本文主要是介绍元象4.2B参数 MoE大模型实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01 简介
近期,元象公司推出了其首个Moe大模型XVERSE-MoE-A4.2B。该模型采用了混合专家模型架构(Mixture of Experts),并拥有4.2B的激活参数,其性能可与13B模型相媲美。值得一提的是,这个模型是完全开源的,可以无条件免费商用,这对于中小企业、研究者和开发者来说无疑是一个巨大的福音。他们可以在元象高性能“全家桶”中按需选用,以推动低成本部署。
在元象自研的过程中,他们在相同的语料上训练了2.7万亿token。XVERSE-MoE-A4.2B的实际激活参数量为4.2B,其性能“跳级”超越了XVERSE-13B-2,仅用了30%的计算量,并且减少了50%的训练时间。在与多个开源标杆Llama的比较中,该模型超越了Llama2-13B,接近Llama1-65B的性能。

元象自主研发的MoE高效训练和推理框架,在三个方向实现创新:
-
性能方面,围绕MoE架构中的专家路由和权重计算逻辑,研发了一套高效融合算子进行计算提效;针对MoE模型高显存和大通信量的挑战,设计出计算、通信和显存卸载的重叠操作,有效提高整体处理吞吐量。
-
架构方面,为保障模型灵活性与性能,采用更细粒度专家设计,相对于传统MoE(如Mixtral 8x7B)将每个专家大小等同于标准FFN,元象的每个专家大小仅为标准FFN的四分之一;同时区分共享专家与非共享专家,共享专家在计算中保持激活中台,非共享专家需要选择性激活,有利于将通用知识压缩至共享专家参数中,减少非共享专家参数间的知识冗余。
-
训练方面,引入负载均衡损失项,更好均衡专家间的负载;采用路由器z-loss项,确保训练高效和稳定。
02 环境配置与安装
-
python 3.10及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.8及以上
使用步骤
本文主要演示的模型为XVERSE-MoE-A4.2B模型,在PAI-DSW使用(单卡A100)。
下载模型的repo:
from modelscope import snapshot_download
model_dir1 = snapshot_download("xverse/XVERSE-MoE-A4.2B")03 模型推理
import torch
from modelscope import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("xverse/XVERSE-MoE-A4.2B")
model = AutoModelForCausalLM.from_pretrained("xverse/XVERSE-MoE-A4.2B", trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()
inputs = tokenizer('北京的景点:故宫、天坛、万里长城等。\n深圳的景点:', return_tensors='pt').input_ids
inputs = inputs.cuda()
generated_ids = model.generate(inputs, max_new_tokens=64, eos_token_id=tokenizer.eos_token_id, repetition_penalty=1.1)
print(tokenizer.batch_decode(generated_ids, skip_special_tokens=True))资源消耗:
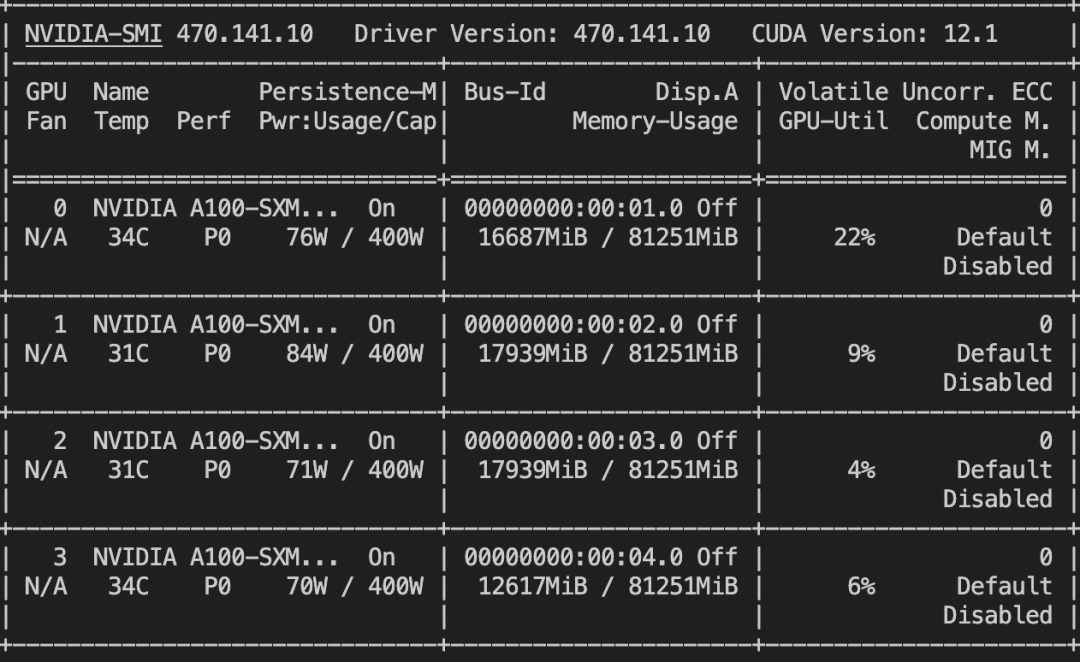
单卡A100可运行,如果自己的显卡显存不够,可以考虑使用多张3090显卡,或者对模型进行量化。
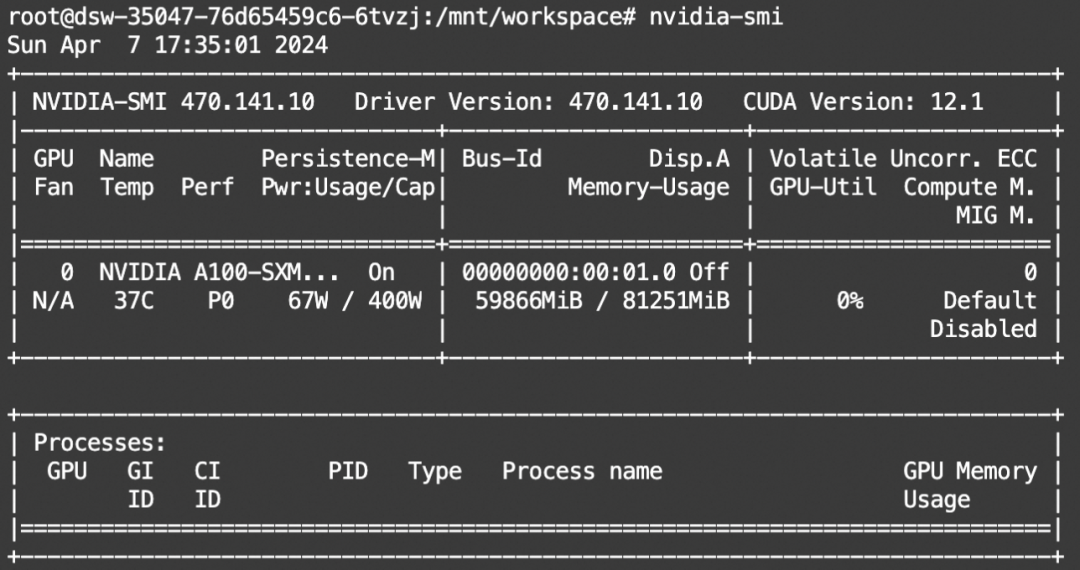
04 模型微调和微调后推理
微调代码开源地址:
https://github.com/modelscope/swift/tree/main/examples/pytorch/llm
SWFIT是魔搭社区官方提供的LLM&AIGC模型微调推理框架,首先从github上将SWIFT clone下来
# 设置pip全局镜像和安装相关的python包
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/modelscope/swift.git
cd swift
pip install .[llm]模型微调脚本 lora
·
# Experimental environment: A100
# 66GB GPU memory
CUDA_VISIBLE_DEVICES=0 \
swift sft \--model_type xverse-moe-a4_2b \--sft_type lora \--tuner_backend swift \--dtype fp16 \--dataset dureader-robust-zh \--train_dataset_sample -1 \--num_train_epochs 1 \--max_length 1024 \--check_dataset_strategy warning \--lora_dtype fp16 \--lora_rank 8 \--lora_alpha 32 \--lora_dropout_p 0.05 \--lora_target_modules DEFAULT \--gradient_checkpointing false \--batch_size 1 \--weight_decay 0.1 \--learning_rate 1e-4 \--gradient_accumulation_steps 16 \--max_grad_norm 0.5 \--warmup_ratio 0.03 \--eval_steps 100 \--save_steps 100 \--save_total_limit 2 \--logging_steps 10 \模型微调脚本 (lora+mp)
可以在消费级显卡上进行训练
# Experimental environment: 4*A100
# 4*20GB GPU memory
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
python llm_sft.py \--model_type xverse-moe-a4_2b \--sft_type lora \--tuner_backend swift \--dtype AUTO \--dataset dureader-robust-zh \--train_dataset_sample -1 \--num_train_epochs 1 \--max_length 1024 \--check_dataset_strategy warning \--lora_rank 8 \--lora_alpha 32 \--lora_dropout_p 0.05 \--lora_target_modules DEFAULT \--gradient_checkpointing false \--batch_size 1 \--weight_decay 0.1 \--learning_rate 1e-4 \--gradient_accumulation_steps 16 \--max_grad_norm 0.5 \--warmup_ratio 0.03 \--eval_steps 100 \--save_steps 100 \--save_total_limit 2 \--logging_steps 10 \模型微调后推理脚本
请将下面--ckpt_dir的值改为--output_dir中实际存储的模型weights目录。
# Experimental environment: A100
# 4*18GB GPU memory
CUDA_VISIBLE_DEVICES=0,1,2,3 \
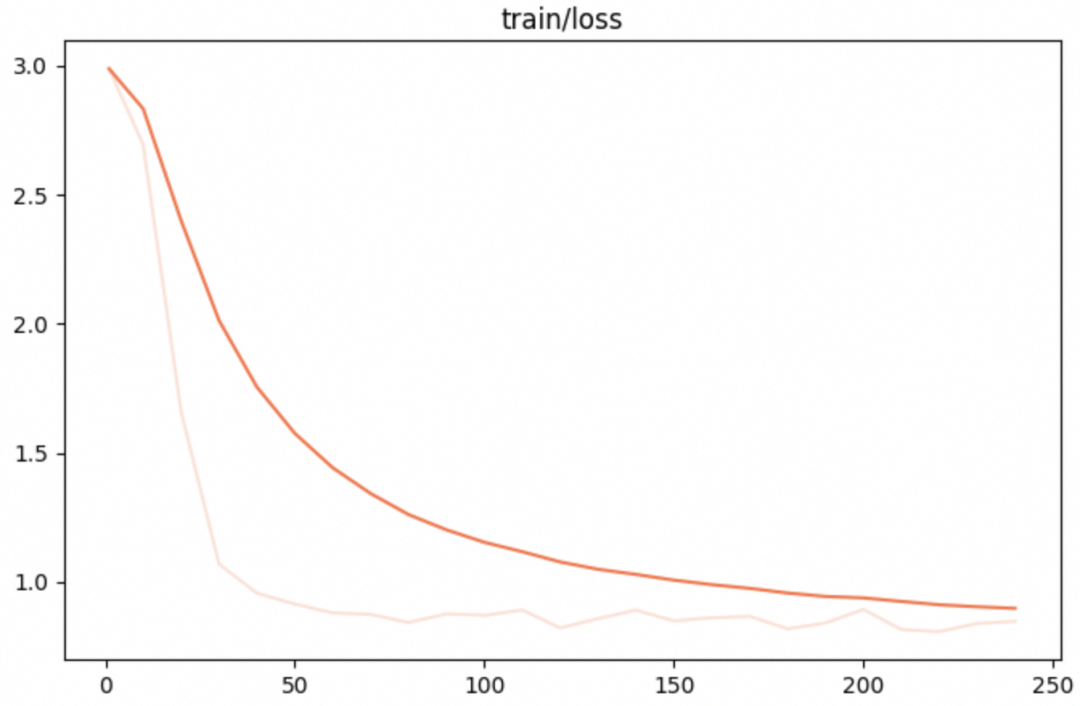
swift infer \--ckpt_dir "output/xverse-moe-a4_2b/vx-xxx/checkpoint-xxx" \--load_dataset_config true \--max_new_tokens 2048 \--temperature 0.7 \--top_p 0.7 \--repetition_penalty 1. \--do_sample true \--merge_lora false \微调的可视化结果
训练损失:
训练后生成样例
[PROMPT]Task: Question Generation
Context: 爬行垫根据中间材料的不同可以分为:XPE爬行垫、EPE爬行垫、EVA爬行垫、PVC爬行垫;其中XPE爬行垫、EPE爬行垫都属于PE材料加保鲜膜复合而成,都是无异味的环保材料,但是XPE爬行垫是品质较好的爬行垫,韩国进口爬行垫都是这种爬行垫,而EPE爬行垫是国内厂家为了减低成本,使用EPE(珍珠棉)作为原料生产的一款爬行垫,该材料弹性差,易碎,开孔发泡防水性弱。EVA爬行垫、PVC爬行垫是用EVA或PVC作为原材料与保鲜膜复合的而成的爬行垫,或者把图案转印在原材料上,这两款爬行垫通常有异味,如果是图案转印的爬行垫,油墨外露容易脱落。当时我儿子爬的时候,我们也买了垫子,但是始终有味。最后就没用了,铺的就的薄毯子让他爬。
Answer: XPE
Question:[OUTPUT]爬行垫什么材质好<|endoftext|>[LABELS]爬行垫什么材质的好
--------------------------------------------------
[PROMPT]Task: Question Generation
Context: 下载速度达到72mbp/s速度相当快。相当于500兆带宽。在网速计算中, b=bit,B=byte 8×b=1×B 意思是 8个小写的b 才是一个大写B。4M理论下载速度:4M就是4Mb/s 理论下载速度公式:4×1024÷8=512KB /s 请注意按公式单位已经变为 KB/s 依此类推: 2M理论下载速度:2×1024÷8=256KB /s 8M理论下载速度:8×1024÷8=1024KB /s =1MB/s 10M理论下载速度:10×1024÷8=1280KB /s =2M理论下载速度+8M理论下载速度 50M理论下载速度:50×1024÷8=6400KB /s 1Gb理论下载速度:1024×1024÷8=128MB /s 公式:几兆带宽×1024÷8=()KB/s。
Answer: 相当于500兆带宽
Question:[OUTPUT]72m等于多少兆<|endoftext|>[LABELS]72mbps是多少网速
资源消耗
训练lora
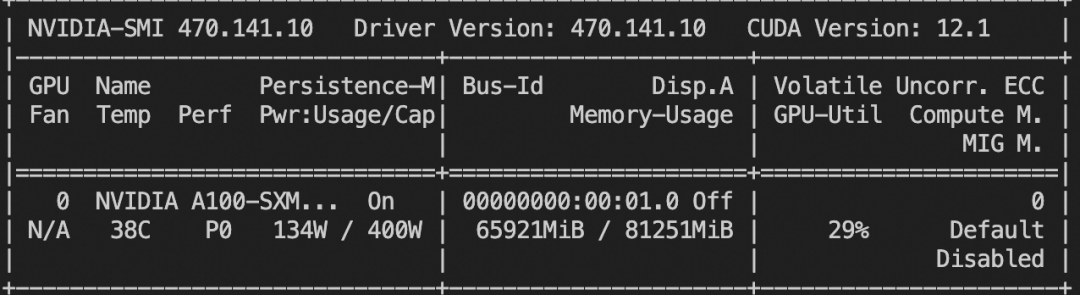
训练(lora+mp)
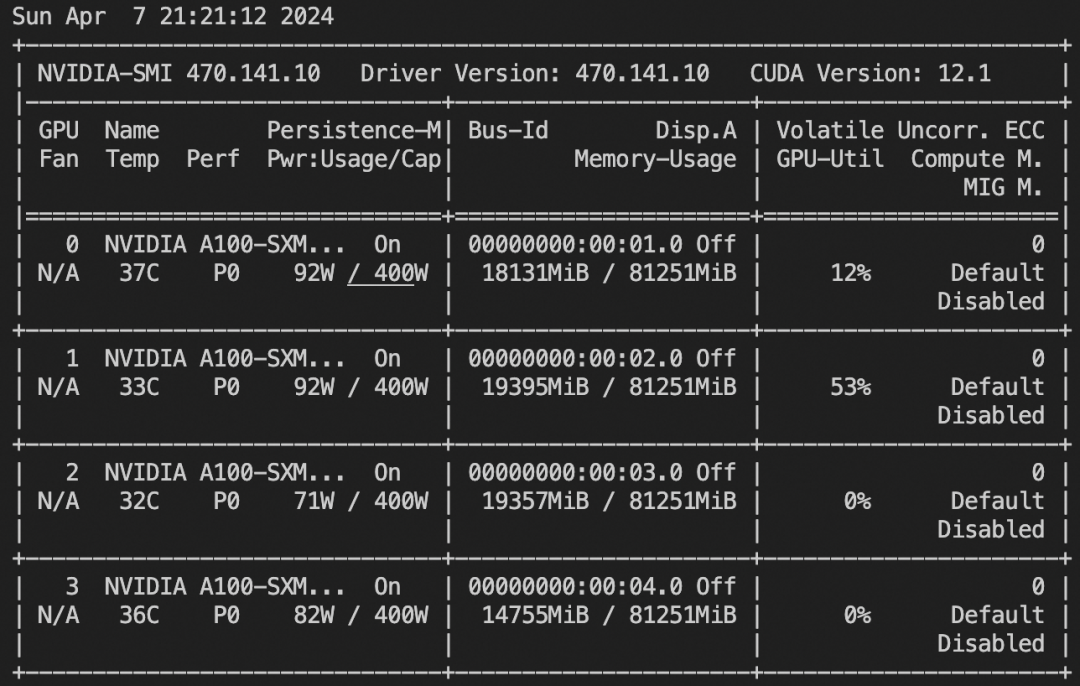
训练后推理
这篇关于元象4.2B参数 MoE大模型实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




