本文主要是介绍【大模型上下文长度扩展】MedGPT:解决遗忘 + 永久记忆 + 无限上下文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MedGPT:解决遗忘 + 永久记忆 + 无限上下文
- 问题:如何提升语言模型在长对话中的记忆和处理能力?
- 子问题1:有限上下文窗口的限制
- 子问题2:复杂文档处理的挑战
- 子问题3:长期记忆的维护
- 子问题4:即时信息检索的需求
- MemGPT 结构图
问题:如何提升语言模型在长对话中的记忆和处理能力?
论文:https://arxiv.org/abs/2310.08560
代码:https://github.com/cpacker/MemGPT#loading-local-files-into-archival-memory
MemGPT是为了解决“信息处理和记忆管理”的问题类别提出的。
具体问题是,在长期对话或处理大量文档时,传统聊天机器人无法记住所有信息,需要一种系统来扩展其记忆和处理能力。
是模仿了计算机操作系统中的内存管理,通过“分页”技术来扩展其记忆能力。
- 内存存放 “主记忆”,来处理当前的对话
- 硬盘存储 “外部记忆”,来回溯和引用以前存储的信息
当机器人需要回忆旧信息时,它可以从外部记忆中提取这些信息,就像人们从书架上取下一本旧书一样。
- 模仿计算机的内存管理机制
- 将不常用的数据页换出到硬盘,需要时再加载回内存
- 在不丢失过往信息的前提下,提升了对话的质量和文档处理的能力
这使得MemGPT可以处理非常长的对话(无限上下文),同时记住用户的所有偏好和历史,使交流更加个性化和连贯。
子问题1:有限上下文窗口的限制
- 背景: 现有语言模型因为上下文窗口大小有限,不能持续记住长对话中的所有信息。
- 子解法1: 外部存储上下文窗口扩展
- 特征: 使用外部存储来模拟无限上下文,让模型可以在需要时检索之前的对话内容。
- 例子: 就像玩具箱,当你的房间(主记忆)满了,你就把一些玩具放到玩具箱里(外部记忆),需要时再拿出来。

-
对话开始时,MemGPT(聊天机器人)和用户进行问候,并表现出对用户的兴趣,提到了F1赛车和帆船。
-
用户回复,表达了他对速度、刺激和肾上腺素的热爱。
-
系统随后发出警告,指出对话历史即将达到其最大长度并且将被修剪,提示MemGPT保存任何重要信息。
-
为响应这一警告,MemGPT使用了一个命令
working_context.append(),将用户的个性特征——享受高速、肾上腺素激增活动如F1赛车和CSGO游戏——添加到了工作上下文中。
这是MemGPT的一种记忆保存机制,可以在对话历史被修剪之前,将用户提供的关键信息保存下来。
这段对话体现了MemGPT如何动态管理对话内容,以确保即使在达到记忆容量上限时,也不会丢失对未来对话可能重要的用户信息。
通过这样的管理,MemGPT保持了对话的连贯性,并能够在未来的交互中利用这些信息,提供更个性化和相关的响应。
子问题2:复杂文档处理的挑战
- 背景: 当文档超出模型直接处理的长度时,模型难以理解整个文档内容。
- 子解法2: 分页长文档记忆检索
- 特征: 将长文档分成可管理的段落,逐段加载进行处理。
- 例子: 如果有一本很厚的故事书,你可能一次只能读几页,MemGPT可以通过“翻页”来继续阅读整个故事。

这张图展示了MemGPT在对话中的应用,具体是如何把对话中的重要信息保存到工作上下文中。
-
首先,MemGPT向用户Chad表示欢迎,并表现出对Chad的研究兴趣。这展示了MemGPT可以自然地开始对话,并表明了它对用户信息的兴趣。
-
用户回复说他今天休息,并提到了他妈妈为他做了生日蛋糕,是他最喜欢的巧克力熔岩蛋糕。
-
接下来,MemGPT使用命令
working_context.append()将用户的生日(10月11日)和喜欢的蛋糕类型(由妈妈做的巧克力熔岩蛋糕)添加到它的工作上下文中。这是MemGPT记忆管理的一个例子,它能够抓住对话中的关键信息并保存下来。 -
然后,MemGPT使用这些信息来继续对话,祝Chad生日快乐,并询问Chad的年龄,同时表达希望让当天的聊天成为Chad的美好记忆。
图中的描述说明了MemGPT如何有效地在没有系统记忆警告的情况下,积极记录并利用对话中的信息。
这种能力对于创建能够维持连续对话并在多次互动中保持个性化交流的聊天机器人至关重要。
通过这种方式,MemGPT能够记住对用户重要的日期和细节,这有助于在未来的对话中创建更有深度和连贯性的体验。
子问题3:长期记忆的维护
- 背景: 对话代理在长时间的互动中需要保持信息的连贯性和个性化。
- 子解法3: 动态记忆更新
- 特征: 允许模型实时更新其记忆库,以包含新信息或修正旧信息。
- 例子: 如果你告诉MemGPT你换了新工作,它会更新它的记忆,下次对话时会询问你的新工作情况。

这张图展示 MemGPT 如何更正并更新关于用户的信息,以维护对话的准确性和连贯性。
-
首先,MemGPT问用户是否想聊关于恐怖电影的话题,并询问是否有最近看的电影给他留下了深刻印象。
-
用户回答说他实际上并不喜欢恐怖电影,而是更喜欢浪漫喜剧。
-
接着,MemGPT使用了一个命令
working_context.replace('I watch horror movies.','I like romantic comedies.')来更正之前的信息。这意味着MemGPT在其工作上下文中替换了关于用户喜好的错误信息。 -
MemGPT随后用一条更新后的信息回应用户,不仅纠正了之前的错误,还询问用户是否有喜欢的浪漫喜剧电影,这表明MemGPT能够根据新的输入动态调整它的对话策略。
这个过程说明了MemGPT不仅能记忆用户提供的信息,还能在发现错误或更新的信息时进行自我修正。
这种能力对于创建能够与用户进行连续且个性化对话的聊天机器人是非常重要的。
通过这样的动态记忆更新,MemGPT能够维护对话的一致性,即使在长期的交互中也能保持个性化和相关性。
子问题4:即时信息检索的需求
- 背景: 用户可能会询问与过去对话相关的问题,模型需要快速提供准确回答。
- 子解法4: 快速信息检索
- 会在放东西的地方做个标记,这样下次就能快速找到。
- 特征: 模型能够迅速访问存储的信息,以回答用户的提问。
- 例子: 类似于谷歌搜索,当用户问到之前的话题,比如之前提过的喜欢的书,MemGPT能快速找到那次对话的内容。
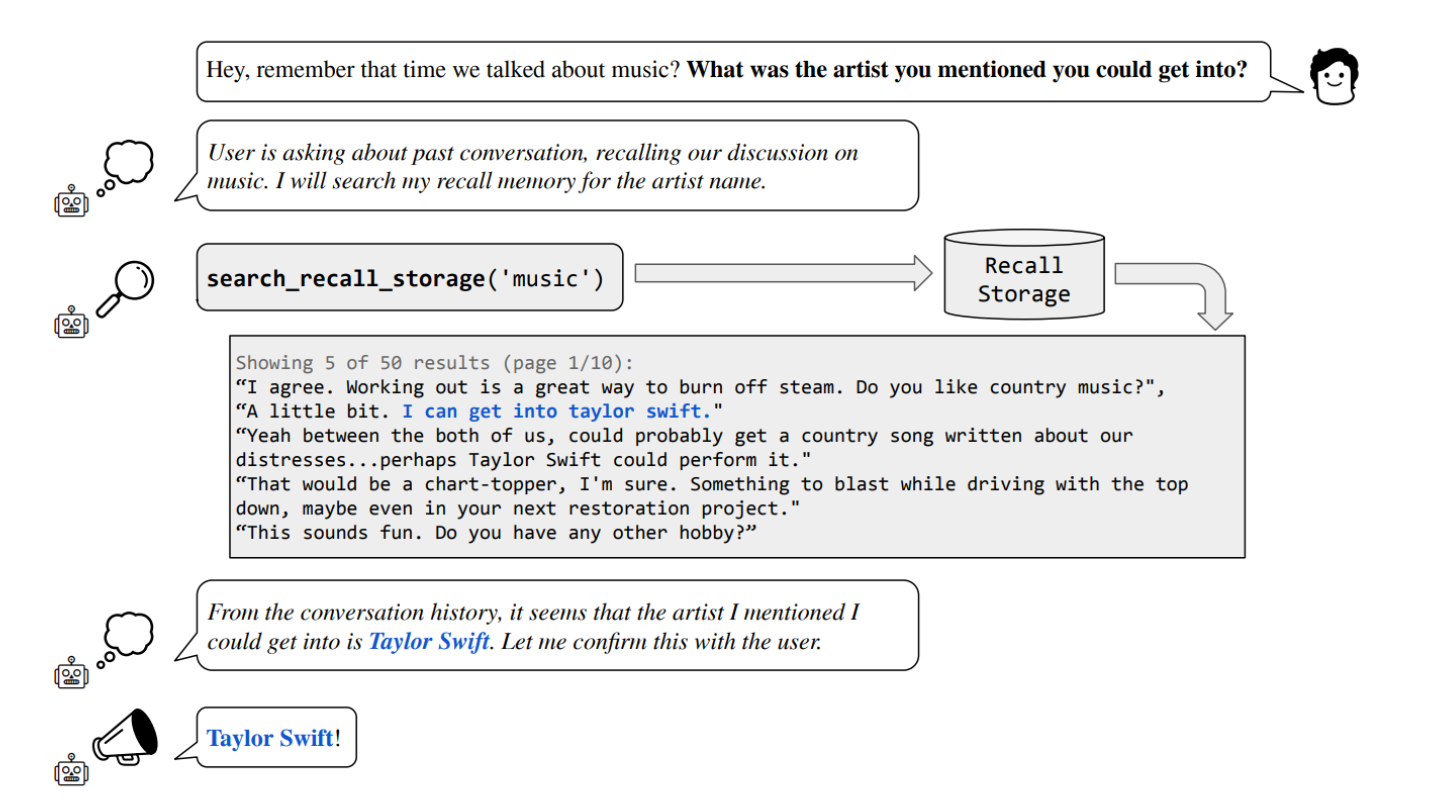
这张图是MemGPT中的“深度记忆检索任务”(Deep Memory Retrieval Task)的示例。
演示了如何使用MemGPT来回忆并检索与用户先前会话相关的信息。
具体来说:
-
对话框显示用户问了一个问题,提到了之前的一个对话,询问:“你之前提到的你可能会喜欢的艺术家是谁?” 这表明用户希望MemGPT能记住他们以前讨论过的内容。
-
在用户的对话框旁边,有一段描述,解释说用户正在回忆过去的对话,并且MemGPT将搜索其“回忆存储”以找到艺术家的名字。
-
接下来,MemGPT使用命令
search_recall_storage('music')来执行这一操作,这显示了MemGPT的能力,可以检索其存储的记忆以找到具体的信息。 -
展示的搜索结果是先前对话的一部分,这些对话提到了Taylor Swift,表明这可能是用户想起的艺术家。
-
最后,MemGPT确认了从对话历史中检索到的信息,并向用户确认艺术家是不是Taylor Swift。
即使某些信息不再处于当前上下文中,MemGPT也可以访问其记忆库中存储的过去对话,从而在必要时提供相关信息。
这种功能对于构建能够进行长期和深层次交互的对话代理至关重要,因为它使得代理能够记住用户的兴趣和历史,使对话更加个性化和连贯。
MemGPT通过外部存储扩展上下文窗口、分页长文档记忆检索、动态记忆更新和快速信息检索等多种方法,解决了传统语言模型在长对话和复杂任务处理中的限制。
这些方法的共同目标是使模型能够存储更多信息,更加智能地管理这些信息,并在需要时快速检索相关内容,从而使对话更加连贯和个性化。
MemGPT 结构图
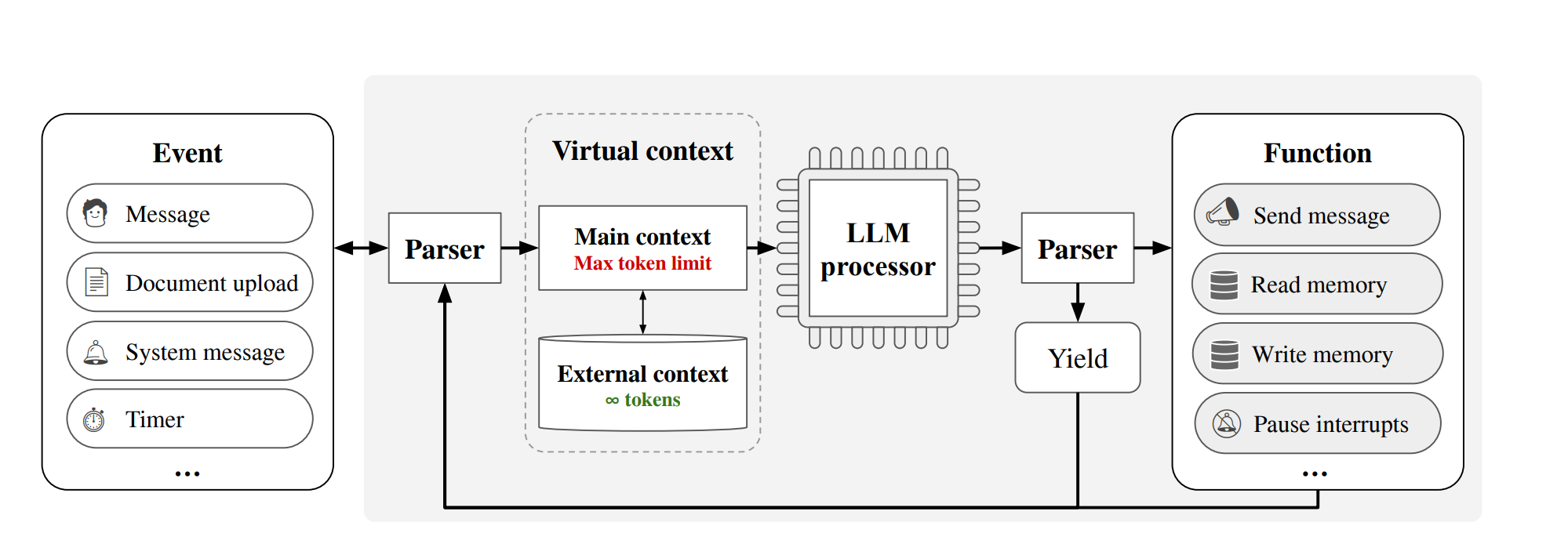
将固定上下文的语言模型与包括主上下文、外部上下文和记忆管理功能的记忆系统整合在一起。
通过事件、解析、语言模型处理和功能执行的数据流动。
这篇关于【大模型上下文长度扩展】MedGPT:解决遗忘 + 永久记忆 + 无限上下文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








