本文主要是介绍乔纳森-弗莱彻:被遗忘的搜索引擎之父,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自:http://tech.qq.com/a/20130905/000852.htm 腾讯科技
腾讯科技 瑞雪 9月5日编译
在谷歌(微博)庆祝其15周年诞辰之际,这家网络巨头已经成为信息检索的代名词。
但是,如果你在谷歌搜索引擎中输入乔纳森·弗莱彻(Jonathon Fletcher)的名字,那么在马上得出的搜索结果中不会找到什么线索指向他曾在万维网发展的过程中所扮演的角色。当然,也不会有任何信息能表明他作为现代搜索引擎之父的身份。
但在20年以前,正是弗莱彻在苏格兰斯特灵大学(University of Stirling)的一个电脑实验室中发明了全世界第一个能进行网络搜索的搜索引擎,也正是他发明的这种技术为谷歌、必应(Bing)、雅虎和今天网络上的所有大型搜索工具提供了支持。
解决网络搜索问题
在1993年时,网络正处于刚刚开始发展的婴儿期。在那时,第一个拥有类似于今天我们使用的界面的流行浏览器Mosaic刚刚发布,网页的总数量还只是以千为单位来进行计算而已。
尽管当时网络已经诞生,但如何在网络上找到内容的问题尚未得到解决。Mosaic拥有一个名为“What's New”的页面,能在新网站被创立时检索到这些网站。但问题在于,如果想要Mosaic的开发者能够知道一个新网站的诞生,那么其创立者就必须写信给美国伊利诺伊大学香槟分校(University of Illinois Urbana-Champaign)的国家超级计算应用中心(NCSA),也就是Mosaic浏览器团队的基地。
在那时,弗莱彻是斯特灵大学一名颇有前途的研究生,而且已经被推荐到格拉斯哥大学(University of Glasgow)攻读博士学位。但是,格拉斯哥大学的资金链在弗莱彻还没能到这所大学以前就已断裂,这让他变得无所事事。
“在突然之间,我变得非常渴望找到一种收入来源。”弗莱彻回忆道。“因此我回到了原来的大学,找到了一个为技术部门工作的岗位。”
正是在这个工作岗位上,弗莱彻第一次与万维网和Mosaic的“What's New”页面邂逅。
更好的方法
在为斯特灵大学建设一个网络服务器的过程中,弗莱彻意识到,“What's New”页面存在根本上的缺陷。由于网站是以人工方式被添加到这个网页的列表中的缘故,没有什么东西能被用来追踪网站内容的变化。其结果是,许多链接很快就会变得过期或是被错误标记。
“如果你想要看看有什么东西发生了变化,那么就不得不回过头去查看。”弗莱彻在谈及Mosaic的链接时说道。“抱着必须推出一种更好的方法的念头,拥有计算机科学学位的我决定要编写一些东西来改变这种情况。”
弗莱彻所说的“一些东西”就是全世界的第一个“网络爬虫”(web crawler)。弗莱彻把自己的这种发明称作“JumpStation”,他建立起了一个页面索引,能通过“网络爬虫”来对页面进行搜索,这基本上来说是一种自动化的处理程序,能对被其发现的每个网站页面进行访问和索引。这种自动化处理的程序会一直继续下去,直到“网络爬虫”再也找不到东西可以访问时为止。
在十年以后,也就是1993年12月21日,JumpStation就再也找不到可以访问的东西,结果是将2.5万个页面编入索引。而在今天,谷歌已经编入索引的页面数量已经超过了1万亿个。
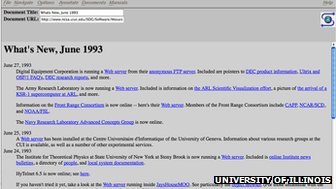
JumpStatio诞生几个月以前的“What's New”页面(腾讯科技配图)
搜索的诞生
弗莱彻很快就为这个索引开发出了一种易于导航的搜索工具,将自己的网站嵌入了Mosaic的“What's New”页面,这标志着全世界第一个现代搜索引擎开始运作。
“我会说,他是网络搜索引擎之父。”墨尔本皇家理工大学(Royal Melbourne Instituteof Technology)的马克·桑德森(Mark Sanderson)教授说道,他专门负责研究信息检索的历史。“(在弗莱彻发明第一个网络搜索引擎之前的)很长一段时间里,很明显一直都有计算机在从事搜索工作;在网络诞生以前,当然也已经有搜索引擎存在。然而,是弗莱彻第一个创造了一种拥有现代搜索引擎所有组成部分的搜索引擎。”
但在今天,谷歌的两名联合创始人塞吉·布林(Sergey Brin)和拉里·佩奇(Larry Page)都已经成为家喻户晓的名人,而目前居住在中国香港的弗莱彻却几乎没有因为他为互联网进化作出的贡献而为人所知。
之所以会出现这种情况,或许与他的项目最终被放弃有关。随着JumpStation的成长,这个项目需要的投资越来越大,而这种投资却是斯特灵大学所不愿提供的。“当时JumpStation是在一个共享服务器上运行的。”弗莱彻解释道。“那时没有很大的磁盘空间,而且当时的磁盘很小,价格也很昂贵。”
空间控制
到1994年6月份,JumpStation已经对27.5万个页面进行了索引。空间方面的限制迫使弗莱彻仅对网页的标题进行索引,而不是对网页的全部内容进行索引;但即使是在作出了这种妥协以后,JumpStation也仍旧开始面临着过载的困境。
弗莱彻也同样已不堪重负。“那并非我的本职工作。”他说道。“那时我的工作职责是维持学生实验室的正常运作,并从事一些系统管理和技术方面的杂活儿。”
在当时,弗莱彻得到了一个到东京工作的机会。对他来说,这个工作机会的吸引力大到令人难以抗拒,而斯特灵大学也几乎没有尝试做些什么来挽留他或是挽留JumpStation。
“很明显,在尝试说服他们相信这个项目很有潜力的问题上,我做得很不成功。”弗莱彻说道。“在当时,我做了自己认为是正确的事情(到日本去工作)。但在过去20年时间里,总有那么些时候我会回首这段往事。”
斯特灵大学计算机科学及数学系主任莱斯利·史密斯(Leslie Smith)教授还记得弗莱彻,他承认JumpStation最终“被证明是领先于时代的”,并在接受BBC采访时表示:“斯特灵大学的同仁们都为他能因自己取得的成就而为人所知感到高兴。”
未来展望
尽管弗莱彻对不得不放弃JumpStation项目而感到失望,但他的这种先驱技术在后来却成为了所有网络搜索引擎的基础。
“在1993年时,网络社区的规模非常小。”桑德森教授说道。“在当时,在网上做任何事情的人都会知道JumpStation。”他还补充道:“到1994年年中前后,网络搜索引擎将变得非常重要这件事情已经开始变得明显。谷歌直到1998年才出现,而弗莱彻在1993年就已经做了这件事情。”
在几个星期以前于爱尔兰首都都柏林召开的SIGIR(国际计算机协会主办的国际信息检索大会)上,弗莱彻由于他在网络搜索引擎方面作出的成就而获得了一些知名度。在当时,他曾跟来自于微软、雅虎和谷歌的与会代表进行过小组讨论。但在弗莱彻的言谈中,他所谈论的并非自己以往的成就,而是对未来作出了展望。
“在我看来,网络不会永远存在。”弗莱彻说道。“但是,找到信息的问题则将永远存在,因为对内容进行搜索并找到信息的愿望是独立于媒介以外的。”
对于追随弗莱彻其后建立起网络搜索引擎的人们来说,当前的这种媒介已经让他们赚到了大笔的钞票。但是,弗莱彻这位出生于英格兰自治市斯卡伯勒(Scarborough)的先驱者并不对此感到遗憾。“我的父母以我为骄傲,我的妻子和孩子也是如此。对我来说,这才是无价之宝,所以我感到非常幸福。”
这篇关于乔纳森-弗莱彻:被遗忘的搜索引擎之父的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







