学得专题
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读
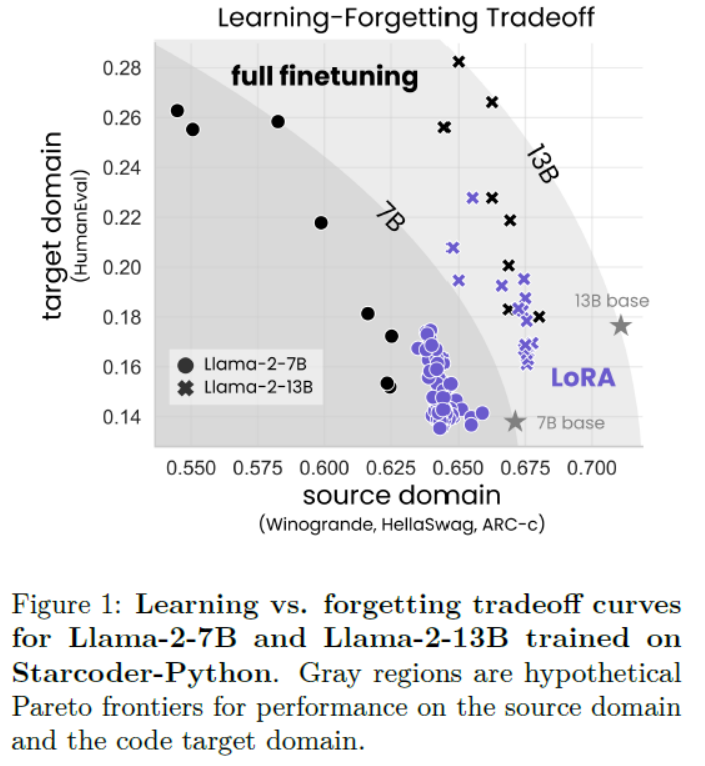
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读 导读:该论文比较了LoRA与完全微调在代码与数学两个领域的表现。 背景问题:微调大规模语言模型需要非常大的GPU内存。LoRA这一参数高效微调方法通过仅微调选择性权重矩阵的低秩扰动来节省内存。 解决方案:LoRA假设微调后的权重矩阵的变化可以近

附2007春季课表!欢迎大家对我的课程提问题!谢谢大家的建议批评和鼓励!!!我会努力去做得更好,希望你们学得更好!!!
材控: 周三1-2,D9C501; 环境:周四1-2, D12J2401;
但凡早知道这 28 个网站,都不至于学得那么不扎实
今天来给大家推荐28个辅助你学习巩固知识的网站,让你边玩边学边记! 本文大致的目录结构如下: CSS相关的学习网站JavaScript相关的学习网站其它学习网站 因为这些网站大多都是国外的大佬们做的,所以网页大多都是英文,为了更好地使用,给你们推荐两个翻译的方式: 使用Chrome浏览器自带的翻译功能,可以中英随意切换 chrome浏览器自带的翻译功能 下一个"Google 翻译"插件,遇到

2016-10-11要想学得精,必须得多看书
大神说得很对,做任何事情,要想做得精,应该首先懂其原理,把基础的一定要掌握得牢牢的,这样才能让你提升得更快!!!前两天借了一本【JavaScript高级程序设计】,是时候拿出来看看了,许多大神都推荐的书,说明是真的好!!【CSS禅意花园】、【***权威指南】【语言精粹】【全能指南】——还有啥的记不太清了 我前段时间关注了一个微信公众号,叫做“web前端开发”;在这个公众号上面推送了几篇前端图书的

工行数据中心项目管理辅导经验总结和推广——培训学得理念,辅导改变行为
2014年5月8日,常耀俊老师和某银行数据中心中高层领导对前期项目管理辅导工作进行了总结。此次项目管理辅导是继大规模项目管理普及培训之后组织的针对性项目经理项目管理技能全面提升的辅导,由常务副总黄总发起,常老师亲自挂帅操刀实施。 辅导项目分两个阶段。第一阶段是项目计划制定的辅导,包括项目范围计划、进度计划、沟通计划和风险计划的制定,由催化师指导项目组完成项目计划并通过验收;第二阶段是项目实施

技术学得好,老婆加班少!
国庆本来打算好好休息下的,没想到第一天就被领导的电话叫醒,说微信服务挂了,抓紧修复。 mmp… 这就是我老婆的第一天假期,问题修复后,老婆心有余悸,一直手动在那测试微信服务,就是往他们公众号发个消息,看是不是能够正常返回。 我看着心疼,立志要用技术手段实现微信接口的巡检。 我先捋了下思路,技术实现的话,大概需要解决如下几个问题: 1、微信后台接口如何测试? 2、如何用 Python
任正非说:就IPD来说,学得明白就上岗,学不明白就撤掉。
你好!这是华研荟【任正非说】系列的第35篇文章,让我们聆听任正非先生的真知灼见,学习华为的管理思想和管理理念。 一、公司所有流程的改革一定要为客户服务,为客户服务产生价值,凡是绕了一大弯、不产生价值的流程都要砍掉。 来源于任正非先生2014年在华为行政流程责任制试点进展汇报会上的讲话。 道理非常简单,客户要求的是直接、简单并带来价值,而不是花里胡哨,看起来不明觉厉的东西。哪个企业能真
Spring Data JPA想要学得好,缓存机制掌握好
文章目录 Spring Data JPA想要学得好,缓存机制掌握好Hibernate、JPA与Spring Data JPA之间的关系JPA的EntityManager接口与Hibernate的Session接口Hibernate的缓存Hibernate的一级缓存(Session的缓存)浅读缓存源码解密缓存过程Hibernate的一级缓存(Session的缓存)的作用同步缓存中的对象Flus

数学不好 学得好java,数学不好,学习Java会不会特别困难?
数学不好,学习Java会不会特别困难?以下文字资料是由(历史新知网www.lishixinzhi.com)小编为大家搜集整理后发布的内容,让我们赶快一起来看一下吧! 数学不好,学习JAVA编程的时候会不会有困难? 这个看情况了 有的人也是数学不好 学编程的时候一点也没问题 有的人就不行了 关键自己学习的时候还得多努力 多问。多练习。 我的数学不好,学习心理学会不会有点困难? 正因为你数学不好你