本文主要是介绍MoE-LLaVA:为大型视觉-语言模型引入专家混合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着人工智能技术的飞速发展,大型视觉-语言模型(LVLMs)在图像理解和自然语言处理方面展现出了巨大的潜力。这些模型通过结合图像编码器和语言模型,能够处理包括图像描述、视觉问答和图像字幕生成等在内的多种任务。然而,现有模型在训练和推理时存在巨大的计算成本,这限制了它们的应用范围和效率。
方法
为了解决这一挑战,本文提出了一种名为MoE-LLaVA的新型LVLM架构,它基于专家混合(MoE)的概念。MoE-LLaVA的核心思想是通过在模型中引入多个专家(experts),并通过路由器(router)动态地将输入数据分配给这些专家,从而实现模型的稀疏性,降低计算成本。
MoE-LLaVA模型的架构设计是其创新性的核心,它通过精心设计的组件来实现高效的多模态学习能力。下面详细介绍这些组件:
视觉编码器(Vision Encoder)
视觉编码器是模型的首要组件,其任务是接收原始图像输入并将其转换成一系列视觉令牌(token)。这些令牌是图像的高级表示,捕捉了图像中的关键信息,如形状、颜色、纹理等。视觉编码器通常由卷积神经网络(CNN)或Transformer架构组成,它们能够从图像中提取丰富的特征。
视觉投影层(Visual Projection Layer)
视觉投影层位于视觉编码器之后,其功能是将视觉令牌映射到一个与语言模型隐藏层维度兼容的空间。这一步骤至关重要,因为它确保了视觉信息能够无缝地与语言模型的文本信息进行交互。通过这种方式,模型能够将视觉数据和文本数据统一到一个共同的表示空间中。
词嵌入层(Word Embedding Layer)
词嵌入层负责处理文本输入。它将输入的文本序列转换为一系列的词向量(word embeddings),这些向量是连续的数值表示,能够捕捉单词的语义信息。这些词向量随后可以与视觉令牌一起输入到模型中,使得模型能够理解和生成语言。
多层LLM块(Multi-layer LLM Blocks)
在MoE-LLaVA中,多层LLM块是建立在大型语言模型之上的关键组件,用于处理和融合文本和视觉数据。这些块通常包含多头自注意力机制(multi-head self-attention)和前馈神经网络(FFN),它们能够处理长距离依赖关系,并学习数据中的复杂模式。
MoE块(MoE Blocks)
MoE块是MoE-LLaVA架构中的创新点,它由多个专家(experts)组成,每个专家是一个前馈神经网络(FFN)。这些专家通过一个路由器(router)接收输入数据,路由器负责动态地将输入令牌分配给最合适的专家。这种设计允许模型在保持大量参数的同时,只激活和训练一部分专家,从而实现计算的稀疏性。
MoE-Tuning是MoE-LLaVA模型的训练策略,它通过精心设计的三个阶段,引导模型逐步学习处理多模态数据,最终实现高效的学习和推理。
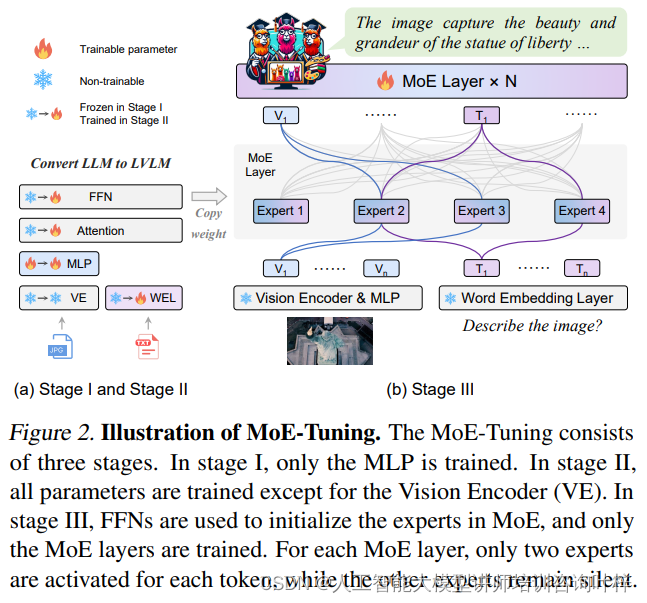
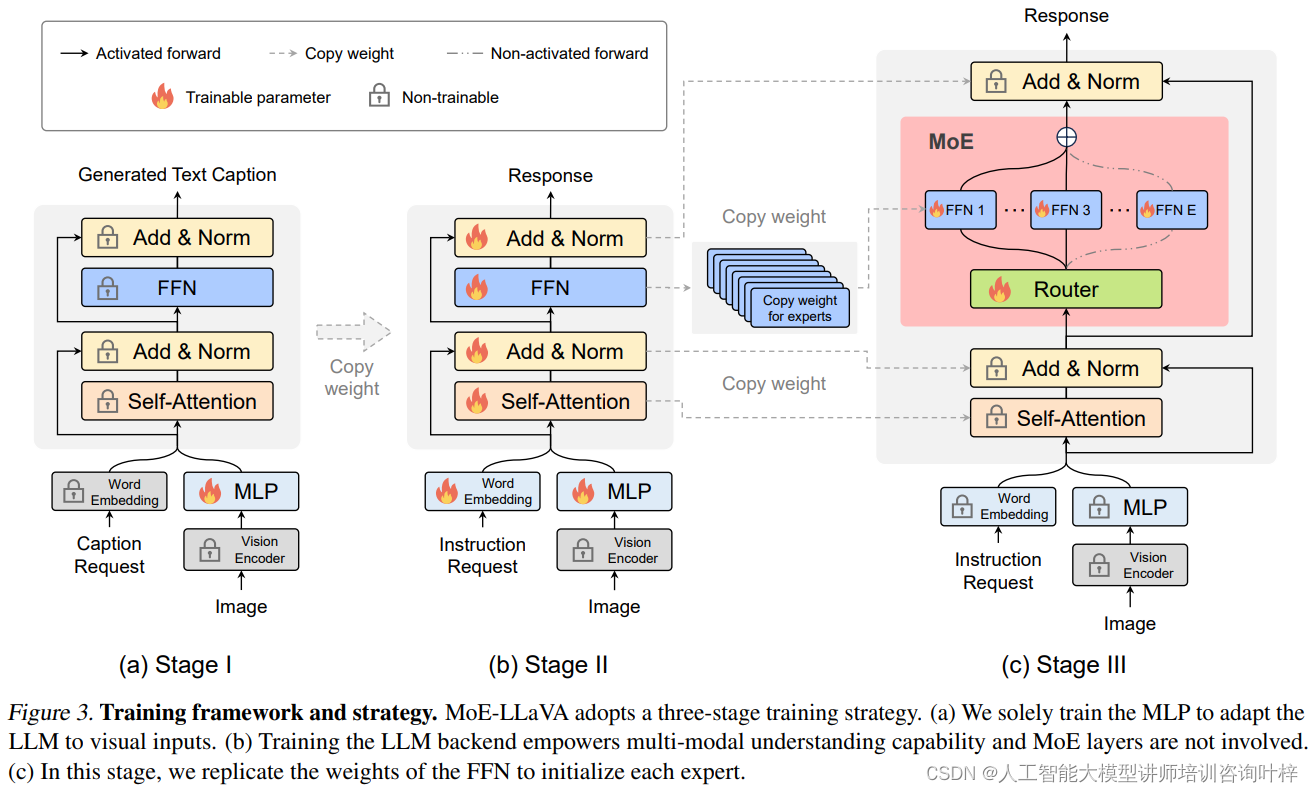
第一阶段:MLP训练
在MoE-Tuning的初始阶段,重点放在训练一个多层感知器(MLP)上。MLP是一个简单的神经网络,它能够对输入数据进行线性变换和非线性激活。在这个阶段,MLP的主要任务是将视觉编码器输出的视觉令牌转换成一种形式,使其能够与大型语言模型(LLM)兼容。这个过程是至关重要的,因为它为模型提供了一种机制,使其能够理解和解释视觉数据中的关键特征,并将其与语言模型的文本处理能力相结合。
第二阶段:LLM参数训练
在MLP成功适配视觉输入之后,训练进入第二阶段,此时重点转移到整个大型语言模型(LLM)的参数上。在这一阶段,模型通过多模态指令数据进行微调,这意味着模型将学习如何同时处理文本和视觉信息,并在这两种模态之间建立联系。通过这种方式,模型不仅能够理解图像内容,还能够理解与图像相关的文本描述,从而增强其对多模态数据的理解和生成能力。
第三阶段:MoE层训练
在前两个阶段的基础上,第三阶段专注于训练MoE层。在这个阶段,模型的FFN(Feed-Forward Network)权重被复制并用作MoE层中各个专家的初始化权重。MoE层由多个专家组成,每个专家都是一个小型的神经网络,能够处理一部分输入数据。通过训练,模型学习如何通过路由器动态地将输入数据分配给最合适的专家。这种训练方式使得模型能够更有效地利用其参数,因为只有与当前任务最相关的专家会被激活,而其他专家则保持不活跃状态,从而实现计算资源的节省。
通过这三个阶段的训练,MoE-LLaVA模型不仅能够学习到如何有效地处理多模态数据,还能够实现模型的稀疏性,即在保持大量参数的同时,只激活和训练一部分专家。这种稀疏性使得模型在处理数据时能够更加灵活和高效,同时降低了训练和推理时的计算成本,使MoE-LLaVA能够在多模态任务上展现出与更大、更密集模型相媲美甚至更优的性能。
实验
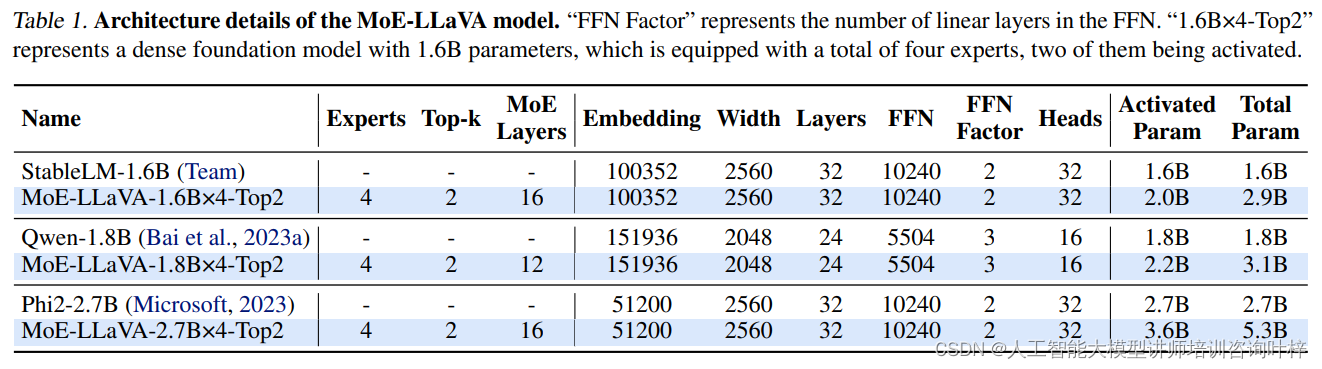
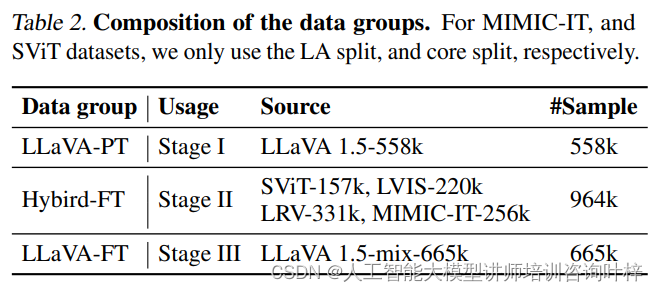
实验的基础是构建一个多元化的数据集,它结合了LLaVA-PT、Hybird-FT和LLaVA-FT等不同的数据源。这些数据集不仅在规模上有所不同,涵盖了从558k到665k的样本量,而且在内容上也各具特色,能够全面考验模型的多模态学习能力。在MoE-LLaVA模型的配置上,研究者尝试了不同数量的专家和不同数量的激活专家,这一策略允许模型在保持参数总量不变的情况下,通过调整激活专家的数量来优化性能。
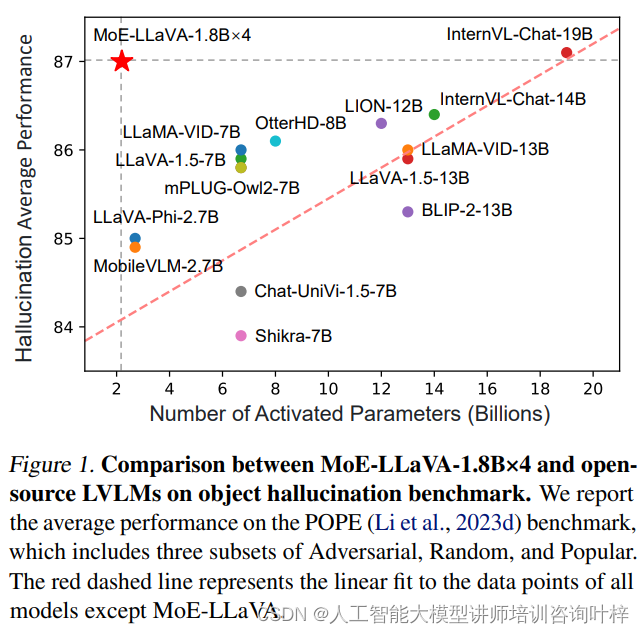
在图像问答任务中,MoE-LLaVA在五个基准测试上的表现与当前最先进方法相当,这证明了其在图像理解方面的强大能力。特别是在ScienceQA和POPE这两个基准测试上,MoE-LLaVA即便使用了较少的激活参数,也能达到与参数量更大的模型相媲美的性能。

表中的“*”表示某些模型在训练数据上存在重叠,而“†”表示模型是使用384分辨率的图像进行训练的。为了直观展示结果,表中用粗体和下划线分别表示了最佳和次佳的结果。
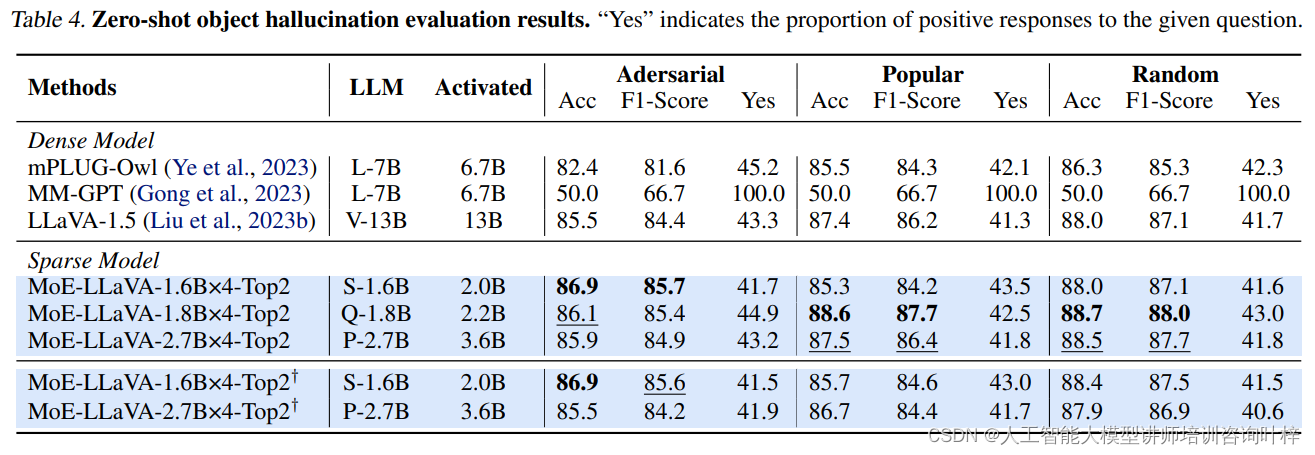
对象幻觉任务要求模型能够根据给定的图像生成相应的描述或解释。MoE-LLaVA在POPE评估方法下展现了卓越的性能,它生成的对象描述与图像内容高度一致,显示出模型在理解和生成视觉内容方面的强大能力。在某些情况下,MoE-LLaVA甚至超过了参数量更大的模型,表明MoE-LLaVA在对象幻觉任务上具有显著的优势。
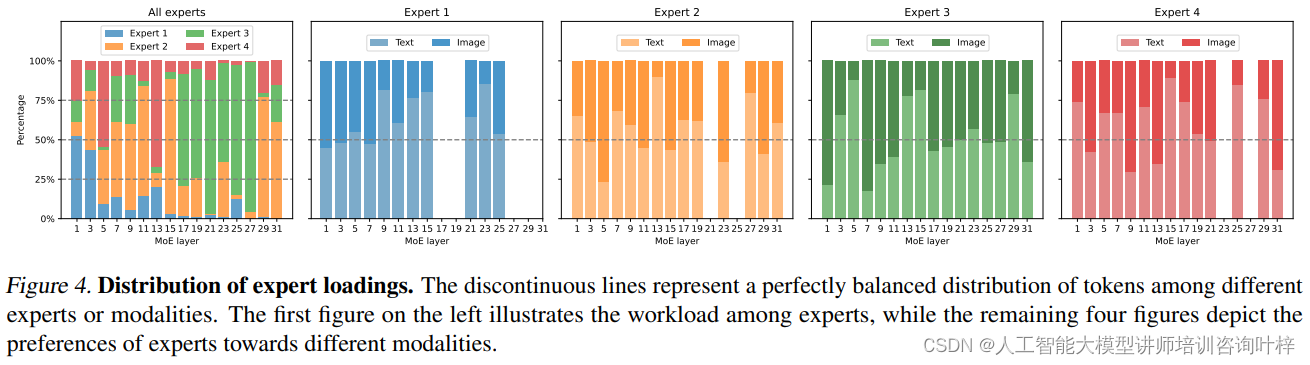
为了深入理解MoE-LLaVA模型的内部工作机制,研究者进行了定量分析。通过分析不同专家的负载和模态偏好发现MoE-LLaVA的专家能够平衡地处理文本和图像数据。随着模型深度的增加,专家之间的任务分配呈现出特定的模式,这表明MoE-LLaVA能够根据数据的特点动态调整其处理策略,以实现最优的性能。
在消融研究研究中验证了三阶段训练策略的必要性,并探讨了不同基础模型、专家数量和激活专家数量对模型性能的影响。结果表明,MoE-LLaVA的架构设计能够有效地提高模型的多模态理解能力,尤其是在处理复杂的视觉和语言任务时。
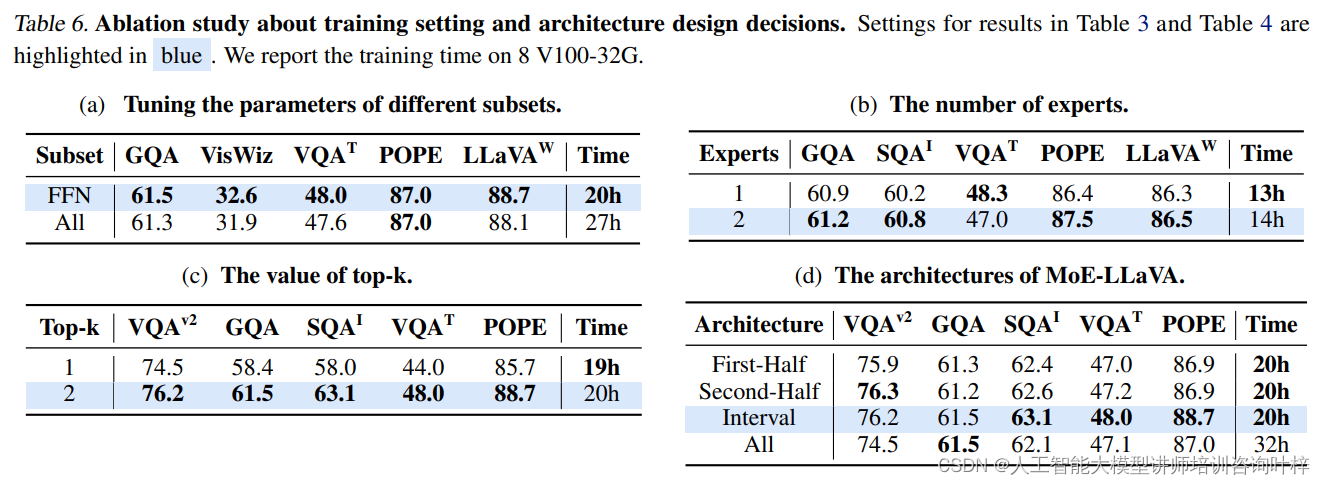
上表中,一些特定的设置结果中被突出显示为蓝色。表6还报告了在8个V100-32G GPU上进行训练所需的时间。V100是NVIDIA推出的一款高性能GPU,广泛应用于深度学习训练任务,32G指的是每个GPU拥有32GB的显存。
实验结果表明,MoE-LLaVA在保持计算成本恒定的同时,能够与参数量更大的模型竞争,为未来多模态学习系统的发展提供了宝贵的见解。随着人工智能技术的不断进步,MoE-LLaVA有望在多模态理解和对象想象等领域发挥更大的作用。
论文链接:https://arxiv.org/pdf/2401.15947
Github:https://github.com/PKU-YuanGroup/MoE-LLaVA
Demo: https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
这篇关于MoE-LLaVA:为大型视觉-语言模型引入专家混合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







