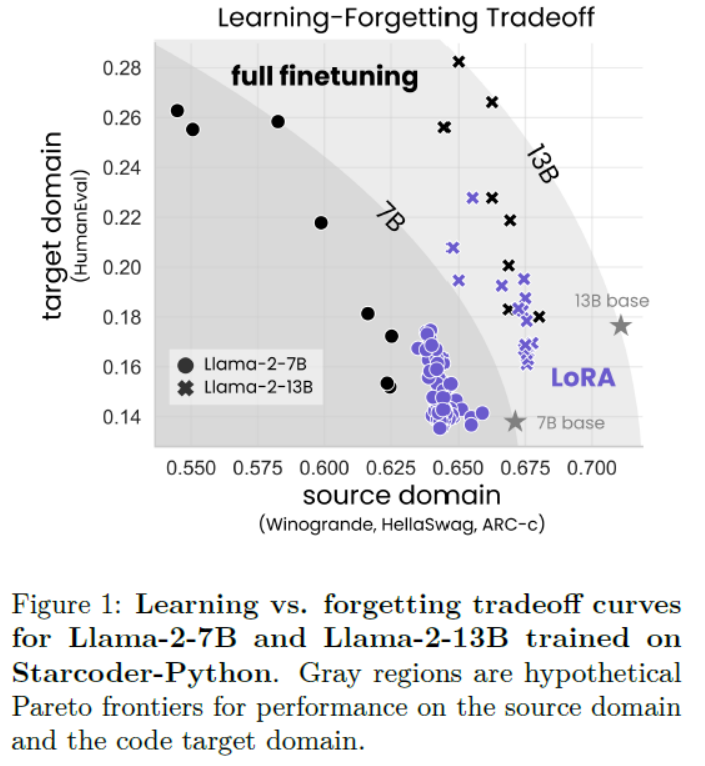
Figure 1: Learning vs. forgetting tradeoff curves for Llama-2-7B and Llama-2-13B trained on Starcoder-Python. Gray regions are hypothetical Pareto frontiers for performance on the source domain and the code target domain.图 1:Llama-2-7B 和 Llama-2-13B 在 Starcoder-Python 上的学习与遗忘权衡曲线。灰色区域是源领域和代码目标领域性能的假设帕累托前沿。
6 Discussion讨论
7 Conclusion结论
《LoRA Learns Less and Forgets Less》翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2405.09673 |
| 时间 | 2024 年 5 月15 日 |
| 作者 | 哥伦比亚大学和Databricks |
Abstract摘要
| Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning (≈100K prompt-response pairs) and continued pretraining (≈10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model’s performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA. | 低秩适应(LoRA)是一种广泛使用的大型语言模型参数高效微调方法。LoRA通过只训练选定的权重矩阵的低秩扰动来节省内存。在这项工作中,我们比较了LoRA和全微调在编程和数学两个目标领域的性能。我们考虑了指令微调(≈100K提示-响应对)和持续预训练(≈10B非结构化令牌)数据制度。我们的结果显示,在大多数设置中,LoRA的性能明显低于全微调。尽管如此,LoRA表现出一种理想的正则化形式:它更好地保持了基础模型在目标领域外任务上的性能。我们表明,与权重衰减和dropout等常见技术相比,LoRA提供了更强的正则化;它还有助于保持更多样化的生成。我们显示,全微调学习的扰动秩比典型的LoRA配置大10-100倍,这可能解释了一些报告的差距。我们最后提出了使用LoRA进行微调的最佳实践。 |
1 Introduction引言
| Finetuning large language models (LLMs) with billions of weights requires a non-trivial amount of GPU memory. Parameter-efficient finetuning methods reduce the memory footprint during training by freezing a pretrained LLM and only training a small number of additional parameters, often called adapters. Low-Rank Adaptation (LoRA; Hu et al. (2021)) trains adapters that are low-rank perturbations to selected weight matrices. Since its introduction, LoRA has been touted as a strict efficiency improvement that does not compromise accuracy on the new, target domain (Hu et al., 2021; Dettmers et al., 2024; Raschka, 2023; Zhao et al., 2024b). However, only a handful of studies benchmark LoRA against full finetuning for LLMs with billions of parameters, (Ivison et al., 2023; Zhuo et al., 2024; Dettmers et al., 2024), reporting mixed results. Some of these studies rely on older models (e.g. RoBERTa), or coarse evaluation benchmarks (such as GLUE or ROUGE) that are less relevant for contemporary LLMs. In contrast, more sensitive domain-specific evaluations, e.g., code, reveal cases where LoRA is inferior to full finetuning (Ivison et al., 2023; Zhuo et al., 2024). Here we ask: under which conditions does LoRA approximate full finetuning accuracy on challenging target domains, such as code and math? | 微调具有数十亿权重的大型语言模型(LLMs)需要大量的GPU内存。参数高效微调方法通过冻结预训练的LLM并仅训练少量附加参数(通常称为适配器)来减少训练期间的内存占用。低秩适配(LoRA;Hu等,2021)训练的适配器是对选定权重矩阵的低秩扰动。 自从引入以来,LoRA被誉为一种严格的效率提升方法,在新目标领域的准确性上没有妥协(Hu等,2021;Dettmers等,2024;Raschka,2023;Zhao等,2024b)。然而,只有少数研究对具有数十亿参数的LLMs进行LoRA与完全微调的基准测试(Ivison等,2023;Zhuo等,2024;Dettmers等,2024),并报告了混合结果。这些研究中有些依赖于较旧的模型(例如RoBERTa)或粗略的评估基准(如GLUE或ROUGE),这些基准对于当代LLMs的相关性较低。相比之下,更敏感的领域特定评估(如代码)显示出LoRA在某些情况下不如完全微调(Ivison等,2023;Zhuo等,2024)。在此,我们提出问题:在何种条件下,LoRA在挑战性的目标领域(如代码和数学)中可以接近完全微调的准确性? |
| By training fewer parameters, LoRA is assumed to provide a form of regularization that constrains the finetuned model’s behavior to remain close to that of the base model (Sun et al., 2023; Du et al., 2024). We also ask: does LoRA act as a regularizer that mitigates “forgetting” of the source domain? In this study, we rigorously compare LoRA and full finetuning for Llama-2 7B (and in some cases, 13B) models across two challenging target domains, code and mathematics. Within each domain, we explore two training regimes. The first is instruction finetuning, the common scenario for LoRA involving question-answer datasets with tens to hundreds of millions of tokens. Here, we use Magicoder-Evol-Instruct-110K (Wei et al., 2023)and MetaMathQA (Yu et al., 2023). The second regime is continued pretraining, a less common application for LoRA which involves training on billions of unlabeled tokens; here we use the StarCoder-Python (Li et al., 2023) and OpenWebMath (Paster et al., 2023) datasets (Table 1). | 通过训练较少的参数,LoRA被认为提供了一种正则化形式,使微调模型的行为保持接近基础模型(Sun等,2023;Du等,2024)。我们还问:LoRA是否作为一种正则化工具,可以减轻对源领域的“遗忘”? 在本研究中,我们严格比较了LoRA和完全微调在Llama-2 7B(某些情况下为13B)模型在代码和数学这两个挑战性目标领域中的表现。在每个领域中,我们探索了两种训练方式。第一种是指令微调,这是一种涉及数千万到数亿个标记的问题回答数据集的常见LoRA场景。在这里,我们使用Magicoder-Evol-Instruct-110K(Wei等,2023)和MetaMathQA(Yu等,2023)。第二种方式是持续预训练,这是LoRA不常见的应用,涉及数十亿个未标记的标记的训练;在这里,我们使用StarCoder-Python(Li等,2023)和OpenWebMath(Paster等,2023)数据集(表1)。 |
| We evaluate target-domain performance (henceforth, learning) via challenging coding and math benchmarks (HumanEval; Chen et al. (2021), and GSM8K; Cobbe et al. (2021)). We evaluate source-domain forgetting performance on language understanding, world knowledge, and common-sense reasoning tasks (Zellers et al., 2019; Sakaguchi et al., 2019; Clark et al., 2018). We find that for code, LoRA substantially underper-forms full finetuning, whereas for math, LoRA closes more of the gap (Sec. 4.1), while requiring longer training. Despite this performance gap, we show that LoRA better maintains source-domain performance compared to full finetuning (Sec. 4.2). Furthermore, we characterize the tradeoff between performance on the target versus source domain (learning ver-sus forgetting). For a given model size and dataset, we find that LoRA and full finetuning form a simi-lar learning-forgetting tradeoff curve: LoRA’s that learn more generally forget as much as full finetun-ing, though we find cases (for code) where LoRA can learn comparably but forgets less (Sec. 4.3). | 我们通过挑战性的代码和数学基准(HumanEval;Chen等,2021,以及GSM8K;Cobbe等,2021)评估目标领域的性能(以下简称学习)。我们在语言理解、世界知识和常识推理任务上评估源领域遗忘性能(Zellers等,2019;Sakaguchi等,2019;Clark等,2018)。 我们发现,对于代码,LoRA明显不如完全微调,而对于数学,LoRA缩小了更多差距(第4.1节),尽管需要更长的训练时间。尽管存在性能差距,我们显示出LoRA在保持源领域性能方面比完全微调更好(第4.2节)。此外,我们刻画了目标域与源域性能之间的权衡(学习与遗忘)。对于给定的模型大小和数据集,我们发现LoRA和完全微调形成了类似的学习-遗忘权衡曲线:LoRA的学习越多,一般遗忘也与完全微调一样多,尽管我们发现某些情况下(对于代码)LoRA可以学习得相当,但遗忘更少(第4.3节)。 |
| We then show that LoRA – even with a less restric-tive rank – provides stronger regularization when compared to classic regularization methods such as dropout (Srivastava et al., 2014), and weight decay (Goodfellow et al., 2016). We also show that LoRA provides regularization at the output level: we ana-lyze the generated solutions to HumanEval problems and find that while full finetuning collapses to a lim-ited set of solutions, LoRA maintains a diversity of solutions more similar to the base model (Sun et al., 2023; Du et al., 2024). Why does LoRA underperform full finetuning? LoRA was originally motivated in part by the hypothesis that finetuning results in low-rank perturbations to the base model’s weight matrix (Li et al., 2018; Aghajanyan et al., 2020; Hu et al., 2021). However, the tasks explored by these works are relatively easy for modern LLMs, and certainly easier than the coding and math domains studied here. Thus, we perform a singular value decomposition to show that full finetuning barely changes the spectrum of the base model’s weight matrices, and yet the difference between the two (i.e. the perturbation) is high rank. The rank of the perturbation grows as training progresses, with ranks 10-100× higher than typical LoRA configurations (Figure 7). | 然后我们展示了LoRA——即使在不太限制的秩下——与经典的正则化方法(如dropout(Srivastava等,2014)和权重衰减(Goodfellow等,2016))相比,提供了更强的正则化。我们还展示了LoRA在输出级别提供的正则化:我们分析了对HumanEval问题生成的解决方案,发现虽然完全微调收敛到一组有限的解决方案,但LoRA保持了与基础模型更相似的解决方案多样性(Sun等,2023;Du等,2024)。 为什么LoRA的表现不如完全微调?LoRA的初衷部分是基于这样一个假设:微调导致基础模型权重矩阵的低秩扰动(Li等,2018;Aghajanyan等,2020;Hu等,2021)。然而,这些工作的任务对于现代LLMs来说相对容易,肯定比我们这里研究的代码和数学领域容易。因此,我们进行了奇异值分解,显示完全微调几乎没有改变基础模型权重矩阵的谱,但两者之间的差异(即扰动)是高秩的。随着训练的进展,扰动的秩增长,通常比典型的LoRA配置高10-100倍(图7)。 |
| We conclude by proposing best practices for training models with LoRA. We find that LoRA is especially sensitive to learning rates, and that the performance is affected mostly by the choice of target modules and to a smaller extent by rank. To summarize, we contribute the following results: • Full finetuning is more accurate and sample-efficient than LoRA in code and math (Sec.4.1). • LoRA forgets less of the source domain, providing a form of regularization (Sec. 4.2 and 4.3). • LoRA’s regularization is stronger compared to common regularization techniques; it also helps maintaining the diversity of generations (Sec. 4.4). • Full finetuning finds high rank weight perturbations (Sec. 4.5). • Compared to full finetuning, LoRA is more sensitive to hyperparameters, namely learning rate, target modules, and rank (in decreasing order; Sec. 4.6) . | 最后,我们提出了使用LoRA训练模型的最佳实践。我们发现LoRA对学习率特别敏感,性能主要受目标模块选择的影响,程度较小的影响来自秩。 总结来说,我们贡献了以下结果: >> 完全微调在代码和数学上比LoRA更准确且样本效率更高(第4.1节)。 >> LoRA对源领域遗忘较少,提供了一种正则化形式(第4.2节和第4.3节)。 >> LoRA的正则化比常见的正则化技术更强;它还帮助维持生成的多样性(第4.4节)。 >> 完全微调找到了高秩权重扰动(第4.5节)。 >> 与完全微调相比,LoRA对超参数更敏感,即学习率、目标模块和秩(按递减顺序;第4.6节)。 |
Figure 1: Learning vs. forgetting tradeoff curves for Llama-2-7B and Llama-2-13B trained on Starcoder-Python. Gray regions are hypothetical Pareto frontiers for performance on the source domain and the code target domain.图 1:Llama-2-7B 和 Llama-2-13B 在 Starcoder-Python 上的学习与遗忘权衡曲线。灰色区域是源领域和代码目标领域性能的假设帕累托前沿。
6 Discussion讨论
| Does the difference between LoRA and full finetuning decrease with model size? Studies in the past have hinted at a relationship between the effectiveness of finetuning and model size (Aghajanyan et al., 2020; Hu et al., 2021; Zhuo et al., 2024). While recent studies have successfully applied LoRA to 70B parameter models (Ivison et al., 2023; Yu et al., 2023), we leave a rigorous study of these intriguing scaling properties to future work. | LoRA与全微调之间的差异是否随着模型大小的增加而减少?过去的研究暗示了微调有效性与模型大小之间的关系(Aghajanyan et al., 2020; Hu et al., 2021; Zhuo et al., 2024)。虽然最近的研究已成功将LoRA应用于70B参数模型(Ivison et al., 2023; Yu et al., 2023),但我们把对这些迷人扩展性质的严格研究留作未来工作。 |
| Limitations of the spectral analysis. The observation that full finetuning tends to find high rank solutions does not rule out the possibility of low-rank solutions; rather, it shows that they are not typically found. An alternative interpretation is that the rank needed to reconstruct the weight matrix is higher than the rank needed for a downstream task. | 谱分析的局限性。全微调倾向于找到高秩解的观察结果并不排除低秩解的可能性;相反,这表明它们通常不被发现。另一种解释是,重构权重矩阵所需的秩比下游任务所需的秩要高。 |
| Why does LoRA perform well on math and not code? One hypothesis is that math datasets involve a smaller domain shift; they include a larger percentage of English and lead to decreased forgetting. The second hypothesis is that the GSM8K evaluation is too easy and does not capture the new college-level math learned in finetuning. | 为什么LoRA在数学上表现良好而在代码上不行?一种假设是数学数据集涉及的领域转移较小;它们包含更大比例的英语,导致遗忘减少。第二个假设是GSM8K评估太简单,无法捕捉到微调中学习的新大学级数学。 |
7 Conclusion结论
| This work sheds light on the downstream performance of contemporary LLMs (with 7 and 13 billion parameters) trained with LoRA. Different from most prior work, we use domain-specific datasets in code and math, associated with sensitive evaluation metrics. We show that LoRA underperforms full finetuning in both domains. We also show that LoRA keeps the finetuned model’s behavior close to that of the base model, with diminished source-domain forgetting and more diverse generations at inference time. We investigate LoRA’s regularization properties, and show that full finetuning finds weight perturbations are far from being low-rank. We conclude by analyzing LoRA’s increased sensitivity to hyperparameters and highlighting best practices. | 这项工作揭示了使用LoRA训练的当代LLM(具有70亿和130亿参数)的下游性能。与大多数先前工作不同,我们使用与代码和数学相关的领域特定数据集,并关联敏感的评估指标。我们显示LoRA在这两个领域中的性能都低于全微调。我们还显示LoRA保持了微调模型的行为接近基础模型,减少了源领域遗忘,并在推理时产生更多样化的生成。我们调查了LoRA的正则化属性,并显示全微调发现的权重扰动远非低秩。我们最后分析了LoRA对超参数的敏感性增加,并强调了最佳实践。 |
这篇关于LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







