lesslora专题
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读
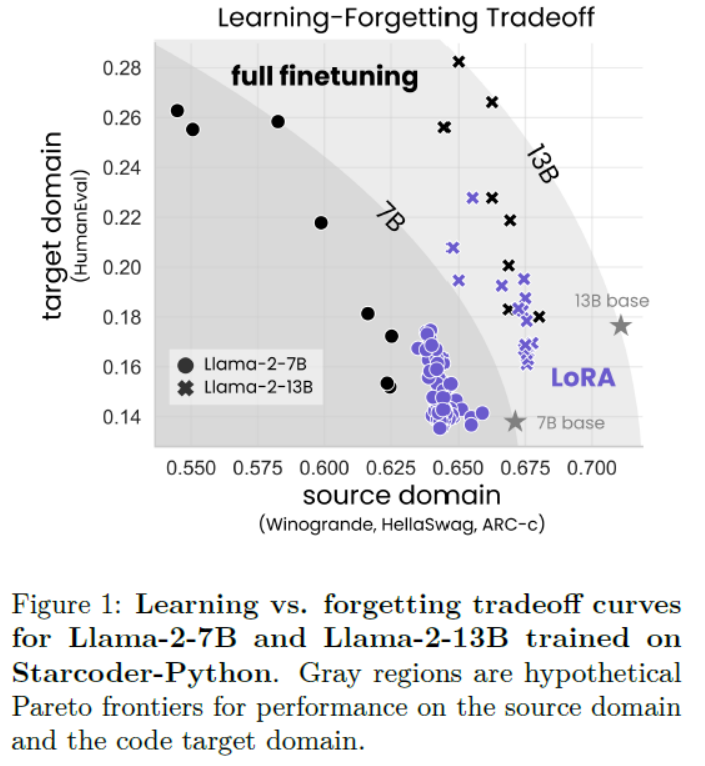
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读 导读:该论文比较了LoRA与完全微调在代码与数学两个领域的表现。 背景问题:微调大规模语言模型需要非常大的GPU内存。LoRA这一参数高效微调方法通过仅微调选择性权重矩阵的低秩扰动来节省内存。 解决方案:LoRA假设微调后的权重矩阵的变化可以近