本文主要是介绍【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
针对图像到图像生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据
- 提出背景
- 如何在不重训练模型的情况下从I2I生成模型中移除特定数据?
- 超高效的机器遗忘方法
- 子问题1: 如何在图像到图像(I2I)生成模型中进行高效的机器遗忘?
- 子问题2: 如何确定哪些数据需要被遗忘?
- 子问题3: 如何保持对其他数据的记忆不受影响?
- 评估与效果
- 子问题: 机器遗忘算法如何平衡保留集和遗忘集之间的性能?
- 子问题: 如何定义一个能够量化遗忘效果的目标函数?
提出背景
论文:https://arxiv.org/pdf/2402.00351.pdf
代码:https://github.com/jpmorganchase/l2l-generator-unlearning
如何在不重训练模型的情况下从I2I生成模型中移除特定数据?
- 背景: 现行法律对数据隐私和版权提出了新要求,这需要机器学习模型能够遗忘特定的训练数据。
传统的机器遗忘方法,如SISA,需要重新训练模型,这在大型生成模型中不现实。
探索直接操作训练好的模型权重的方法,如使用Neural Tangent Kernel (NTK)或最大化遗忘集上的损失,减少遗忘所需的计算量。
- 解法: 探索允许模型删除特定的训练样本数据,而无需从头开始重训练整个模型。
- 例子: 用户要求删除其数据,遗忘技术能让模型忘记这些数据,而不影响对其他数据的处理能力。
与重新训练整个模型或简单的数据删除相比,提出的机器遗忘方案在计算效率和应用的灵活性方面更为优越。
超高效的机器遗忘方法
子问题1: 如何在图像到图像(I2I)生成模型中进行高效的机器遗忘?
- 背景: 在I2I生成模型中,删除敏感数据的同时保持模型性能是一个挑战,因为简单的数据删除无法消除模型中已经学到的信息。
- 解法: 提出了一种不需从头开始训练模型的高效遗忘算法,通过优化KL散度和利用L2损失实现遗忘。
这种解法避免了从头开始训练整个模型,而是直接在模型的现有权重上应用调整。
它使用KL散度来度量和最大化遗忘集(即将被模型“遗忘”的数据)的生成图像与原图之间的统计分布差异,同时利用L2损失来最小化保留集(即模型需要继续记住的数据)的生成图像与原图之间的差异。
假设有一个I2I模型,它被训练用于将简笔画转换为详细的彩色图像。
出于隐私原因,我们需要模型遗忘所有包含特定符号的简笔画。
在不重训练模型的情况下,我们可以调整模型的权重,使得当模型再次看到这些特定符号的简笔画时,它生成的图像与原图的KL散度最大化(即生成的图像与原图差异很大),而对于其他类型的简笔画,模型应通过L2损失保持其原有的转换能力。
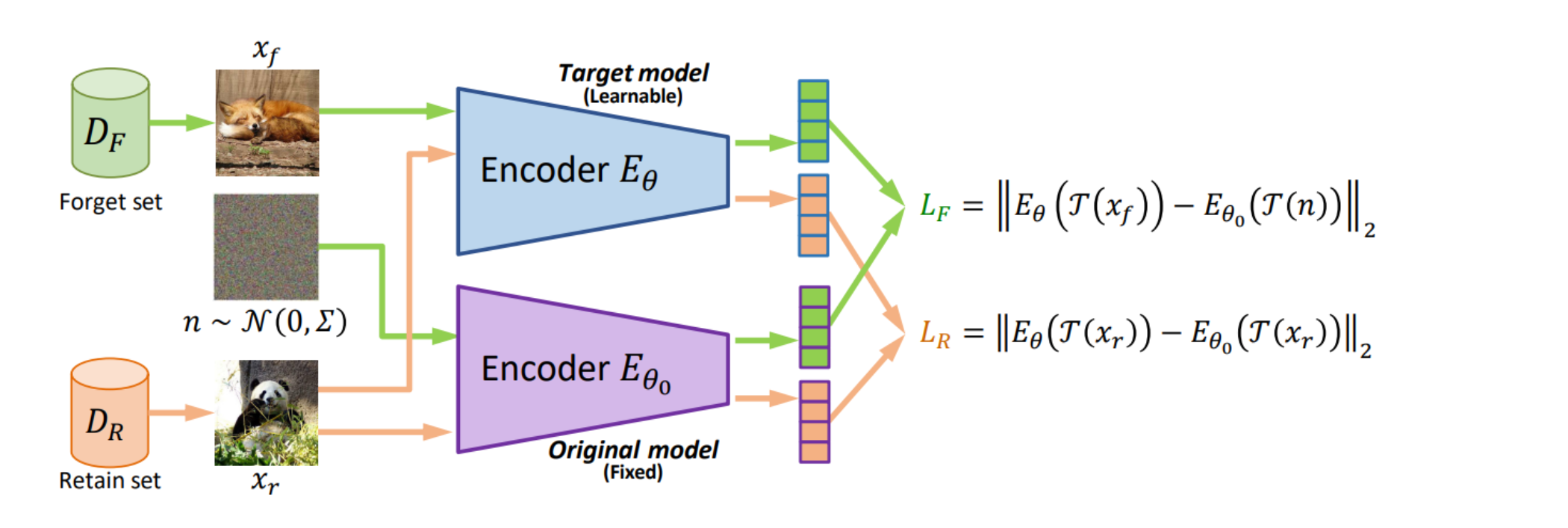
这张图提供了一个机器遗忘方法的概览。
在这个方法中,有两个数据集:遗忘集(( D_F ))和保留集(( D_R )),以及两个编码器:目标模型编码器 E θ E_{\theta} Eθ(可学习的)和原始模型编码器 E θ 0 E_{\theta_0} Eθ0(固定的)。
对于遗忘集(( x_f )),方法的目标是最小化目标模型编码器 E θ E_{\theta} Eθ 输出的嵌入向量与由高斯噪声 ( n )生成的嵌入向量之间的L2损失( L F L_F LF)。
这意味着,在遗忘集上,目标模型的输出应与随机噪声相似,从而“遗忘”或移除相关的特征。
对于保留集( x r x_r xr),目标是最小化目标模型编码器 E θ E_{\theta} Eθ 输出的嵌入向量与原始模型编码器 E θ 0 E_{\theta_0} Eθ0 输出的嵌入向量之间的L2损失(( L_R ))。
这确保了在保留集上,即使经过遗忘过程,目标模型仍然能够保持对原始特征的记忆。
- 遗忘方法的核心原理,即通过调整编码器输出,使得遗忘集的数据被有效地去除,同时保留集的数据特征被保留。
- 这种方法旨在保护隐私,同时保持模型在不需要遗忘的数据上的性能。
子问题2: 如何确定哪些数据需要被遗忘?
- 背景: 在应对隐私保护法律要求或用户的个人数据删除请求时,必须明确哪些数据需要从模型中移除。
- 解法: 设立一个遗忘集(( D_F )),包含所有需被遗忘的数据样本。
- 例子: 如果用户要求删除其在在线服务中的面部数据,所有包含该用户面部的图像将被归入遗忘集。
子问题3: 如何保持对其他数据的记忆不受影响?
- 背景: 在移除特定数据的同时,不应损害模型对于其他数据的处理能力。
- 解法: 设立一个保留集(( D_R )),并通过算法保证在遗忘过程中这些数据的特征不会被改变。
- 例子: 在同一个面部识别服务中,即便删除某些用户的数据,服务仍能准确识别并处理其他用户的面部图像。
通过区分遗忘集和保留集,并对遗忘集应用特定的遗忘算法,实现了数据的精确遗忘。
不足之处可能在于如何确保在遗忘集和保留集之间划分的界限是明确的,以及如何处理边界模糊的情况。
评估与效果
子问题: 机器遗忘算法如何平衡保留集和遗忘集之间的性能?
- 背景: 在机器遗忘中需要确保遗忘集中的数据被去除,同时保留集的数据性能不受影响。
- 解法: 通过最小化保留集的生成图像与原图的分布差异,同时最大化遗忘集的生成图像与原图的分布差异。
- 例子: 对于风格转换模型,保留集中的艺术风格转换能力不受影响,而遗忘集中特定艺术家的风格被模型遗忘。
在这种方法中,目标是调整模型权重,使得保留集上的图像生成尽可能保持高质量(与原图差异小),而遗忘集上的图像生成则明显偏离原有数据分布。
这通常通过在训练期间添加特定的约束或损失函数来实现,以确保模型在保留集上的生成图像与真实图像保持一致,同时在遗忘集上生成与原图不同的图像。
考虑一个被训练用于风格迁移的I2I模型,现在需要遗忘特定艺术家的风格。
遗忘操作将通过调整模型权重实现,当模型尝试在遗忘集上进行风格迁移时,结果图像与原始艺术家风格的分布有很大差异,而在保留集上的其他艺术风格则保持不变。

这张图展示了一个机器遗忘框架在不同类型的图像到图像(I2I)生成模型上的应用效果,包括扩散模型(Diffusion Models)、向量量化生成对抗网络(VQ-GAN),以及掩蔽自编码器(MAE)。
图中展示了两个不同的集合:保留集(Retain Set)和遗忘集(Forget Set)。
在保留集部分(a),可以看到原始图片(Ground Truth),输入图片(Input),以及遗忘前后的图片(Before Unlearning 和 After Unlearning)。
保留集的图片在遗忘前后几乎没有受到影响,图像质量和内容保持一致。
在遗忘集部分(b),同样展示了原始图片和输入图片,以及遗忘前后的图片。
遗忘后的图片与原始图片相比,几乎成为了噪声,这意味着模型成功“忘记”了遗忘集中的信息,图片内容被大幅度扭曲,以至于无法识别原来的内容,符合遗忘框架的设计目的。
- 机器遗忘框架在各种I2I生成模型上的适用性,并验证了其能够有效地在遗忘集上实现数据的遗忘,同时保持保留集上数据的完整性。
子问题: 如何定义一个能够量化遗忘效果的目标函数?
- 背景: 需要一个清晰的目标,以量化模型遗忘特定数据的效果。
- 解法: 使用KL散度和互信息(MI)作为度量,定义了一个目标函数来量化遗忘的效果。
- 例子: 在遗忘算法的效果评估中,可以通过比较遗忘前后模型生成的图像与原图的KL散度来量化遗忘的程度。
在这个解法中,使用KL散度和互信息(MI)来定义一个目标函数,旨在量化模型遗忘特定数据的效果。
KL散度衡量两个概率分布之间的差异,而互信息量化两个变量间的相互依赖性。
这些指标结合起来能够给出模型遗忘效果的量化评估。
假如有一个生成模型被用于生成人脸图像,现在需要遗忘某个人的脸部数据。
通过调整模型参数,当模型接收到与该人脸相关的输入时,输出的图像与原始人脸的KL散度很高,表明生成的图像与被遗忘的人脸差异很大。
同时,通过测量互信息,确保在保留集上模型仍能生成与输入高度相关的人脸图像。
遗忘性能展示:

- 上半部分(Figure 3) 展示了在扩散模型上对中心8x8像素块进行裁剪后的结果,其中每个裁剪块的大小为16x16像素。
- 图像从左到右依次展示了:
- “Ground Truth”:原始未处理的图像。
- “Input”:输入到模型中的图像,中间有被遗忘的8x8像素块。
- 一系列不同遗忘方法的结果,包括“Original Model”(原始模型输出),“Max Loss”(最大化损失),“Noisy Label”(噪声标签),“Retain Label”(保留标签),“Random Encoder”(随机编码器),以及“Ours”(我们的方法)。
这部分显示了在进行遗忘操作后,保留集的图像质量几乎没有影响,而遗忘集的图像则变得接近噪声,说明遗忘操作成功执行。
这篇关于【超高效!保护隐私的新方法】针对图像到图像(l2l)生成模型遗忘学习:超高效且不需要重新训练就能从生成模型中移除特定数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





