本文主要是介绍最强MoE完全开源模型发布啦~,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

这篇文章介绍了OLMOE(Open Mixture-of-Experts Language Models)系列模型,这是一款开源的稀疏混合专家模型。OLMOE-1B-7B拥有70亿参数,但每个输入令牌仅使用10亿参数。该模型在5万亿令牌上进行预训练,并进一步适应以创建OLMOE-1B-7B-INSTRUCT。这些模型在相似活跃参数的模型中表现最佳,甚至超越了更大的模型,如Llama2-13B-Chat和DeepSeekMoE-16B。文章还展示了在MoE训练上的各种实验,分析了模型中的路由,显示了高度专业化,并开源了工作的所有方面:模型权重、训练数据、代码和日志。
论文:OLMoE: Open Mixture-of-Experts Language Models
地址:https://arxiv.org/pdf/2409.02060
一、研究背景
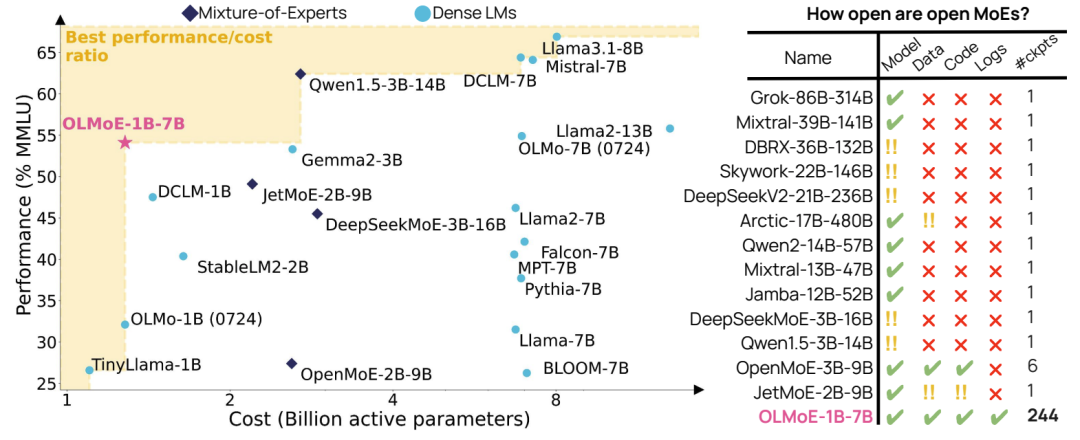
提出OLMoE:一种完全开放且最先进的语言模型,利用稀疏的MoE(Mixture-of-Experts)。OLMOE-1B-7B模型在相似活跃参数数量的情况下,表现优于所有可用的模型,甚至超过了更大的模型如Llama2-13B-Chat和DeepSeekMoE-16B。
研究难点:MoE模型需要在每层有多个专家,但每次只激活其中的一部分,这使得MoE在训练和推理效率上显著优于密集模型。然而,现有的MoE模型大多是闭源的,缺乏训练数据、代码和训练方法的开放资源,这限制了研究的进展和开源MoE模型的发展。
相关工作:之前的研究表明,MoE模型在计算效率和参数数量上有显著优势,但大多数MoE模型仍然是闭源的。已有的开源MoE模型如OpenMoE的性能有限,无法与闭源的前沿模型相媲美。
二、研究方法
这篇论文提出了OLMOE模型用于解决MoE模型在开放性和性能上的不足。具体来说:
模型架构:OLMOE是一个解码器only的LM,由NL transformer层组成。密集模型中的前馈网络(FFN)被MoE模块替代,MoE模块由多个较小的FFN模块(称为专家)组成,每个输入标记只激活其中的一个子集。
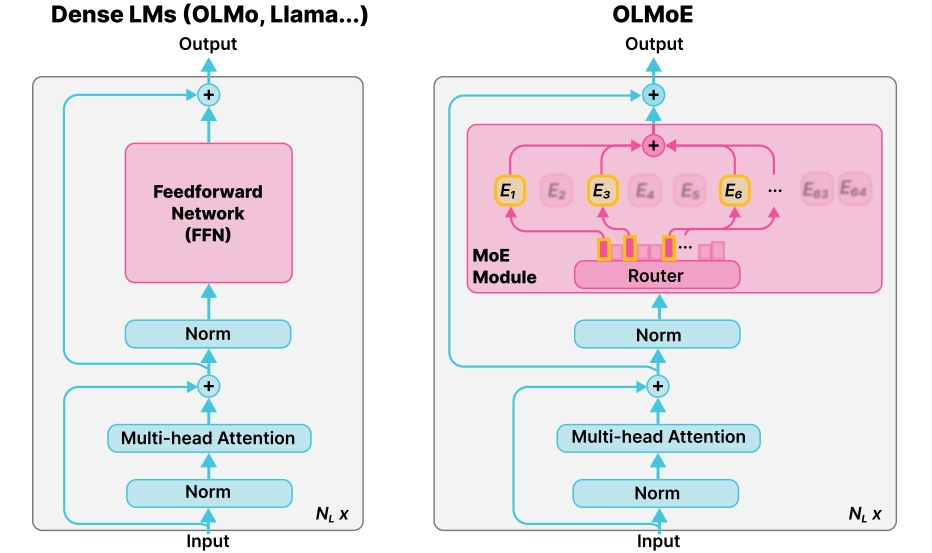
关键设计决策:
专家粒度:使用64个小专家,每层激活8个。
路由算法:采用无dropout的标记选择路由。
辅助损失:使用负载平衡损失(LLB)和路由器z损失(LRZ)来优化模型的训练。
数据集:使用DCLM和Dolma 1.7的数据集进行预训练,数据集包括Common Crawl、StarCoder、arXiv等。
训练过程:OLMOE-1B-7B从头开始训练,总共训练5.133T标记。在训练的退火阶段,先重新打乱整个数据集,然后线性衰减学习率至0。
三、实验设计
数据收集:预训练数据来自DCLM和Dolma 1.7,包括Common Crawl、StarCoder、arXiv等高质量数据集。适应训练数据包括Tulu 2 SFT Mix、Various、CodeFeedback-Filtered-Instruction等。
实验设置:在预训练过程中,使用多种下游任务进行评估,包括MMLU、ARC-C、BoolQ等。适应训练过程中,使用指令调优(SFT)和偏好调优(DPO)来提升模型性能。
参数配置:使用AdamW优化器,混合精度训练,初始化为截断正态分布,学习率设置为5.0E-4,训练5T标记。适应训练过程中,SFT使用BF16全局批量大小为128,DPO使用RMSProp优化器,批量大小为32。
四、结果与分析
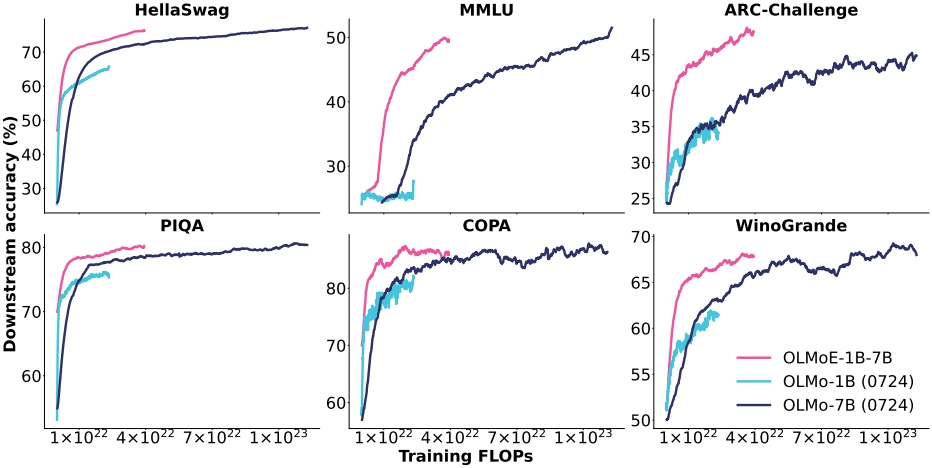
预训练结果:在预训练过程中,OLMOE-1B-7B在所有任务上的表现均优于现有的OLMo模型,且计算成本更低。
适应训练结果:适应训练后,OLMOE-1B-7B在指令调优和偏好调优任务上表现优异,平均得分最高。
五、总体结论
本文提出的OLMOE模型在性能和开放性上均达到了新的高度,成为第一个完全开放且最先进的MoE语言模型。通过开源OLMOE-1B-7B及其相关资源,本文旨在推动MoE模型的研究和发展,帮助研究者更好地理解和改进这些模型。未来的工作将包括增加参数数量、训练数据量、探索多模态和跨语言应用。
AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
这篇关于最强MoE完全开源模型发布啦~的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







