peft专题

AI大模型优化技巧:参数高效微调(PEFT)与LoRA微调深度解析
1. Fine-tuning 相较于基础大模型动辄万卡的代价,微调可能是普通个人或者企业少数能够接受的后训练大模型(post-training)的方式。 微调是指在一个预训练模型(pre-training)的基础上,通过少量的数据和计算资源,对模型进行进一步训练,以适应特定的任务或者数据集。 微调分为两种类型:全参微调(full fine-tuning)和参数高效微调(parameter

神经网络微调技术全解(01)-不同的微调方法如PEFT、SFT、LoRa、QLoRa等,旨在解决不同的问题和挑战
微调技术在深度学习和大模型的应用中起到了关键作用。不同的微调方法如PEFT、SFT、LoRa、QLoRa等,旨在解决不同的问题和挑战。以下是它们的简介及各自解决的问题。 1. PEFT (Parameter-Efficient Fine-Tuning) 问题:在处理大规模预训练模型时,全面微调所有参数会消耗大量计算资源和存储空间。对于一些特定任务,全面微调可能不必要,并且可能导致过拟合。

基于huggingface peft进行qwen1.5-7b-chat训练/推理/服务发布
一、huggingface peft微调框架 1、定义 PEFT 是一个为大型预训练模型提供多种高效微调方法的Python库。 微调传统范式是针对每个下游任务微调模型参数。大模型参数总量庞大,这种方式变得极其昂贵和不切实际。PEFT采用的高效做法是训练少量提示参数(Prompt Tuning)或使用低秩适应(LORA)等重新参数化方法来减少微调时训练参数的数量。 二、qwen-1.5b-c

【机器学习】QLoRA:基于PEFT亲手微调你的第一个AI大模型
目录 一、引言 二、量化与微调—原理剖析 2.1 为什么要量化微调? 2.2 量化(Quantization) 2.2.1 量化原理 2.2.2 量化代码 2.3 微调(Fine-Tuning) 2.3.1 LoRA 2.3.2 QLoRA 三、量化与微调—实战演练:以Qwen2为例,亲手微调你的第一个AI大模型 3.1 模型预处理—依赖安装、库包导入、模型下载 3

5.大模型高效微调(PEFT)未来发展趋势
PEFT 主流技术分类 UniPELT 探索PEFT 大模型的统一框架(2022) UIUC 和Meta AI 研究人员发表的UniPELT 提出将不同的PEFT 方法模块化。 通过门控机制学习激活最适合当前数据或任务的方法,尤其是最常见的3大类PEFT 技术: AdaptersSoft PromptsReparametrization-based 作者试图将已经被广泛证明有效的技术,
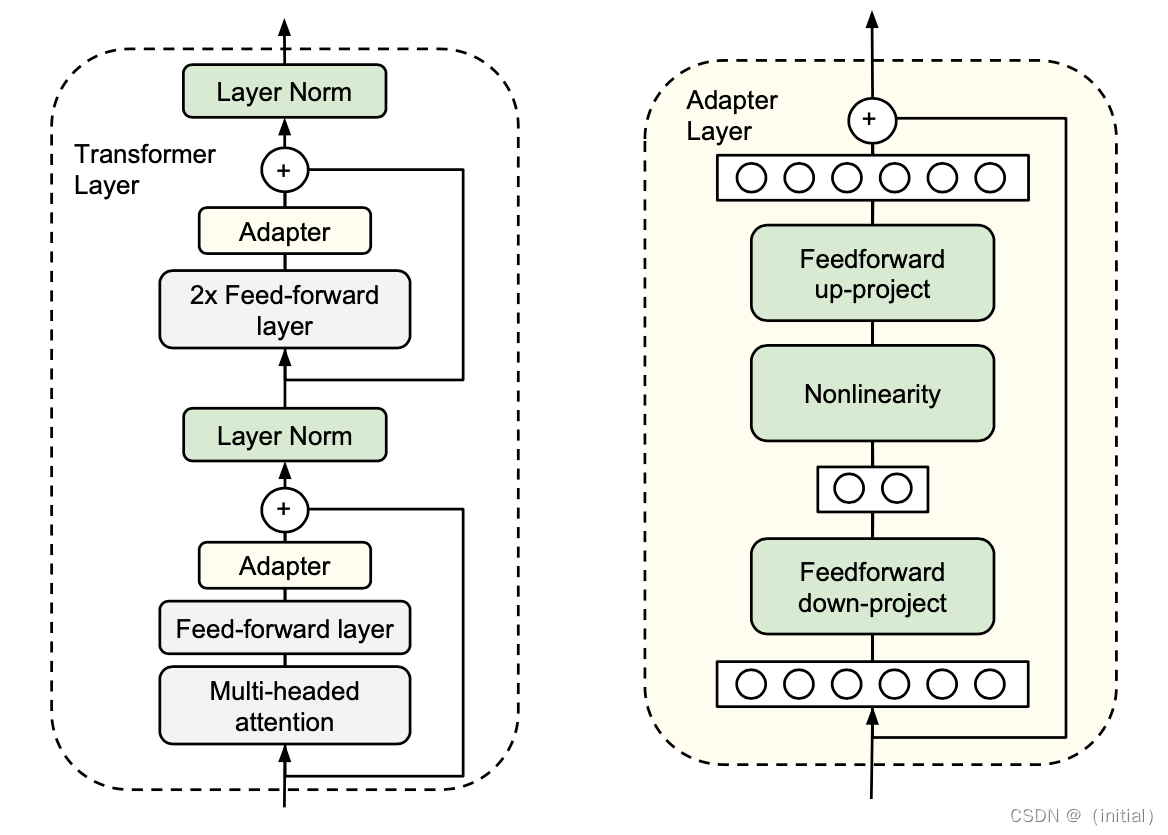
3.大模型高效微调PEFT
大模型高效微调(PEFT)技术 预训练模型的背景 预训练与微调:传统的微调方法通常涉及对整个预训练模型的参数进行再训练,以适应特定任务。这虽然有效,但计算成本高,且需要大量的标记数据。模型结构:像BERT或GPT这样的模型通常包含数亿甚至数十亿个参数,构成一个深层次的Transformer网络。 Before PEFT: in-context learning (prompt) Be
大模型PEFT(二) 之 大模型LoRA指令微调学习记录
1.peft 1.1 微调方法批处理大小模式GPU显存速度 1.2 当前高效微调技术存在的一些问题 当前的高效微调技术很难在类似方法之间进行直接比较并评估它们的真实性能,主要的原因如下所示: 参数计算口径不一致:参数计算可以分为三类: 可训练参数的数量、微调模型与原始模型相比改变的参数的数量、微调模型和原始模型之间差异的等级。例如,DiffPruning更新0.5%的参数,但是实际
【模型参数微调】最先进的参数高效微调 (PEFT) 方法
简介 由于大型预训练模型的规模,微调大型预训练模型的成本通常高得令人望而却步。参数高效微调 (PEFT) 方法只需微调少量(额外)模型参数而不是所有模型参数,即可使大型预训练模型有效地适应各种下游应用。这大大降低了计算和存储成本。最近最先进的PEFT技术实现了与完全微调的模型相当的性能。 PEFT 与 Transformers 集成,可轻松进行模型训练和推理,与 Diffusers 集成,方便

参数高效微调PEFT(二)快速入门P-Tuning、P-Tuning V2
参数高效微调PEFT(二)快速入门P-Tuning、P-Tuning V2 参数高效微调PEFT(一)快速入门BitFit、Prompt Tuning、Prefix Tuning 今天,我们继续了解下来自清华大学发布的两种参数高效微调方法P-Tuning和P-Tuning v2。可以简单的将P-Tuning是认为针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix

AIGC笔记--基于PEFT库使用LoRA
1--相关讲解 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS LoRA 在 Stable Diffusion 中的三种应用:原理讲解与代码示例 PEFT-LoRA 2--基本原理 固定原始层,通过添加和训练两个低秩矩阵,达到微调模型的效果; 3--简单代码 import torchimport t
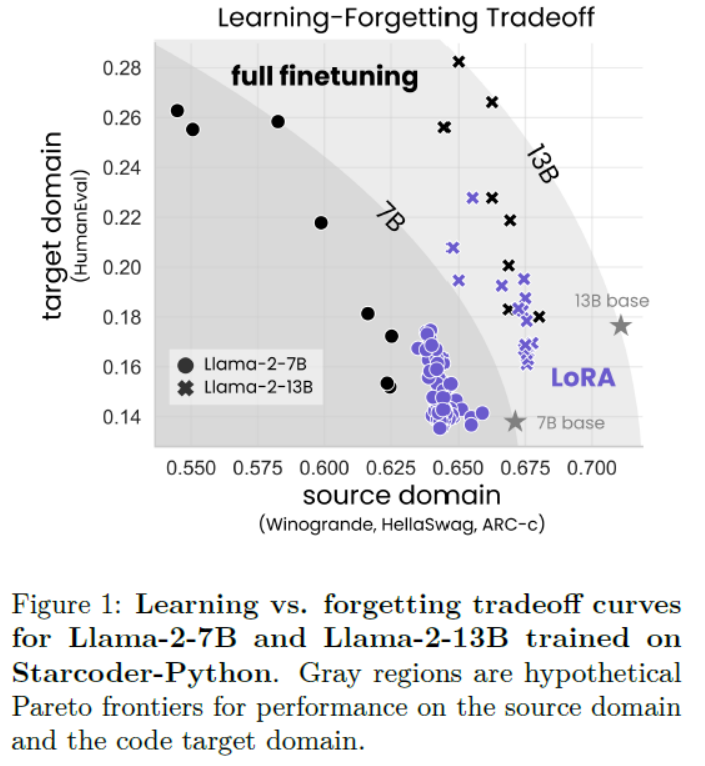
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读
LLMs之PEFT之Llama-2:《LoRA Learns Less and Forgets LessLoRA学得更少但遗忘得也更少》翻译与解读 导读:该论文比较了LoRA与完全微调在代码与数学两个领域的表现。 背景问题:微调大规模语言模型需要非常大的GPU内存。LoRA这一参数高效微调方法通过仅微调选择性权重矩阵的低秩扰动来节省内存。 解决方案:LoRA假设微调后的权重矩阵的变化可以近
llama-factory/peft微调千问1.5-7b-chat
目标 使用COIG-CQIA数据集和通用sft数据集对qwen1.5-7b-chat进行sft微调,使用公开dpo数据集进行dpo对齐。学习千问的长度外推方法。 一、训练配置 使用Lora方式, 将lora改为full即可使用全量微调。 具体的参数在 该框架将各个参数、训练配置都封装好了,直接使用脚本,将数据按格式传入即可。 自定义数据集格式:https://github.com/hiy

大模型微调PEFT调优
大模型微调PEFT调优 论文 Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment 论文讨论了参数高效微调方法在预训练语言模型中的应用,尤其是针对计算资源有限环境下的大型语言模型(LLMs)。随着基于Transformer的PLMs参数数
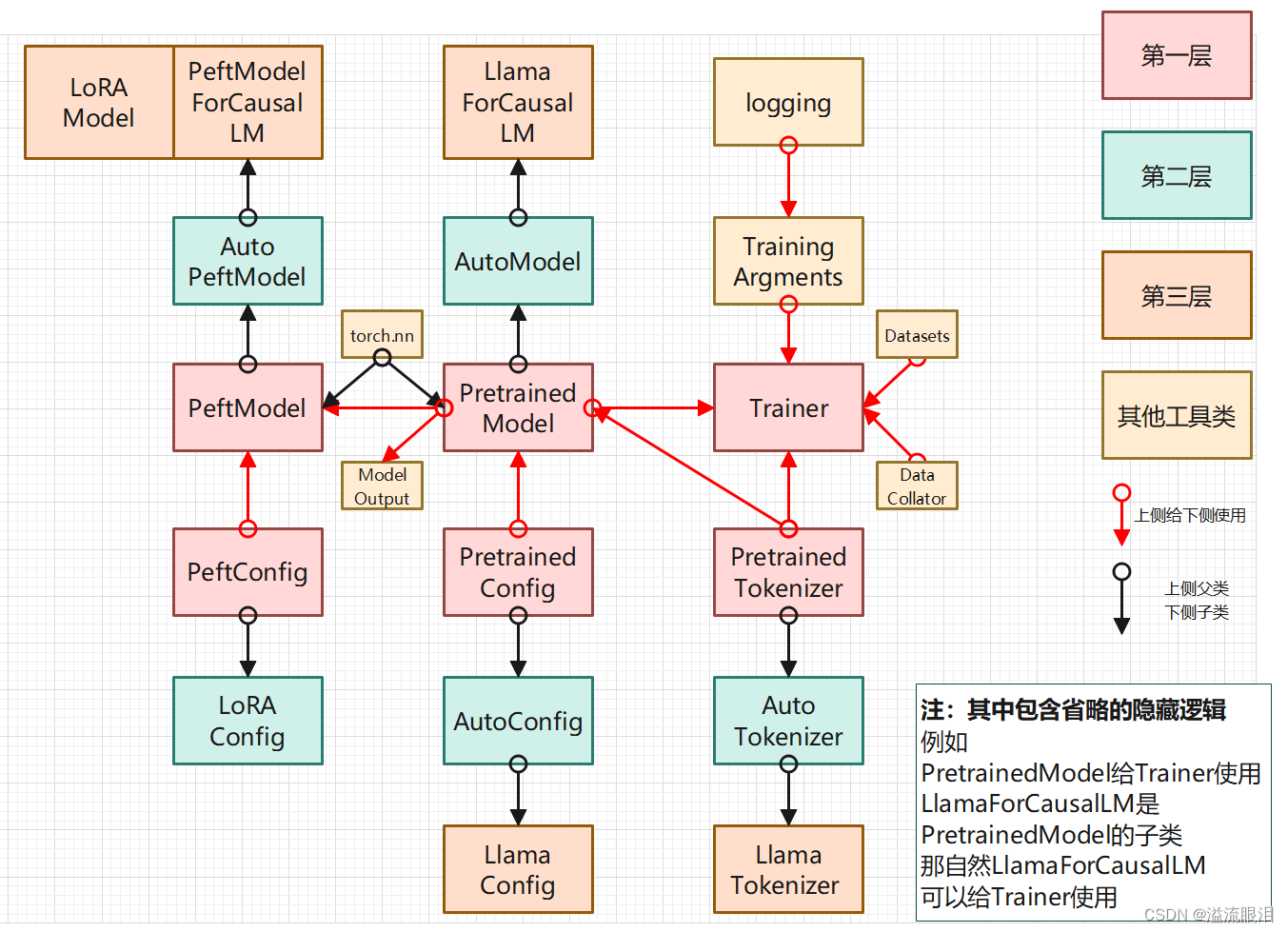
【Python】科研代码学习:十二 PEFT(高效参数的训练,Adapter适配器)
【Python】科研代码学习:十二 PEFT PEFT简单训练教程简单推理教程Adapter 适配器Merge Adapter 架构关系 PEFT 【HF官网-Doc-PEFT:API】 首先日常问题,是什么,为什么,怎么用 PEFT (Prameter-Efficient Fine-Tuning):参数高效的微调 这里特指 HF 提供的 PEFT 库 PEFT 让大的预训练模型

peft模型微调--Prompt Tuning
模型微调(Model Fine-Tuning)是指在预训练模型的基础上,针对特定任务进行进一步的训练以优化模型性能的过程。预训练模型通常是在大规模数据集上通过无监督或自监督学习方法预先训练好的,具有捕捉语言或数据特征的强大能力。 PEFT(Parameter-Efficient Fine-Tuning)是一种针对大模型微调的技术,其核心思想是在保持大部分预训练模型参数不变的基础上,仅对一小部分额
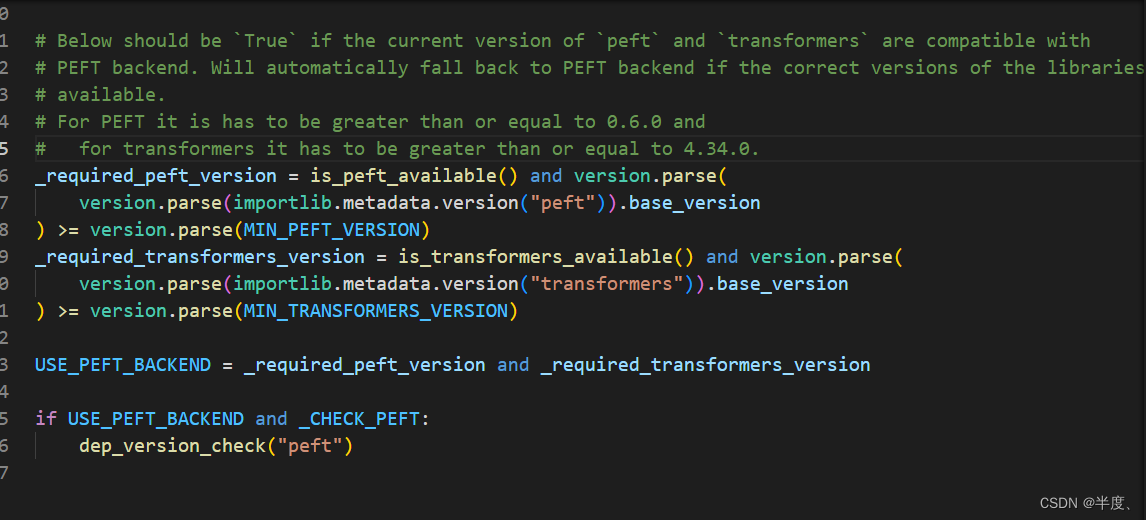
ValueError: PEFT backend is required for this method.
根据异常栈发现USE_PEFT_BACKEND是False导致的 if not USE_PEFT_BACKEND:raise ValueError("PEFT backend is required for this method.") 找到定义此变量文件,PEFT >=0.6 and transformers >= 4.34.0 解决方法 升级包 pip install -U PE

Py之peft:peft(一款最先进的参数高效微调方法库)的简介、安装、使用方法之详细攻略
Py之peft:peft(一款最先进的参数高效微调方法库)的简介、安装、使用方法之详细攻略 目录 peft的简介 1、支持多种微调方法 2、支持多种模型及其场景 (1)、因果语言建模 (2)、条件生成 (3)、序列分类 (4)、标记分类 (5)、文本到图像生成 (6)、图像分类 (7)、图像到文本(多模型) (8)、语义分割 3、使用案例 (1)、通过使用消费者

PEFT概述:最先进的参数高效微调技术
了解参数高效微调技术,如LoRA,如何利用有限的计算资源对大型语言模型进行高效适应。 PEFT概述:最先进的参数高效微调技术 什么是PEFT什么是LoRA用例使用PEFT训练LLMs入门PEFT配置4位量化封装基础Transformer模型保存模型加载模型推理 结论 什么是PEFT 随着大型语言模型(LLMs)如GPT-3.5、LLaMA2和PaLM2在规模上不断扩大,对它们在
《实验细节》使用PEFT库常见错误
《实验细节》使用PEFT库常见错误 安装问题常用命令使用问题问题1 安装问题 首先给出用到的网站 更新NVIDIA网站 https://www.nvidia.com/Download/index.aspx 2. 使用PEFT的优秀demo https://www.philschmid.de/fine-tune-flan-t5-peft 3.
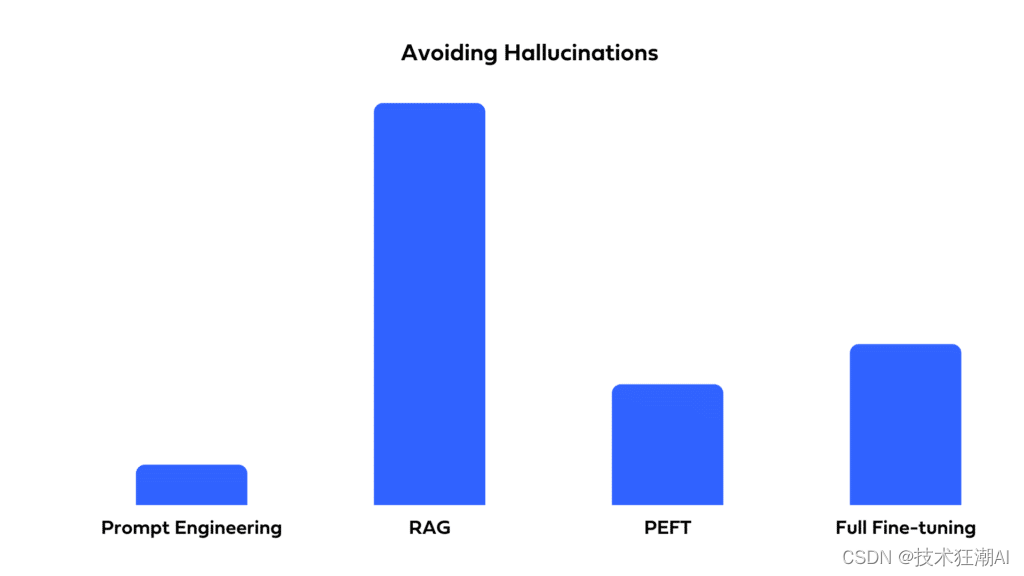
如何选择最适合你的LLM优化方法:全面微调、PEFT、提示工程和RAG对比分析
一、前言 自从ChatGPT问世以来,全球各地的企业都迫切希望利用大型语言模型(LLMs)来提升他们的产品和运营。虽然LLMs具有巨大的潜力,但存在一个问题:即使是最强大的预训练LLM也可能无法直接满足你的特定需求。其原因如下: 定制输出:你可能需要一个具有独特结构或风格的应用程序,例如可以评分并提供简洁反馈点评文章质量的工具。 缺少上下文:预训练LLM可能对于你应用程序中重要文件一无所知
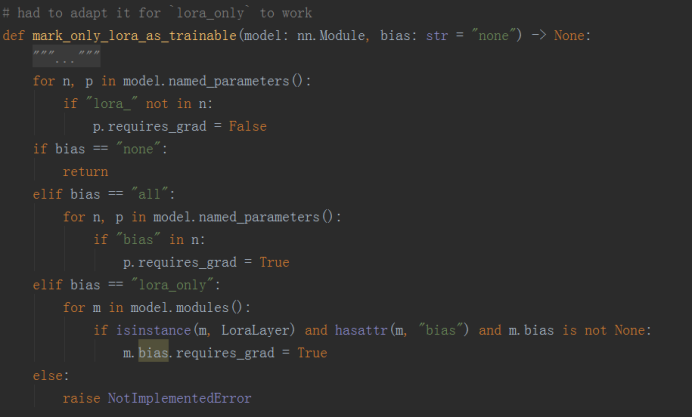
hugging face参数高效微调peft源码解析
大模型参数高效微调(PEFT) - 知乎 让天下没有难Tuning的大模型-PEFT技术简介 - 知乎 大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2 - 知乎 你似乎来到了没有知识存在的荒原 - 知乎 大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT - 知乎 GitHub - huggingface/peft: 🤗 PEF

ValueError: Please specify `target_modules` in `peft_config`解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了ValueError: Plea