本文主要是介绍hugging face参数高效微调peft源码解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型参数高效微调(PEFT) - 知乎
让天下没有难Tuning的大模型-PEFT技术简介 - 知乎
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2 - 知乎
你似乎来到了没有知识存在的荒原 - 知乎
大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT - 知乎
GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.
ChatGPT等大模型高效调参大法——PEFT库的算法简介 - 知乎
PEFT
PEFT:Parameter Efficient Fine-Tuning技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
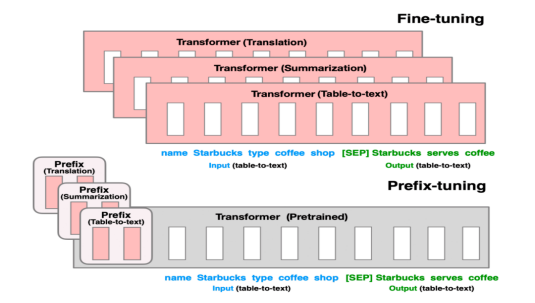
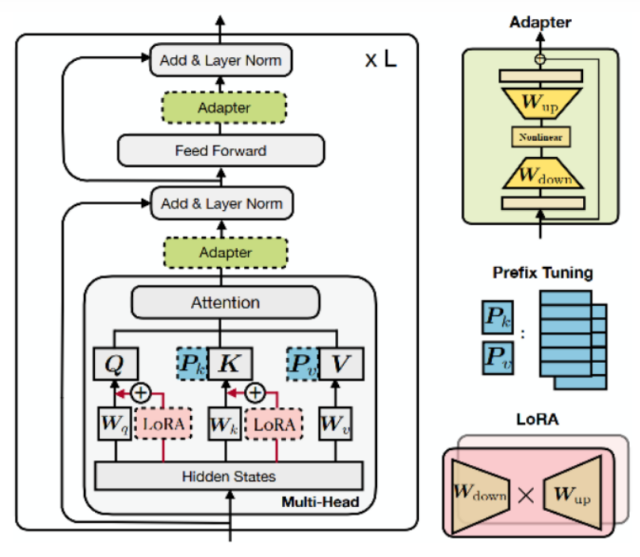
Prefix-Tuning(软提示/连续提示)
- 在每一层的token之前构造一段任务相关的tokens作为Prefix,训练时只更新Prefix部分的参数,而Transformer中的其他部分参数固定
- 一个Prefix模块就是一个可学习的id到embedding映射表,可以在多层分别添加Prefix模块
- 为了防止直接更新Prefix的参数导致训练不稳定的情况,在Prefix层前面加了MLP结构
- 作用阶段:所有transformer block的Attention注意力计算
Prompt-Tuning(软提示/连续提示)
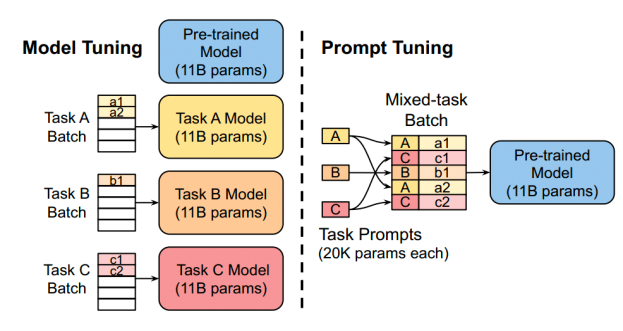
- 可看做是Prefix-Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整
- 提出 Prompt Ensembling 方法来集成预训练语言模型的多种 prompts
- 在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果
- 作用阶段:第一层transformer block的Attention注意力计算
P-Tuning(软提示/连续提示)
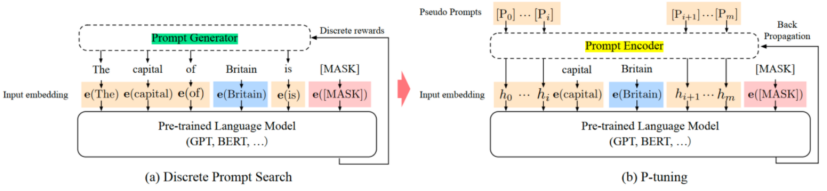
- P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP对prompt embedding序列进行编码
- 根据人工设计模板动态确定prompt token的添加位置,可以放在开始,也可以放在中间
- 作用阶段:第一层transformer block的Attention注意力计算
P-Tuning V2(软提示/连续提示)
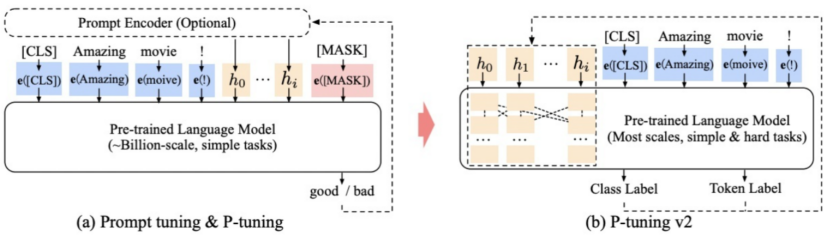
- 可看做是Prefix-Tuning的优化版本。在模型的每一层都添加连续的 prompts
- P-Tuning v2在不同规模和任务中都可与微调效果相媲美
- 移除重参数化的编码器(如:Prefix Tuning中的MLP、P-Tuning中的LSTM)、针对不同任务采用不同的提示长度、引入多任务学习等
- 作用阶段:所有transformer block的Attention注意力计算
Adapter(变体:AdapterFusion、AdapterDrop)
- 在Transformer Block中加入两层MLP,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调
- 在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果
- 作用阶段:Transformer Block主体

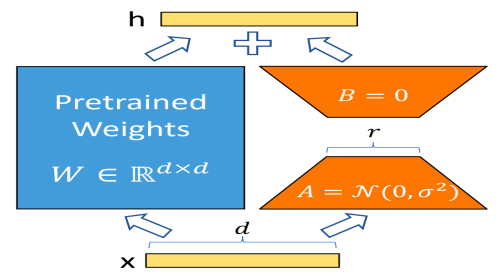
LoRA(变体:AdaLoRA、QLoRA)
- 在训练阶段,预训练参数W固定,只更新A和B参数,A和B模拟W的变化量。
- 在推理阶段,用A、B参数与原预训练参数相加替换原有预训练模型的参数。推理过程没有额外的参数量和计算量
- 相当于是用LoRA去模拟Full-finetune的过程,几乎不会带来效果损失
- 由于没有使用Prompt方式,避免了Prompt方法的一系列问题(Prompt的问题:难训练、序列长度受限、效果不如finetune),在推理阶段也没有引入额外的参数
- 作用阶段:Transformer Block主体query、value
BitFit
- 不需要对预训练模型做任何改动,只微调训练指定神经网络中的偏置Bias
- 参数量只有不到2%,但是效果可以接近全量参数
- 作用阶段:模型Backbone主体
PEFT方法总结
- 增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体
- 选取一部分参数更新,如:BitFit
- 引入重参数化,如:LoRA、AdaLoRA、QLoRA
- 混合高效微调,如:MAM Adapter、UniPELT
由于peft更在快速开发迭代中,代码变动可能会比较大,本文相关代码来自于peft的0.3.0版本。
下面看一下hugging face peft开源代码中对于上述几种方法的实现。tuners目录下实现了PrefixTuning、PromptTuning、PTuning、Adapter、LoRA、AdaLoRA这些方法配置文件的构造、解析,新增训练参数模型的构造,各种PEFT方法配置文件类之间的继承关系,如下:
PeftConfig -> PromptLearningConfig -> (PrefixTuningConfig、PromptEncoderConfig、PromptTuningConfig)PeftConfig -> LoraConfig -> AdaLoraConfigPushToHubMixin -> PeftConfigMixin -> PeftConfig下面先看一下PrefixTuning、PromptTuning、PTuningV1模块的输入、输出情况:
Prefix-Tuning
PrefixEncoder(
(embedding): Embedding(20, 18432)
)
在每一层transformer block的key和value的前面都加上virtual embedding,2 * layers * hidden = 2 * 12 * 768 = 18432,其中2就对应key和value
from peft import PrefixEncoder, PrefixTuningConfig
import torchconfig = PrefixTuningConfig(peft_type="PREFIX_TUNING",task_type="SEQ_2_SEQ_LM",num_virtual_tokens=20,token_dim=768,num_transformer_submodules=1,num_attention_heads=12,num_layers=12,encoder_hidden_size=768,prefix_projection=False
)
print(config)# 初始化PrefixEncoder
prefix_encoder = PrefixEncoder(config)
print(prefix_encoder)
Prompt-Tuning
PromptEmbedding(
(embedding): Embedding(20, 768)
)
只在输入层的原始序列上面添加prompt embedding
from peft import PromptTuningConfig, PromptEmbedding
import torchword_embedding = torch.nn.Embedding(num_embeddings=100, embedding_dim=768)
config = PromptTuningConfig(peft_type="PROMPT_TUNING",task_type="SEQ_2_SEQ_LM",num_virtual_tokens=20,token_dim=768,num_transformer_submodules=1,num_attention_heads=12,num_layers=12,# encoder_hidden_size=768
)
print(config)# 初始化PromptEncoder
prompt_encoder = PromptEmbedding(config, word_embedding)
print(prompt_encoder)
PTuningV1
PromptEncoder(
(embedding): Embedding(20, 768)
(mlp_head): Sequential(
(0): Linear(in_features=768, out_features=768, bias=True)
(1): ReLU()
(2): Linear(in_features=768, out_features=768, bias=True)
(3): ReLU()
(4): Linear(in_features=768, out_features=768, bias=True)
)
)
只在输入层的原始序列上面添加prompt embedding,并且使用了MLP加强学习能力
from peft import PromptEncoderConfig, PromptEncoder
import torchconfig = PromptEncoderConfig(peft_type="PREFIX_TUNING",task_type="SEQ_2_SEQ_LM",num_virtual_tokens=20,token_dim=768,num_transformer_submodules=1,num_attention_heads=12,num_layers=12,encoder_hidden_size=768,# prefix_projection=False
)
print(config)# 初始化PrefixEncoder
p_encoder = PromptEncoder(config)
print(p_encoder)
PTuningV2
PrefixEncoder(
(embedding): Embedding(20, 768)
(transform): Sequential(
(0): Linear(in_features=768, out_features=768, bias=True)
(1): Tanh()
(2): Linear(in_features=768, out_features=18432, bias=True)
)
)
与PrefixTuning一样(实际上也是使用同一个类来实现的),在每一层transformer block的key和value的前面都加上virtual embedding,2 * layers * hidden = 2 * 12 * 768 = 18432,2对应的就是key和value
from peft import PrefixEncoder, PrefixTuningConfig
import torchconfig = PrefixTuningConfig(peft_type="PREFIX_TUNING",task_type="SEQ_2_SEQ_LM",num_virtual_tokens=20,token_dim=768,num_transformer_submodules=1,num_attention_heads=12,num_layers=12,encoder_hidden_size=768,prefix_projection=True
)
print(config)# 初始化PrefixEncoder
prefix_encoder = PrefixEncoder(config)
print(prefix_encoder)
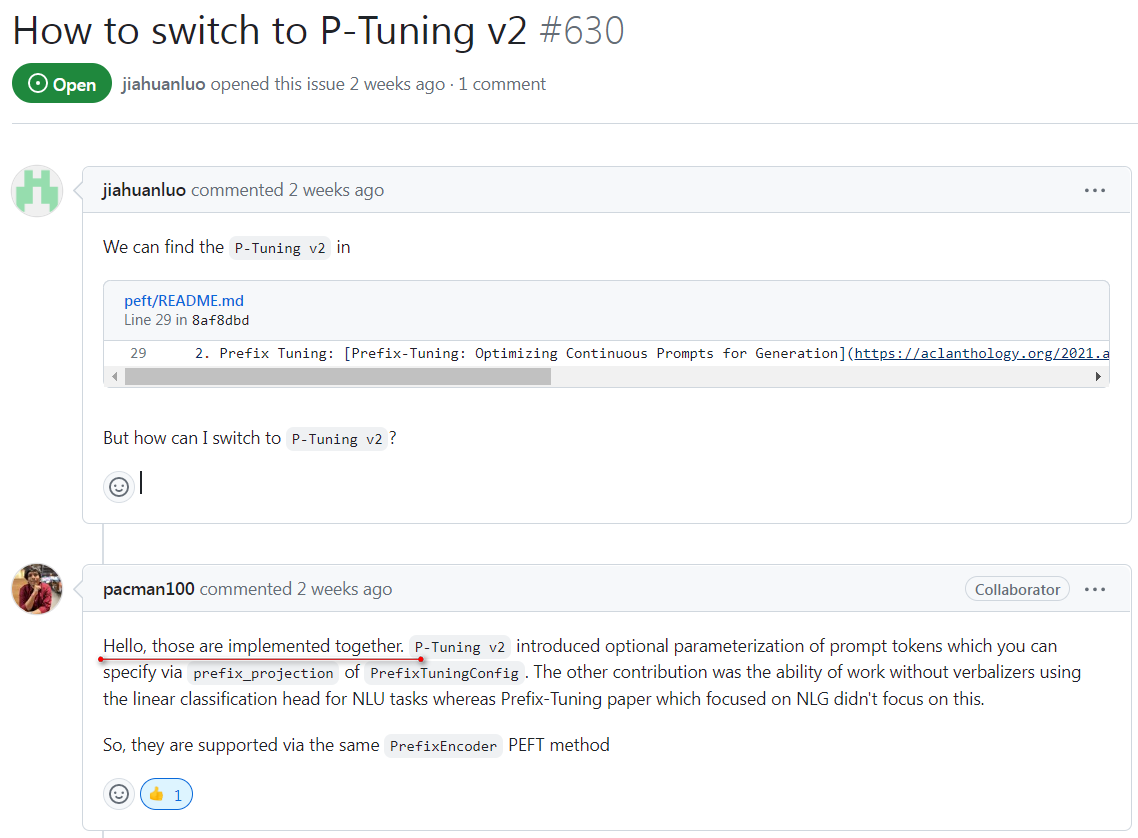
PrefixTuning和PTuningV2在实现上基本上是一样的,其实就是一样的。下面是peft作者回复的关于PrefixTuning和PTuningV2在实现上的关系。
LoRA
from peft import LoraConfig, LoraModel, get_peft_model
from peft.tuners.lora import LoraLayer
import os
from transformers import AutoModelForSequenceClassification
from torch import nn
from typing import Any, List, Optional, Unionos.environ["HF_HOME"] = "./hf_downloads"model_name_or_path = "bert-base-chinese"
tokenizer_name_or_path = "bert-base-chinese"lora_config = LoraConfig(peft_type="LORA",task_type="SEQ_2_SEQ_LM",inference_mode=False,# 如果r=0,bias='all',就变成了了BitFit微调方法r=8,lora_alpha=16,lora_dropout=0.1,fan_in_fan_out=False,# bias -> none 所有层的bias都不微调# bias -> all 所有层的bias都微调# bias -> lora_only 只有LoRA相关层的bias进行微调# bias 对应BitFit高效微调方法bias='lora_only'
)model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path)
model = get_peft_model(model, lora_config)
print(model)打印出来的model结构中包含LoRA在query和value部分添加的权重参数:
PeftModelForSeq2SeqLM((base_model): LoraModel((model): BertForSequenceClassification((bert): BertModel((embeddings): BertEmbeddings((word_embeddings): Embedding(21128, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(token_type_embeddings): Embedding(2, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): BertEncoder((layer): ModuleList((0-11): 12 x BertLayer((attention): BertAttention((self): BertSelfAttention((query): Linear(in_features=768, out_features=768, bias=True(lora_dropout): ModuleDict((default): Dropout(p=0.1, inplace=False))(lora_A): ModuleDict((default): Linear(in_features=768, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=768, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict())(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True(lora_dropout): ModuleDict((default): Dropout(p=0.1, inplace=False))(lora_A): ModuleDict((default): Linear(in_features=768, out_features=8, bias=False))(lora_B): ModuleDict((default): Linear(in_features=8, out_features=768, bias=False))(lora_embedding_A): ParameterDict()(lora_embedding_B): ParameterDict())(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): BertIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): BertOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))))(pooler): BertPooler((dense): Linear(in_features=768, out_features=768, bias=True)(activation): Tanh()))(dropout): Dropout(p=0.1, inplace=False)(classifier): Linear(in_features=768, out_features=2, bias=True)))
)下面看一下模型里面的可训练参数有哪些,因为在LoraConfig中设置了bias参数为lora_only,所以所有lora层的bias参数也会被设置为可训练:
for name, param in model.named_parameters():if param.requires_grad:print(name)base_model.model.bert.encoder.layer.0.attention.self.query.bias
base_model.model.bert.encoder.layer.0.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.0.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.0.attention.self.value.bias
base_model.model.bert.encoder.layer.0.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.0.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.1.attention.self.query.bias
base_model.model.bert.encoder.layer.1.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.1.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.1.attention.self.value.bias
base_model.model.bert.encoder.layer.1.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.1.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.2.attention.self.query.bias
base_model.model.bert.encoder.layer.2.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.2.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.2.attention.self.value.bias
base_model.model.bert.encoder.layer.2.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.2.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.3.attention.self.query.bias
base_model.model.bert.encoder.layer.3.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.3.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.3.attention.self.value.bias
base_model.model.bert.encoder.layer.3.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.3.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.4.attention.self.query.bias
base_model.model.bert.encoder.layer.4.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.4.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.4.attention.self.value.bias
base_model.model.bert.encoder.layer.4.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.4.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.5.attention.self.query.bias
base_model.model.bert.encoder.layer.5.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.5.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.5.attention.self.value.bias
base_model.model.bert.encoder.layer.5.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.5.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.6.attention.self.query.bias
base_model.model.bert.encoder.layer.6.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.6.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.6.attention.self.value.bias
base_model.model.bert.encoder.layer.6.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.6.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.7.attention.self.query.bias
base_model.model.bert.encoder.layer.7.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.7.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.7.attention.self.value.bias
base_model.model.bert.encoder.layer.7.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.7.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.8.attention.self.query.bias
base_model.model.bert.encoder.layer.8.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.8.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.8.attention.self.value.bias
base_model.model.bert.encoder.layer.8.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.8.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.9.attention.self.query.bias
base_model.model.bert.encoder.layer.9.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.9.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.9.attention.self.value.bias
base_model.model.bert.encoder.layer.9.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.9.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.10.attention.self.query.bias
base_model.model.bert.encoder.layer.10.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.10.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.10.attention.self.value.bias
base_model.model.bert.encoder.layer.10.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.10.attention.self.value.lora_B.default.weight
base_model.model.bert.encoder.layer.11.attention.self.query.bias
base_model.model.bert.encoder.layer.11.attention.self.query.lora_A.default.weight
base_model.model.bert.encoder.layer.11.attention.self.query.lora_B.default.weight
base_model.model.bert.encoder.layer.11.attention.self.value.bias
base_model.model.bert.encoder.layer.11.attention.self.value.lora_A.default.weight
base_model.model.bert.encoder.layer.11.attention.self.value.lora_B.default.weight下面将LoRA参数合并到预训练参数中,合并之后的模型和原始预训练模型一模一样:
merged_model = model.merge_and_unload()
print(merged_model)BertForSequenceClassification((bert): BertModel((embeddings): BertEmbeddings((word_embeddings): Embedding(21128, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(token_type_embeddings): Embedding(2, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): BertEncoder((layer): ModuleList((0-11): 12 x BertLayer((attention): BertAttention((self): BertSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): BertIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): BertOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))))(pooler): BertPooler((dense): Linear(in_features=768, out_features=768, bias=True)(activation): Tanh()))(dropout): Dropout(p=0.1, inplace=False)(classifier): Linear(in_features=768, out_features=2, bias=True)
)下面以peft_model.py文件中PeftModelForSequenceClassification的forward函数实现为例,看一下在推理阶段如何对于PrefixTuning、PromptTuning、PTuningV1、PTuningV2、Adapter、LoRA进行操作。
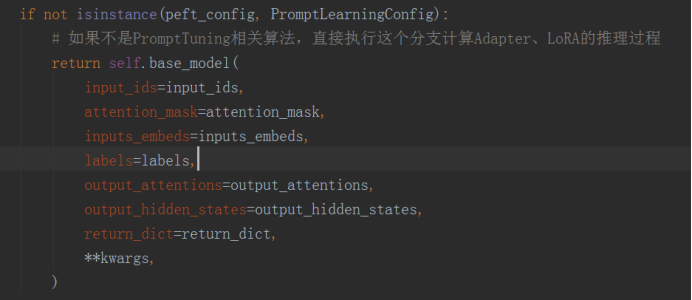
1、首先通过配置文件的所继承的父类类型来判断PEFT方法是否属于Prompt相关的,如果不是,就表示使用的是Adapter、LoRA等方法,直接执行推理。LoRA的具体推理计算过程后面再补充
2、如果通过配置文件的所继承的父类类型判断PEFT方法属于Prompt相关的,因为要在transformer block的序列开始位置添加虚拟token的embedding,所以也要补全attention mask
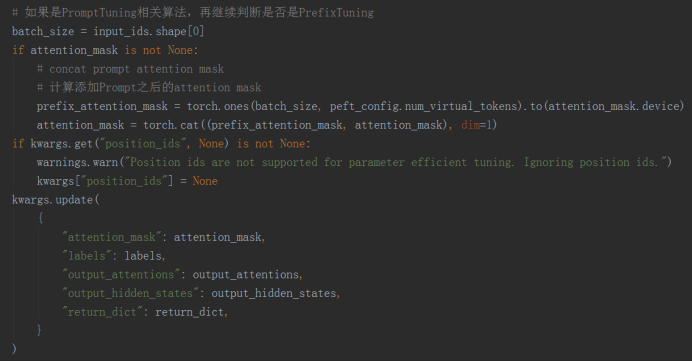
3、通过配置文件的类型来判断PEFT方法到底是PrefixTuning/PTuningV2,还是PromptTuning/PTuningV1。如果是PromptTuning/PTuningV1,则将虚拟token的embedding直接concat到原始输入序列的前面,送入base model模型进行推理。如果是PrefixTuning/PTuningV2,由于涉及到给每一个transformer block的key和value添加虚拟token的embedding,还需要使用_prefix_tuning_forward函数进行额外的处理。

PromptTuning/PTuningV1源码
PromptTuning和PTuningV1的共同点都是使用了浅层的Prompt,只在输入层使用。所以PromptTuning和PTuningV1在使用时的方式基本相同。
PromptTuning的源码详见src/peft/tuners/prompt_tuning.py,里面包含了相关的配置项以及Encoder的创建过程。
PTuningV1的源码详见src/peft/tuners/p_tuning.py,里面包含了相关的配置项以及Encoder的创建过程。
PromptTuning/PTuningV1的推理过程就是将虚拟token的embedding直接concat到原始输入序列的前面,并对attention mask进行扩充,送入base model模型进行推理。对应上面讲到的2和3。
PrefixTuning/PTuningV2源码
PrefixTuning和PTuningV2的共同点都是使用了深层的Prompt,在每层Transformer Block都使用,所以PrefixTuning和PTuningV2的实现放在一起。
上面说到当执行的PEFT类型是PrefixTuning/PTuningV2时,由于要给每个Transformer Block的Key和Value前面都加上可以学习的virtual token embedding,需要使用_prefix_tuning_forward函数进行额外的处理。
在看_prefix_tuning_forward函数之前先了解一些相关知识。自然语言处理任务可以分为Auto-Encoding(也叫NLU、自然语言理解、Masked Language Model)和Auto-Regressive(也叫NLG、自然语言生成、Language Model)。对于Auto-Encoding类型的任务,在模型的训练和预测阶段,self-attention都可以并行计算。对于Auto-Regressive类型的任务,在模型训练阶段通过使用attention mask也能够进行并行计算,但是在模型预测阶段,由于是时序生成任务,只能一步一步的生成,没办法并行。我们来看一下在生成阶段每个时间步有哪些计算:
时间步t:
Query:来自前一个时间步t-1时刻的输出,使用query矩阵(就是一个全连接层)转换之后得到
Key:来自前t-1个时间步[1,……,t-1]的输出,使用key矩阵(就是一个全连接层)转换之后得到
Value:来自前t-1个时间步[1,……,t-1]的输出,使用value矩阵(就是一个全连接层)转换之后得到
时间步t + 1:
Query:来自前一个时间步t时刻的输出,使用query矩阵(就是一个全连接层)转换之后得到
Key:来自前t个时间步[1,……,t-1,t]的输出,使用key矩阵(就是一个全连接层)转换之后得到
Value:来自前t个时间步[1,……,t-1,t]的输出,使用value矩阵(就是一个全连接层)转换之后得到
可以看到,每个时间步的Query都和上一个时间步的输出相关,每一步都需要重新计算Query,但是key和value来自前t-1个时间步的输出相关,所以t+1时刻的key和value与t时刻的key和value在[1,……,t-1]时刻上的计算结果是相同的,也就是这些结果是可以复用的,在每个时刻可以复用前一时刻计算的key和value,然后追加上当前时刻新增的key和value,构成完整的key和value。
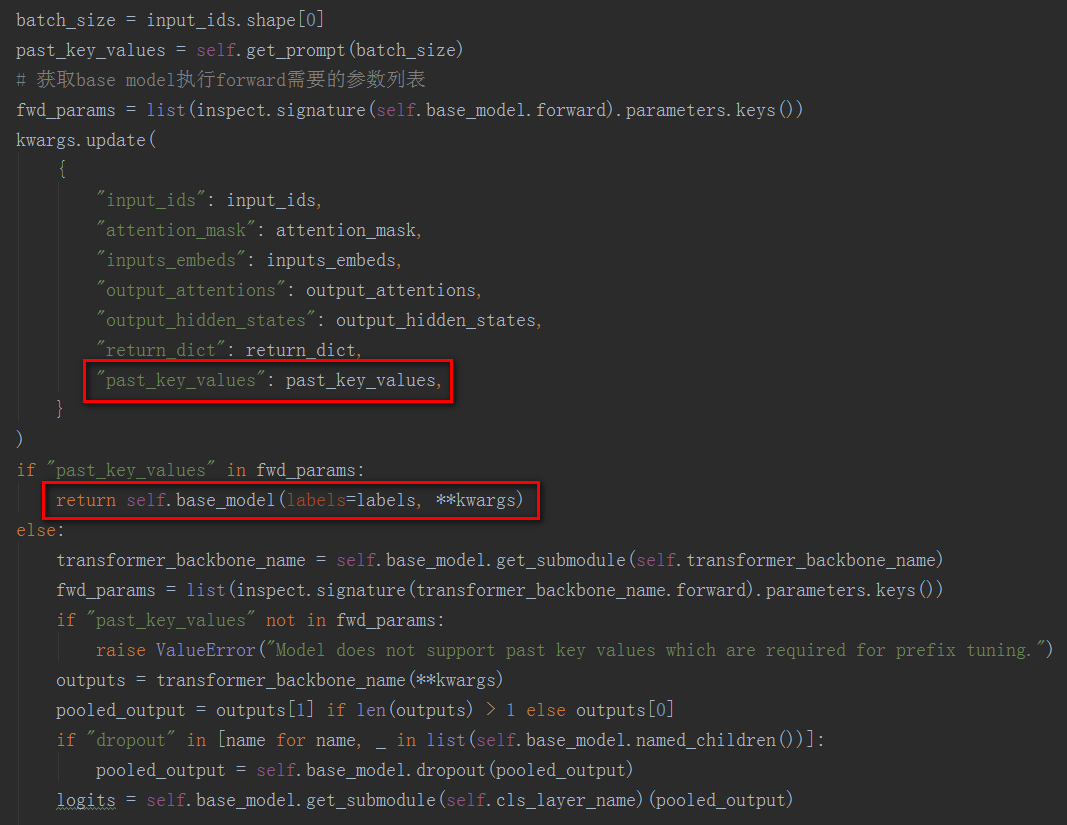
在hugging face实现的self-attention模块中,为了复用decode生成阶段的key和value,会传入一个past_key_values参数,如果past_key_values不是None,表示前面时间步已经有计算结果了,直接复用上一步的结果,然后将当前时间步的key和value拼接上去,更新后的past_key_values将继续传递到下一个时间步。
有了上面的背景知识,对于_prefix_tuning_forward函数中关于PrefixTuning/PTuningV2方法的实现就很好理解了,就是将生成的virtual token embedding通过past_key_values参数带入到transformer block的每一层,放在每一层key和value的前面。
LoRA源码
LoRA算法的主要流程可以分为以下几步:
- 根据LoraConfig中的target_module参数在base model中找到需要进行Lora操作的module
- 为找到的target module添加Lora相关参数,将进行Lora操作之后的module封装成LoraLayer层,然后使用Lora后的新module替换掉base model中老的module。
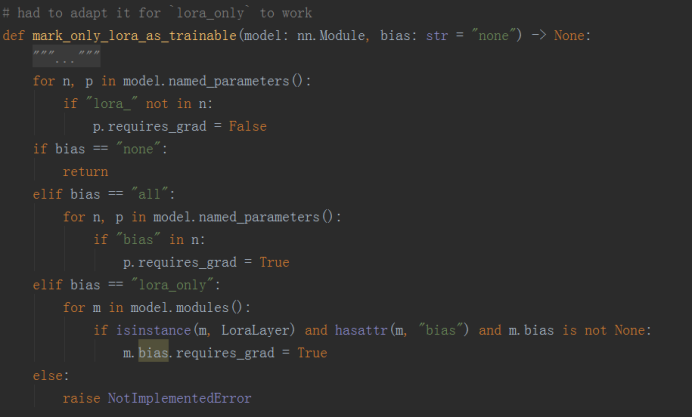
- 在训练阶段,将新添加的Lora参数和bias参数(如果bias设置为all或者lora_only的话)设置为可训练的,requires_grad=True,其余预训练参数都冻结
- 在推理阶段,将所有参数设置为requires_grad=False,并将做了Lora操作的层进行参数融合,将新添加的Lora参数融合到预训练参数中
上述这些流程在add_adapter函数中进行串联起来:
def add_adapter(self, adapter_name, config=None):if config is not None:# 基于model config更新lora config,主要补充的是target_module参数model_config = self.model.config.to_dict() if hasattr(self.model.config, "to_dict") else self.model.configconfig = self._prepare_lora_config(config, model_config)self.peft_config[adapter_name] = config# 根据target module参数,在base model中寻找并更新目标模块,将lora相关内容更新到模型架构中self._find_and_replace(adapter_name)if len(self.peft_config) > 1 and self.peft_config[adapter_name].bias != "none":raise ValueError("LoraModel supports only 1 adapter with bias. When using multiple adapters, set bias to 'none' for all adapters.")# 设置只有lora相关的参数可以微调,冻结其他参数mark_only_lora_as_trainable(self.model, self.peft_config[adapter_name].bias)if self.peft_config[adapter_name].inference_mode:# 在推理模式下冻结所有参数_freeze_adapter(self.model, adapter_name)基于上述流程,Lora源码主要包括以下大的模块(类):
1、LoraConfig:Lora配置文件
a)、LoraConfig中记录Lora相关的配置参数,其中重点看一下target_module、bias、modules_to_save这几个参数。
b)、target_module参数用来指出base model中叫什么名字的参数需要执行Lora操作,在other.py中TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING列出了每个模型中需要进行Lora操作的参数名称。
c)、bias对应的就是BitFit参数微调方法,就是在微调时是否微调bias参数:
# bias -> none 所有层的bias都不微调
# bias -> all 所有层的bias都微调
# bias -> lora_only 只有LoRA相关层的bias进行微调modules_to_save用来存放哪些模型参数是重新训练过的,保存模型的时候可以只保存这些参数,其他的都是预训练参数,可以不保存。
2、LoraLayer:用于记录Lora相关参数,初始化Lora部分的模型。在LoraLayer部分目前仅支持两种子模型的Lora操作,分别是nn.Embedding和nn.Linear(Conv1D等价于nn.Linear),下面看一下这部分主要的三个类:
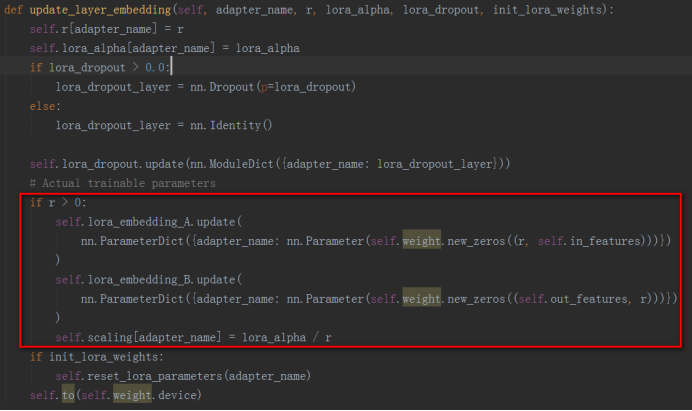
a)、LoraLayer:LoraLayer中实现了在Linear层中添加Lora操作的方法update_layer和在Embedding层中添加Lora操作的update_layer_embedding方法,这两个方法中根据原始参数形状初始化了Lora参数,分别在子类Linear和子类Embedding中调用。
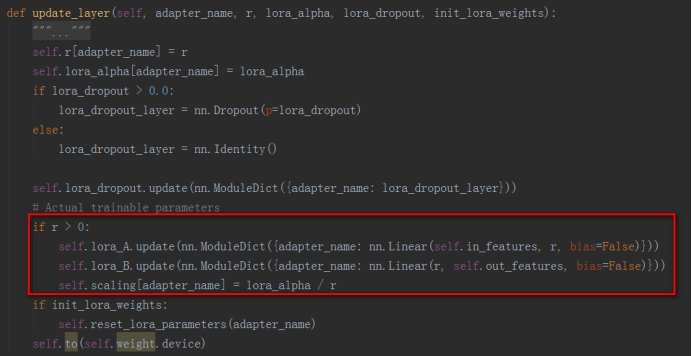
b)、Linear:Linear层继承nn.Linear和LoraLayer,实现了在nn.Linear层和Conv1D层(hugging face的transformers中实现)中使用Lora。使用nn.Linear创建和原始参数相同形状的参数,后面用来存储预训练的参数部分,使用LoraLayer的update_layer函数创建Lora新增的参数部分,这样就将一个Linear子模块改造成了添加了Lora的子模块。Linear层中还实现了merge和unmerge函数用来将Lora参数合入原始Linear层的预训练参数中,或者将Lora参数从原始Linear层的参数中分离出来。
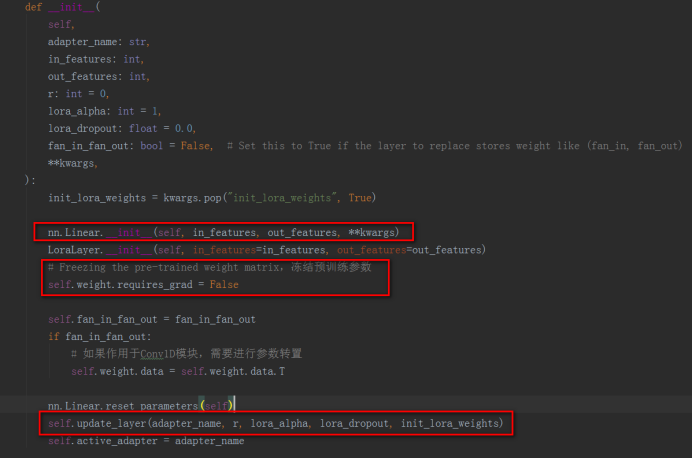
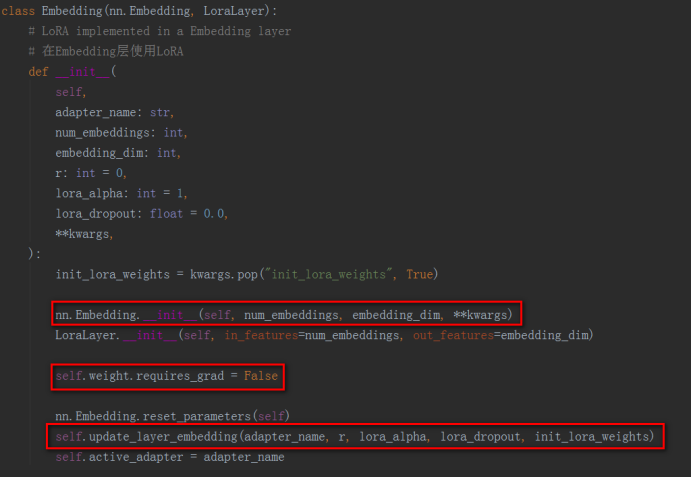
c)、Embedding:Embedding层继承nn.Embedding和LoraLayer,与Linear的实现几乎一样,Embedding也是创建了和原始Embedding参数相同形状的参数,后面用来存储预训练的参数部分,使用update_layer_embedding函数创建Lora新增的参数部分,这样就将一个Embedding子模块改造成了添加了Lora的子模块。Embedding层中也实现了merge和unmerge函数用来将Lora参数合入原始Embedding层的预训练参数中,或者将Lora参数从原始Embedding层的参数中分离出来。
3、LoraModel:基于上述组件,LoraModel可以拆解为以下部分:
a)、遍历base model的所有子module,根据LoraConfig中的target_module参数找到需要进行Lora操作的module,在LoraModel的_find_and_replace函数中实现
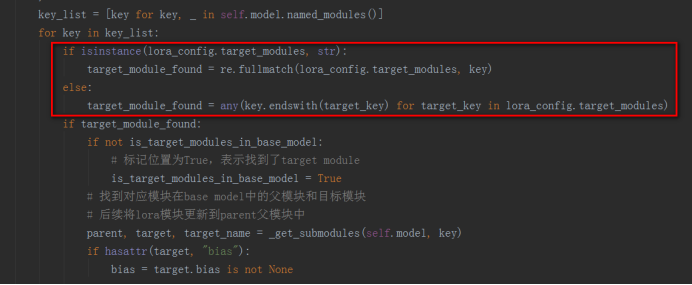
b)、基于上一步找到的target module,找到其父模块parent,并为找到的target module添加Lora相关参数,将进行Lora操作之后的module封装成LoraLayer层

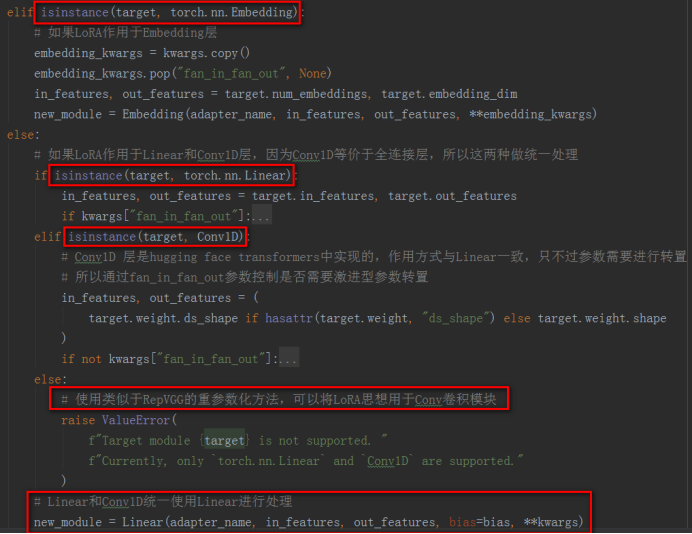
备注:当前PEFT版本中支持进行Lora的层只有nn.Linear、nn.Embedding和Conv1D(来自hugging face的transformers库,实际上就是一个weight做了转置的nn.Linear层)。根据重参数化Reparameterization的思想(重参数化详见RepVGG),卷积操作也可以使用Lora,peft-main分支里面已经正在开发这个功能了。
c)、根据找到的target module的父模块,使用Lora后的新module替换掉base model中对应的老的module,在_replace_module函数中实现
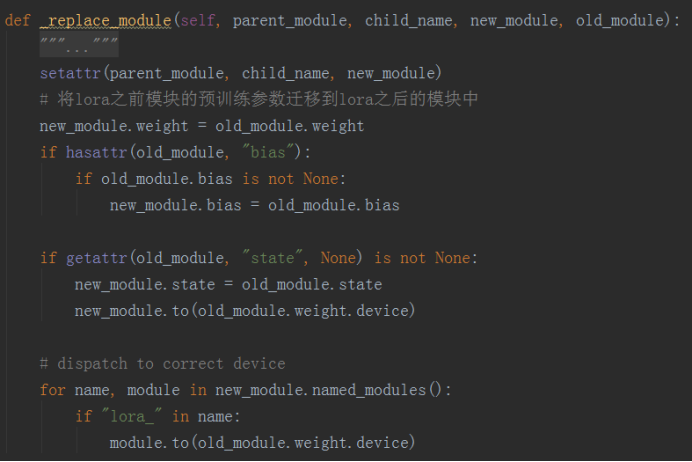
d)、在训练阶段,将新添加的Lora参数和bias参数(如果bias设置为all或者lora_only的话)设置为可训练的,requires_grad=True,其余预训练参数都冻结
e)、在推理阶段,将所有参数设置为requires_grad=False,并将做了Lora操作的层进行参数融合,将新添加的Lora参数融合到预训练参数中
这篇关于hugging face参数高效微调peft源码解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





