本文主要是介绍3.大模型高效微调PEFT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型高效微调(PEFT)技术
预训练模型的背景
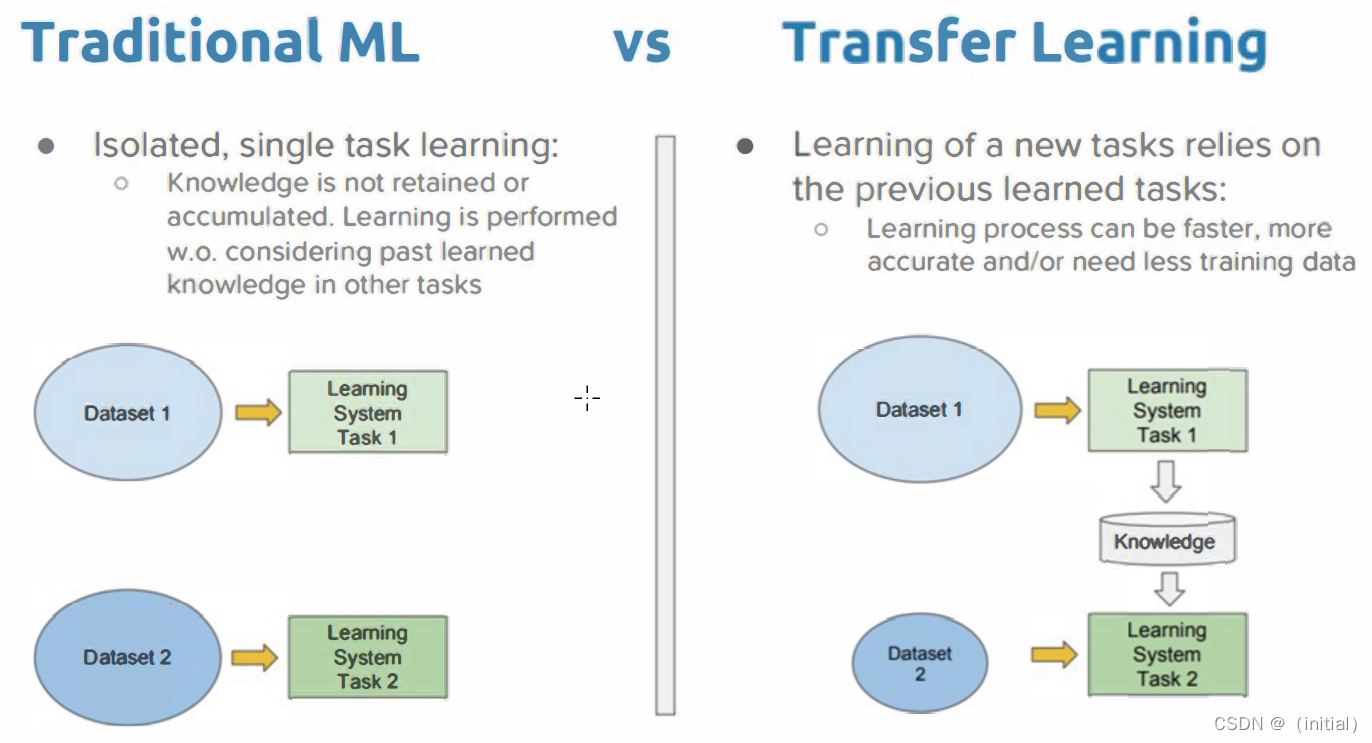
- 预训练与微调:传统的微调方法通常涉及对整个预训练模型的参数进行再训练,以适应特定任务。这虽然有效,但计算成本高,且需要大量的标记数据。
- 模型结构:像BERT或GPT这样的模型通常包含数亿甚至数十亿个参数,构成一个深层次的Transformer网络。
Before PEFT: in-context learning (prompt)
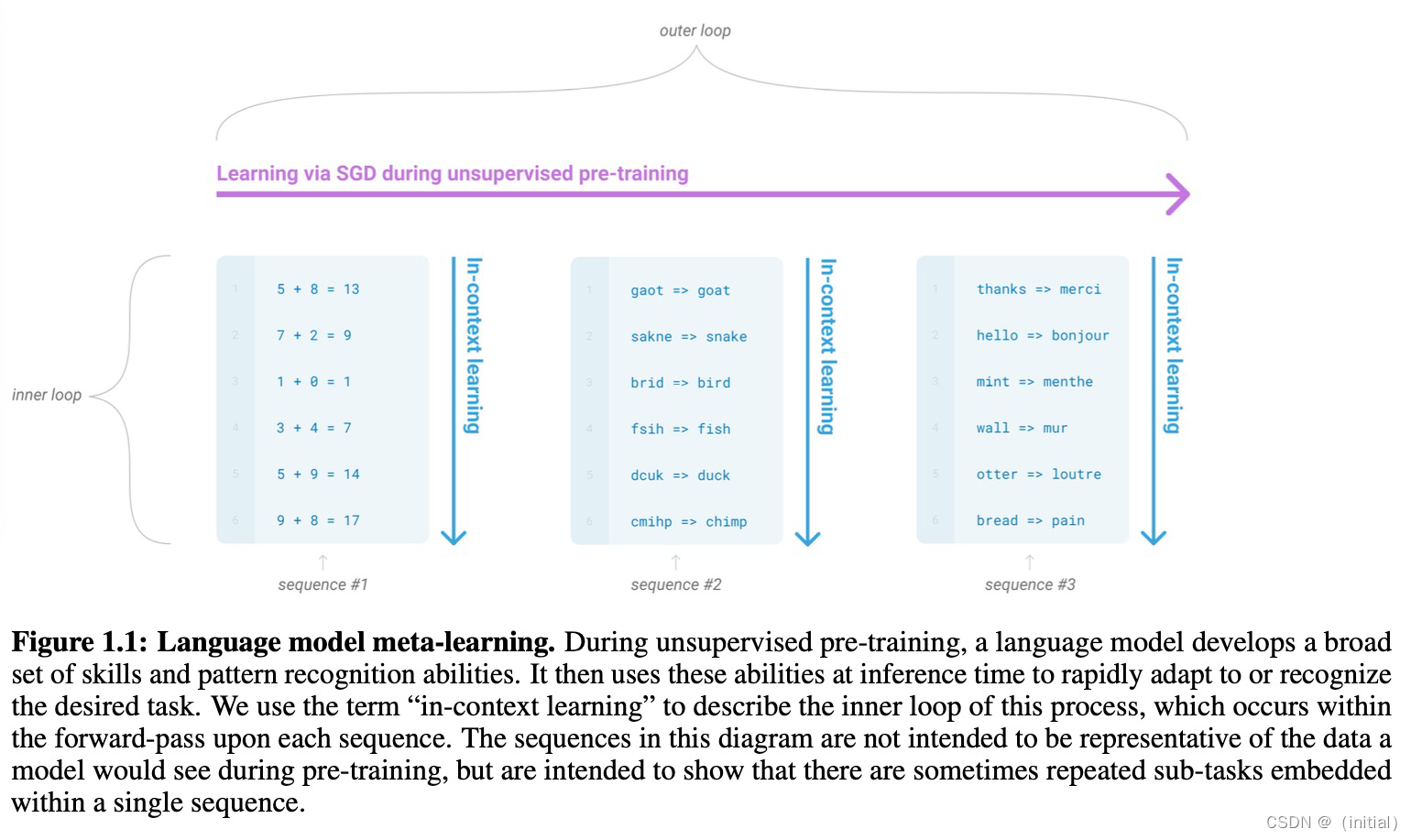
Before PEFT: Hard Prompt
Before PEFT: Hard Prompt for text2image (Made by SD XL)
Before PEFT: Hard Prompt for text2image (Made by SD XL)
Before PEFT: Hard Prompt for text2image (Made by Midjourney)
Before PEFT: Hard Prompt for text2image (Made by DALL·E 3)
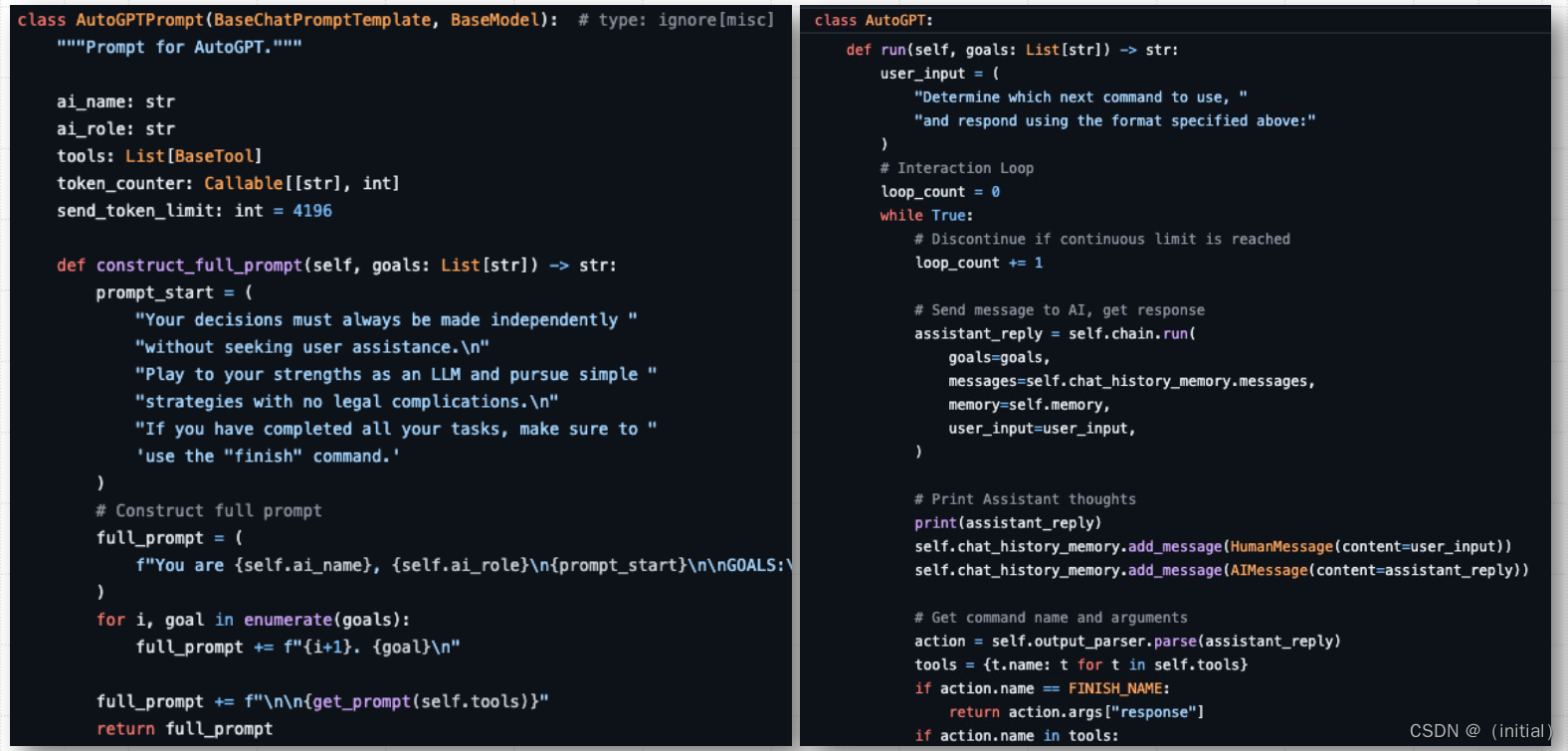
Before PEFT: Prompt Template for AutoGPT (Made by LangChain)
有更好的方法吗?
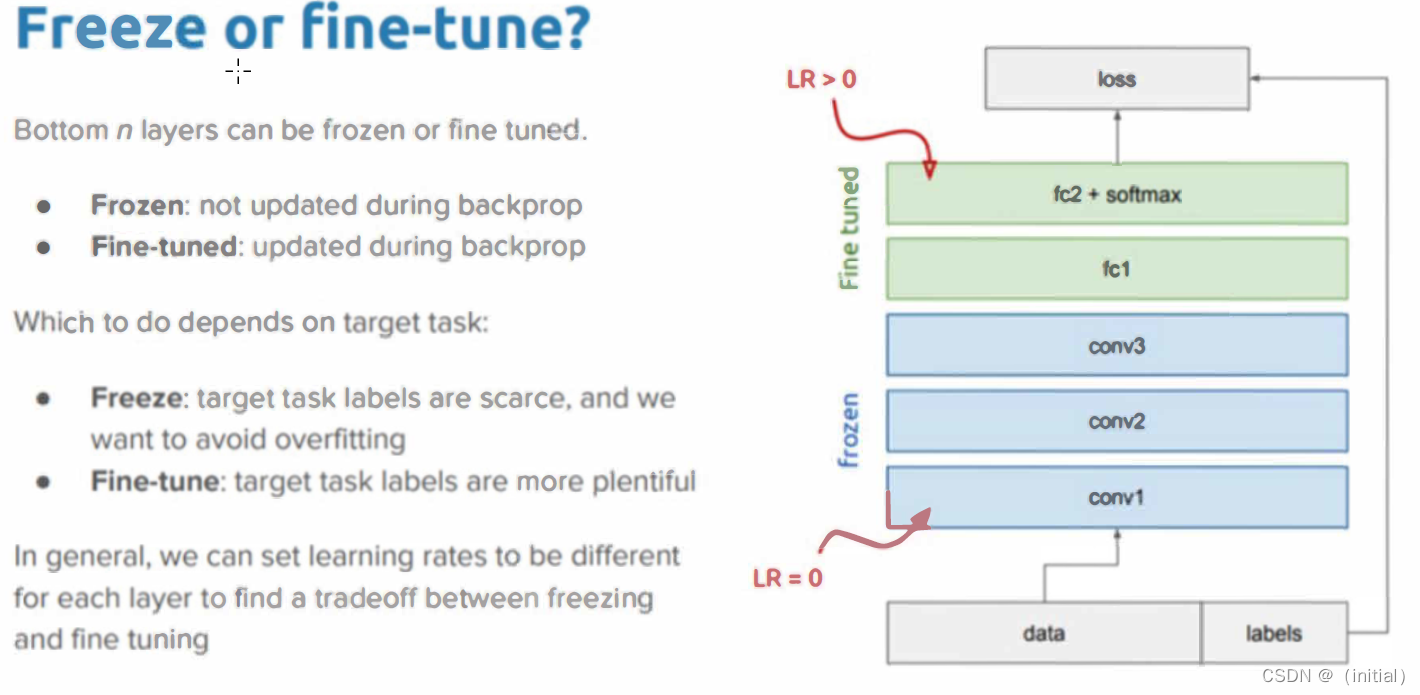
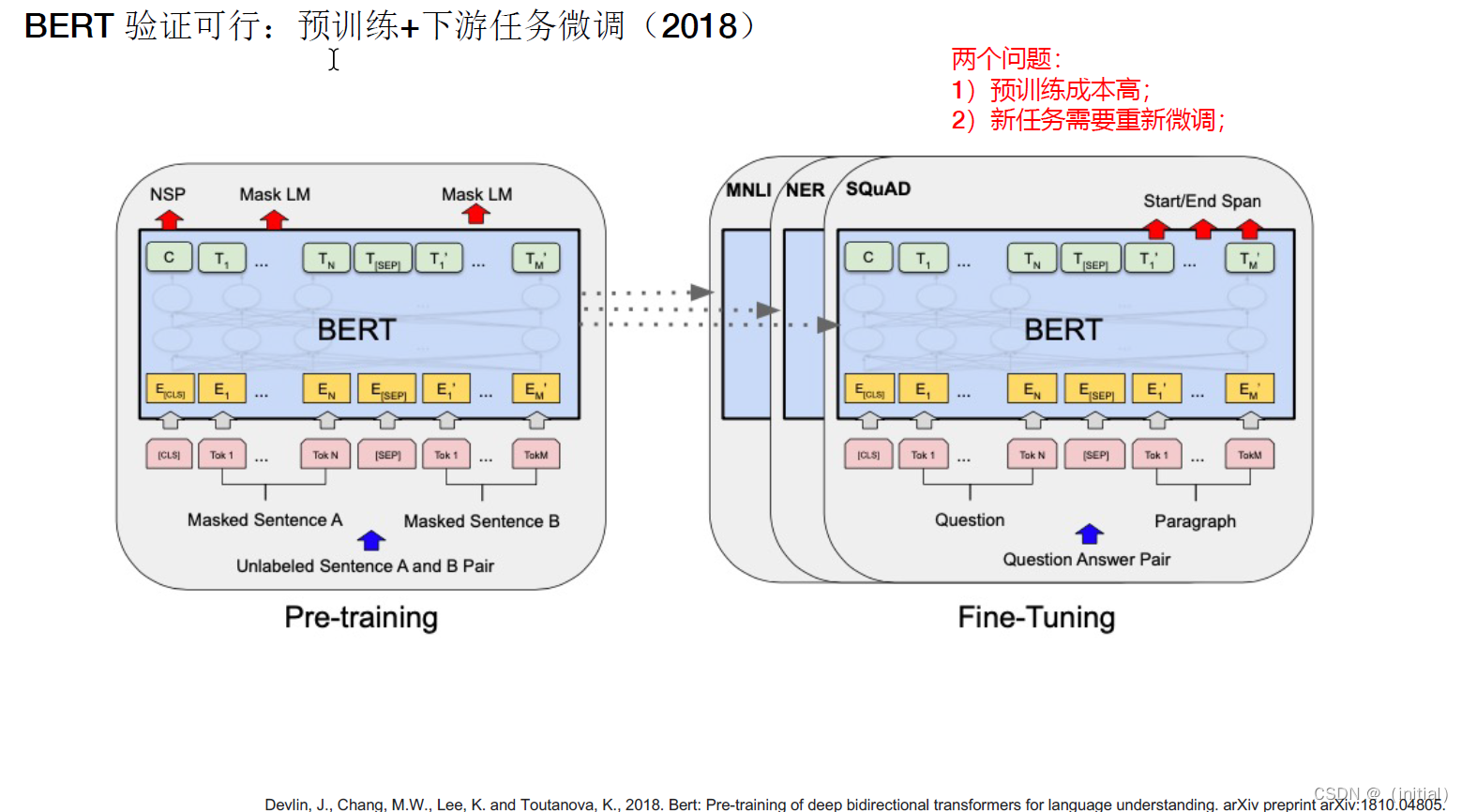
Adapter Tuning: 开启大模型PEFT (2019)
Adapter Tuning 是一种相对较新的神经网络微调方法,特别适用于大型预训练模型(如BERT、GPT等)。它在保持预训练模型结构和参数大部分不变的前提下,通过引入额外的小型网络模块(称为"adapters")来调整模型以适应特定的下游任务。
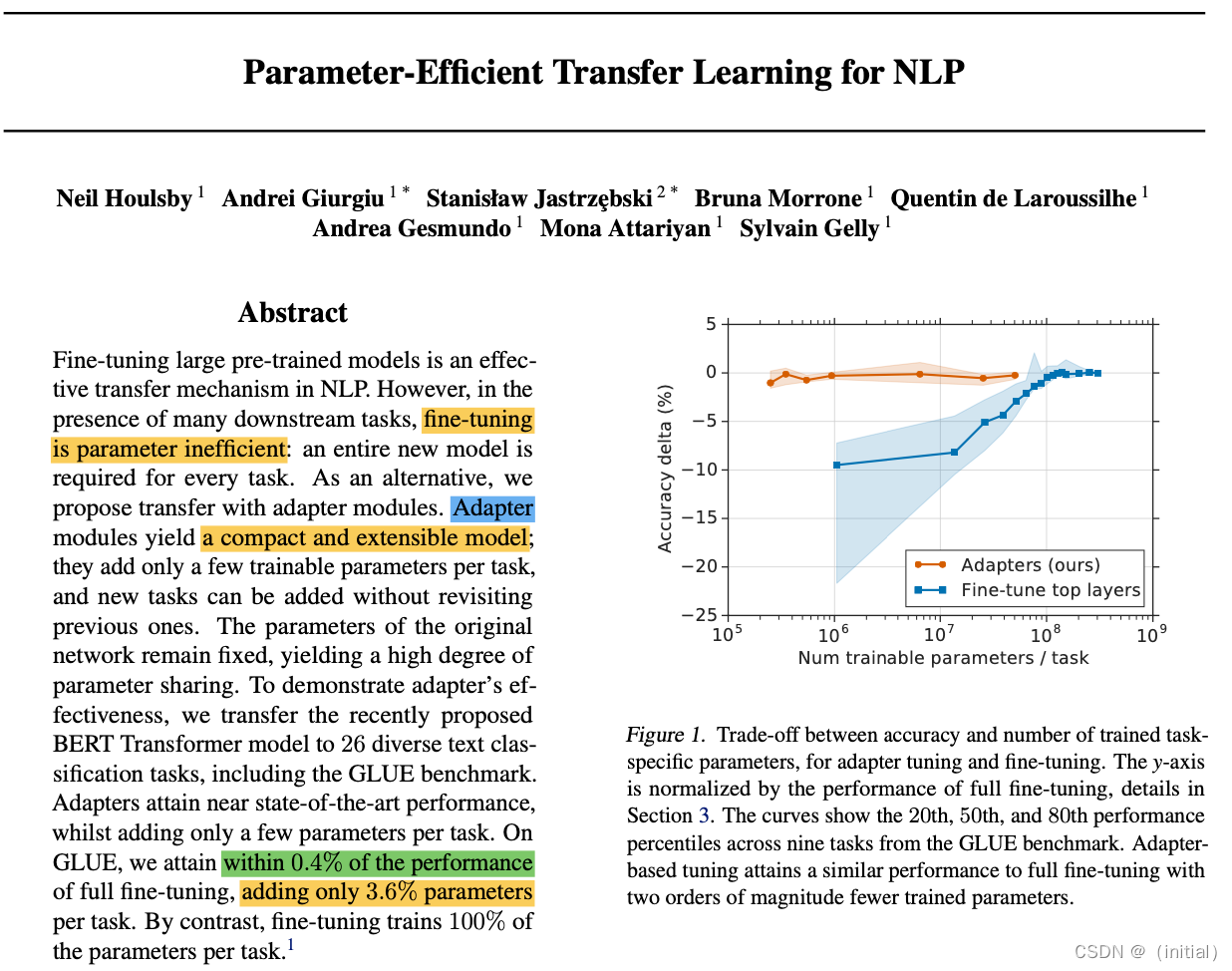
Adapter Tuning 的核心原理
- Adapter模块:Adapter Tuning 在模型的每个层(或特定层)中插入小型的神经网络模块(Adapters)。这些模块相对简单,参数量少。
- 参数固定:除了这些Adapter模块外,模型的其他所有预训练参数都保持固定不变。
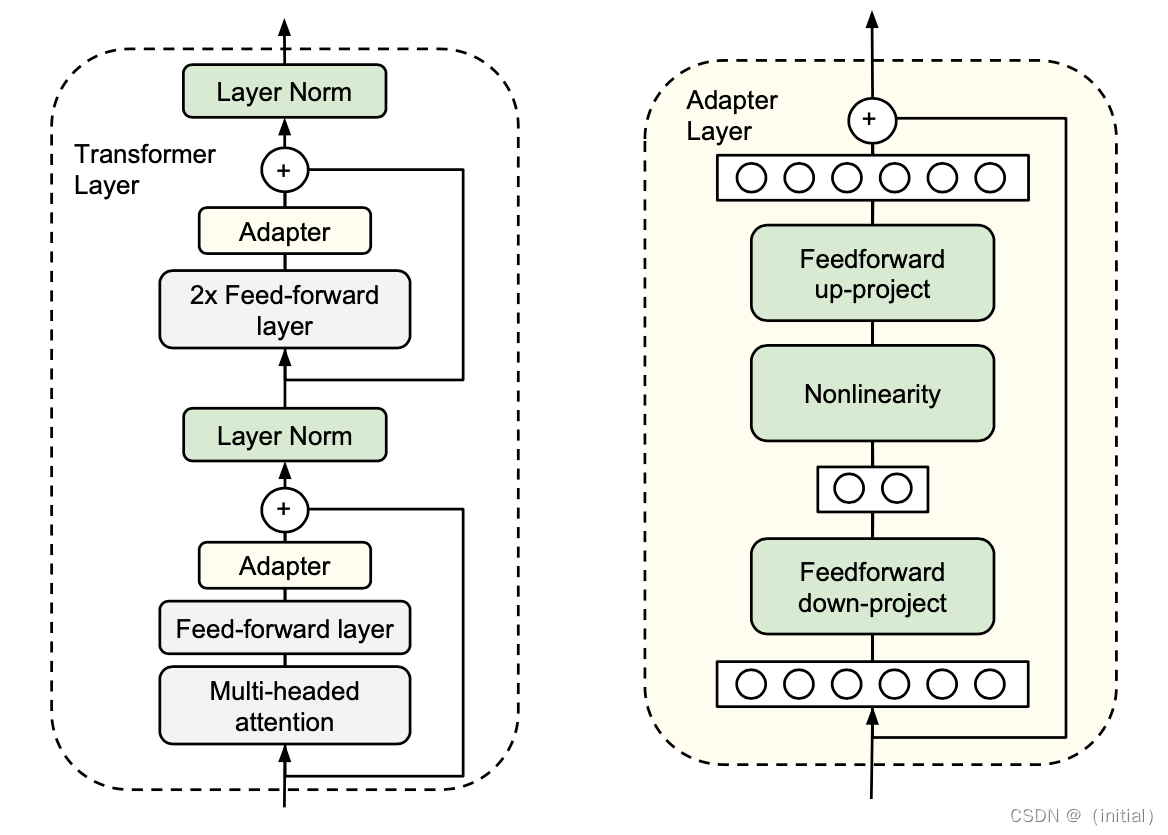
Adapter Tuning 的实现
- 训练Adapter:在微调过程中,只有Adapter模块的参数被更新。这些模块学习从预训练模型的固定表示中提取对特定任务有用的信息。
- 灵活性:由于Adapters相对较小,它们可以快速地针对不同的任务进行训练和调整。
- 效率:与传统的全模型微调相比,Adapter Tuning 需要更少的计算资源和训练时间。
应用和优势
- 任务特定调整:Adapter Tuning 使得模型能够针对特定任务进行有效的调整,而不需要重新训练整个大型模型。
- 资源节约:由于只训练Adapters,这种方法
这篇关于3.大模型高效微调PEFT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







