llava专题

Linux系统本地化部署Dify并安装Ollama运行llava大语言模型详细教程
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学习,不断总结,共同进步,活到老学到老导航 檀越剑指大厂系列:全面总结 java 核心技术,jvm,并发编程 redis,kafka,Spring,微服务等常用开发工具系列:常用的开发工具,IDEA,M

LLaVA-MoLE:解决多模态大模型指令微调中的数据冲突问题
人工智能咨询培训老师叶梓 转载标明出处 多模态大模型(MLLMs)通过指令微调(instruction finetuning),能够执行各种任务,如理解图表、处理文档和回答基于图像的问题。但是,当从不同领域混合指令数据进行微调时,模型在特定领域的任务上可能会出现性能下降。这种现象被称为数据冲突,它限制了通过增加新领域训练数据来扩展MLLM能力的可能性。为了应对这一挑战,来自美团公司的研究者们提出

多模态基础模型:LLAVA系列大解读
〔探索AI的无限可能,微信关注“AIGCmagic”公众号,让AIGC科技点亮生活〕 本文作者:AIGCmagic社区 刘一手 前言 在人工智能领域,多模态大模型正成为研究的热点。作为一种能够处理和理解多种模态数据(如文本、图像、声音等)的人工智能模型,LLAVA系列多模态大模型以其强大的表现力和广泛的应用前景,吸引了众多科研人员和企业关注。本文将为您带来LLAVA多模态大模型系列

LLaVA 简介:一种多模式 AI 模型
LLaVA 是一个端到端训练的大型多模态模型,旨在根据视觉输入(图像)和文本指令理解和生成内容。它结合了视觉编码器和语言模型的功能来处理和响应多模态输入。 图 1:LLaVA 工作原理的示例。 LLaVA 的输入和输出:连接视觉和文本领域: LLaVA 的输入有两个方面: 视觉输入:模型可以查看和分析以提取视觉特征和上下文信息的图像。文本指令:文本输入,可以是问题或命令,指

测试多模态模型LlaVa
目录 Linux上安装ollama ollama上安装llava 上传图片到服务器 测试 评价 Linux上安装ollama curl -fsSL https://ollama.com/install.sh | sh ollama上安装llava ollama run llava 上传图片到服务器 测试 评价 相比其他多模态模型,生成的内容非常详细,能够捕
MoE-LLaVA:为大型视觉-语言模型引入专家混合
随着人工智能技术的飞速发展,大型视觉-语言模型(LVLMs)在图像理解和自然语言处理方面展现出了巨大的潜力。这些模型通过结合图像编码器和语言模型,能够处理包括图像描述、视觉问答和图像字幕生成等在内的多种任务。然而,现有模型在训练和推理时存在巨大的计算成本,这限制了它们的应用范围和效率。 方法 为了解决这一挑战,本文提出了一种名为MoE-LLaVA的新型LVLM架构,它基于专家混合(MoE)的概
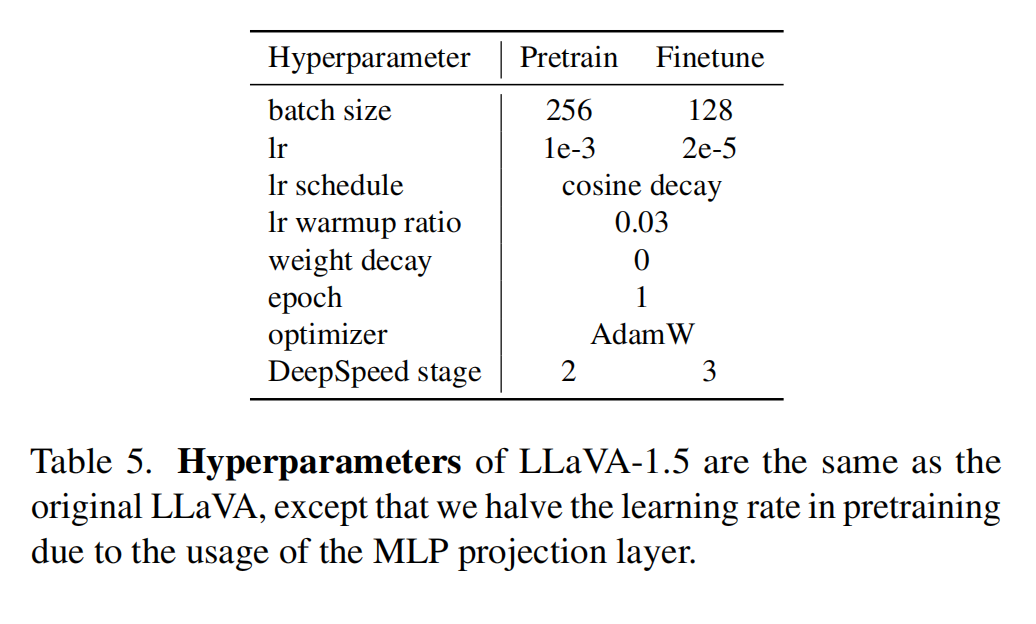
【多模态】34、LLaVA-v1.5 | 微软开源,用极简框架来实现高效的多模态 LMM 模型
文章目录 一、背景二、方法2.1 提升点2.2 训练样本 三、效果3.1 整体效果对比3.2 模型对于 zero-shot 形式的指令的结果生成能力3.3 模型对于 zero-shot 多语言的能力3.4 限制 四、训练4.1 数据4.2 超参 五、代码 论文:Improved Baselines with Visual Instruction Tuning 代码:http

视觉语言大模型llava学习
1. 拉取 https://github.com/haotian-liu/LLaVA 视觉语言大模型是人工智能领域一种重要的多模态模型,它结合了计算机视觉(CV)和自然语言处理(NLP)的技术,使得模型能够同时理解图像和文本信息。这类模型在多种任务上表现出卓越的性能,包括图片描述生成、基于文本的图像检索、视觉问答(VQA)、自动图像标注以及新颖的文本到图片生成等。 下面是一些著名的视觉语言大

英伟达发布 VILA 视觉语言模型,实现多图像推理、增强型上下文学习,性能超越 LLaVA-1.5
前言 近年来,大型语言模型 (LLM) 的发展取得了显著的成果,并逐渐应用于多模态领域,例如视觉语言模型 (VLM)。VLM 旨在将 LLM 的强大能力扩展到视觉领域,使其能够理解和处理图像和文本信息,并完成诸如视觉问答、图像描述生成等任务。然而,现有的 VLM 通常缺乏对视觉语言预训练过程的深入研究,导致模型在多模态任务上的性能和泛化能力受限。为了解决这个问题,英伟达的研究人员发布了 VILA

第十一节 LLAVA模型lora训练(包含lora权重预加载与源码解读)
文章目录 前言一、语言模型加载1、语言模型加载2、语言模型训练处理a、embeding处理b、语言模型lora训练处理lora参数配置peft配置语言模型lora参数 c、语言模型tokenizer加载加载tokenizer设置对话开头语句 二、视觉模型加载1、加载图像模型主函数源码解读2、initialize_vision_modules函数源码解读
十一、多模态大语言模型(LLaVA)
1 LLaVA多模态大语言模型的训练过程 两个阶段 特征对齐的预训练。只更新特征映射矩阵端到端微调。特征投影矩阵和LLM都进行更新 2 LLaVA1.5多模态大语言模型的训练 LLaVA官网 python -m llava.serve.controller --host 0.0.0.0 --port 10000python -m llava.serve.gradio_web_se

第七节 LLAVA模型训练流程与方法
文章目录 前言一、训练模式方法二、lora形式fitune训练步骤第一步:lora形式fitune的launch.json配置第二步:train_mem.py第三步:模型参数配置(train())第四步:语言模型加载第五步:语言模型梯度、量化、lora训练方法设定第六步:语言模型的tokenizer第七步:根据model_args.version版本配置内容第八步:视觉模型模块加载第九步:继
(Chat For Al,创新Al,汇语Al助手,AiTab新标签,万能助手,LLaVA)分享6个好用的ChatGPT
目录 1、Chat For AI 2、创想AI 3、汇语AL助手

多模态 ——LLaVA 集成先进图像理解与自然语言交互GPT-4的大模型
概述 提出了一种大型模型 LLaVA,它使用 GPT-4 生成多模态语言图像指令跟随数据,并利用该数据将视觉和语言理解融为一体。初步实验表明,LLaVA 展示了出色的多模态聊天能力,在合成多模态指令上的表现优于 GPT-4。 在科学质量保证中进行微调时,LLaVA 和 GPT-4 的协同作用实现了新的一流准确性。 论文链接:http://arxiv.org/abs/2304.08485 代码链
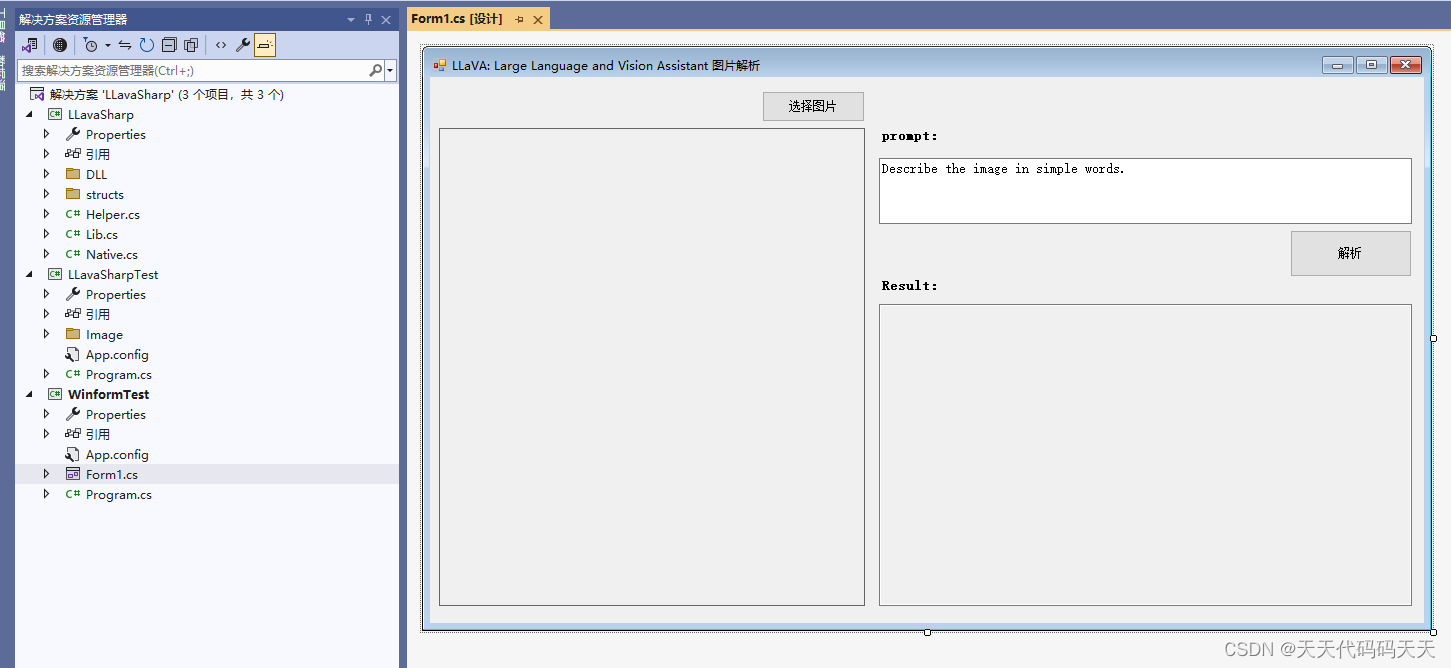
LLaVA: Large Language and Vision Assistant 图片解析 图生文
LLaVA: Large Language and Vision Assistant 图片解析 图生文 目录 介绍 效果 编辑项目 测试代码 Form1.cs Helper.cs 下载 介绍 LLaVA,一种新的大型多模态模型,称为“大型语言和视觉助手”,旨在开发一种通用视觉助手,可以遵循语言和图像指令来完成各种现实世界的任务。 这个想法是将 GPT-

【LLM多模态】Cogview3、DALL-E3、CogVLM、LLava模型
note 文章目录 noteVisualGLM-6B模型图生文:CogVLM-17B模型0. 直接部署推理模型Situation 2.1 CLI (SAT version)Situation 2.2 CLI (Huggingface version)Situation 2.3 Web Demo 1. 模型架构2. 模型效果3. 训练数据:CogVLM-SFT-311K数据集信息数据集数量数
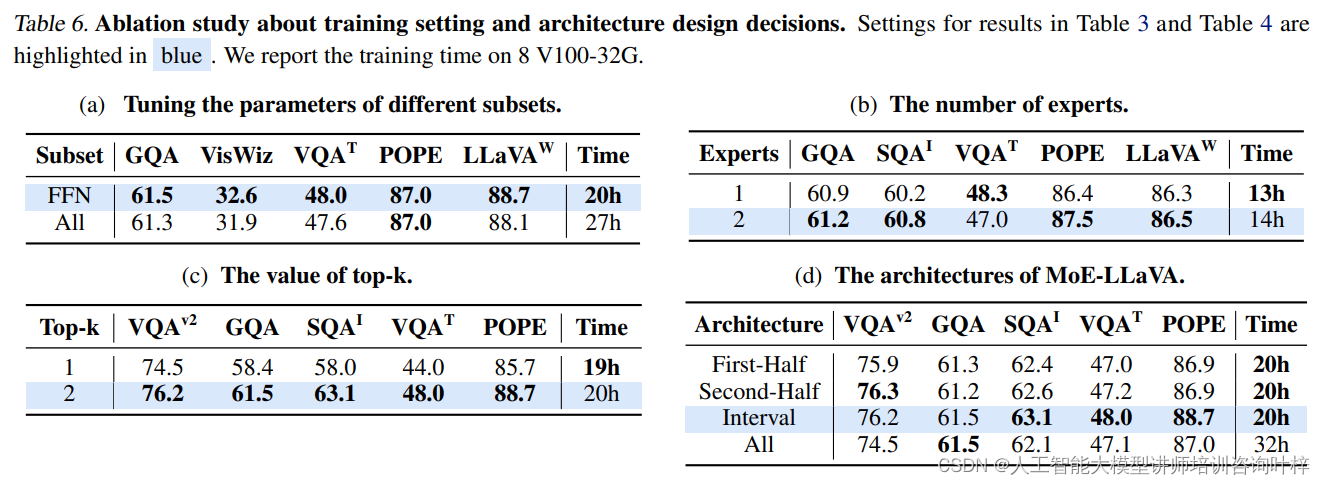
VLM 系列——MoE-LLaVa——论文解读
一、概述 1、是什么 moe-Llava 是Llava1.5 的改进 全称《MoE-LLaVA: Mixture of Experts for Large Vision-Language Models》,是一个多模态视觉-文本大语言模型,可以完成:图像描述、视觉问答,潜在可以完成单个目标的视觉定位、名画名人等识别(问答、描述),未知是否能偶根据图片写代码(HTML、JS、CSS)。支
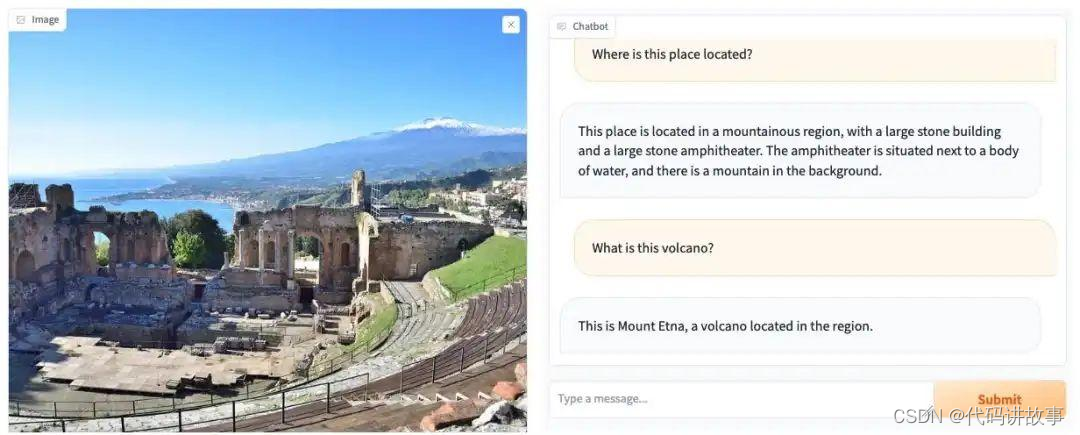
LLaVA:GPT-4V(ision) 的新开源替代品
LLaVA:GPT-4V(ision) 的新开源替代品。 LLaVA (https://llava-vl.github.io/,是 Large Language 和Visual A ssistant的缩写)。它是一种很有前景的开源生成式 AI 模型,它复制了 OpenAI GPT-4 在与图像对话方面的一些功能。 用户可以将图像添加到 LLaVA 聊天对话中,可以以聊天方式讨论这些图像的内
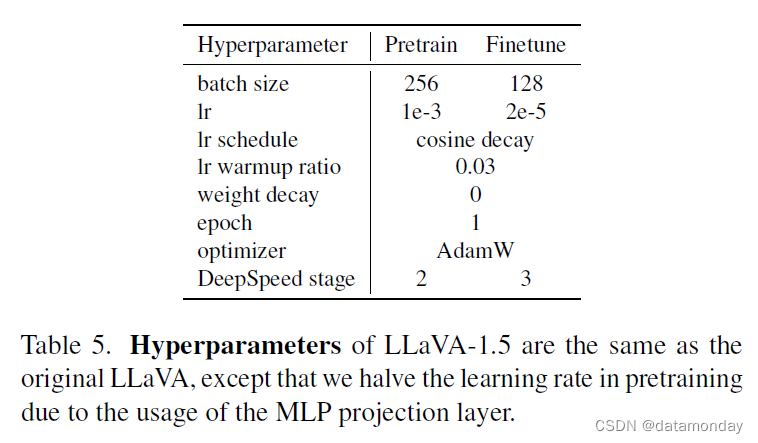
【LMM 002】大型语言和视觉助手 LLaVA-1.5
论文标题:Improved Baselines with Visual Instruction Tuning 论文作者:Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee 作者单位:University of Wisconsin-Madison, Microsoft Research, Columbia University 论文原文:https:
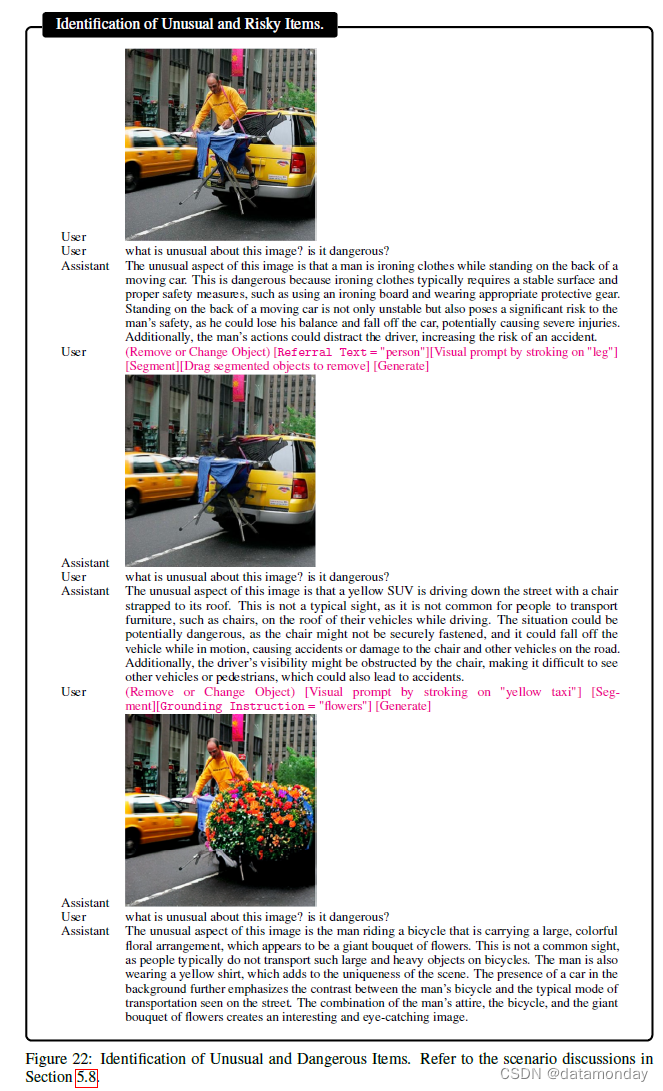
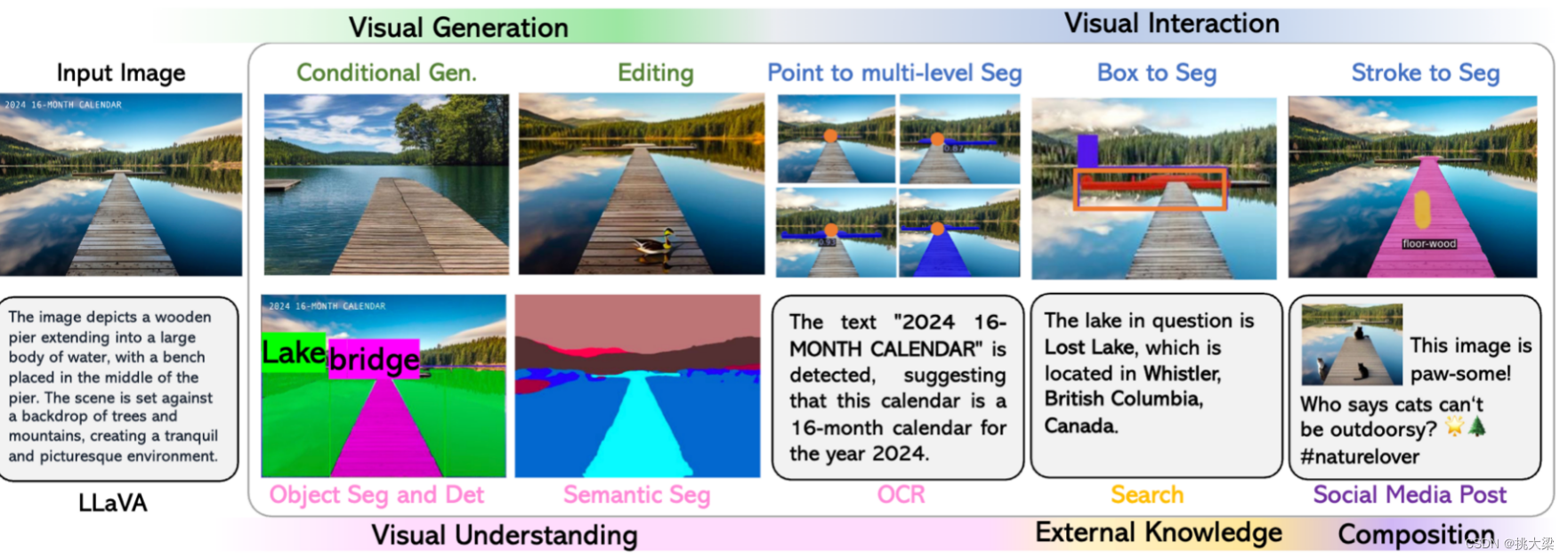
【LMM 005】LLaVA-Interactive:集图像聊天,分割,生成和编辑三种多模态技能于一体的Demo
论文标题:LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing 论文作者:Wei-Ge Chen, Irina Spiridonova, Jianwei Yang, Jianfeng Gao, Chunyuan Li 作者单位:Microsoft Research, R
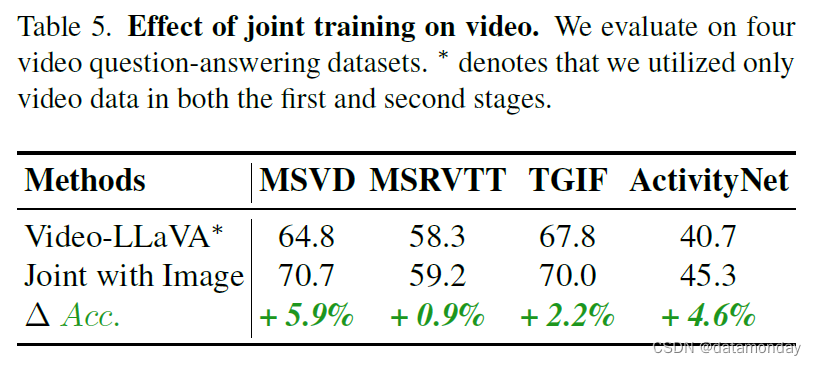
【LMM 007】Video-LLaVA:通过投影前对齐以学习联合视觉表征的视频多模态大模型
论文标题:Video-LLaVA: Learning United Visual Representation by Alignment Before Projection 论文作者:Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan 作者单位:Peking University, Peng Cheng Labo

【LMM 006】LLaVA-Plus:可以学习如何使用工具的多模态Agent
论文标题:LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents 论文作者:Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang,
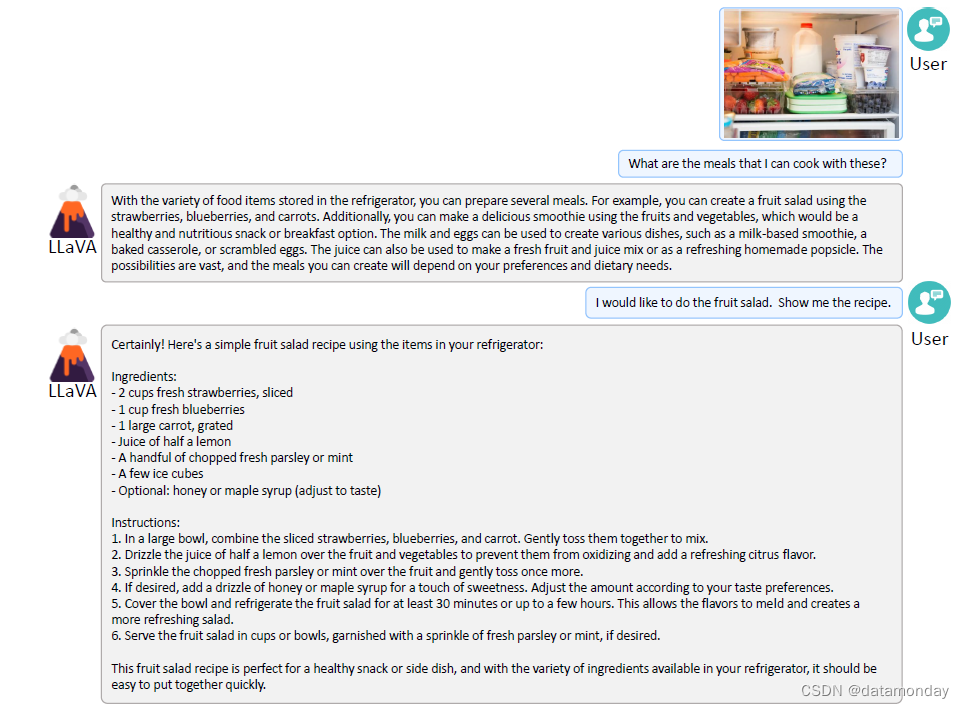
【LMM 001】大型语言和视觉助手 LLaVA
论文标题:Visual Instruction Tuning 论文作者:Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee 作者单位:University of Wisconsin-Madison, Microsoft Research, Columbia University 论文原文:https://arxiv.org/abs/2304.0
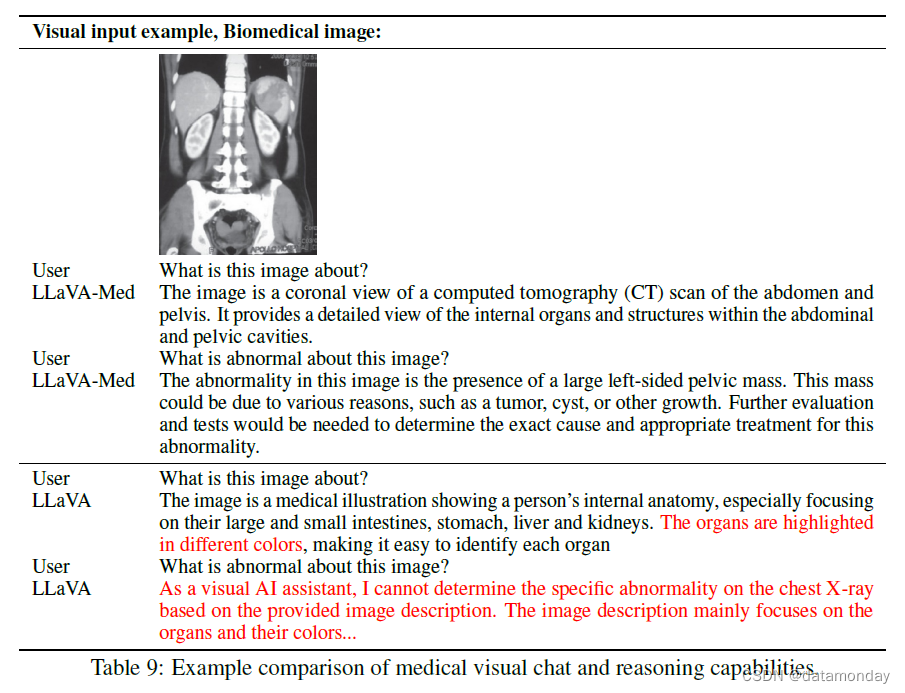
【LMM 003】生物医学领域的垂直类大型多模态模型 LLaVA-Med
论文标题:LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day 论文作者:Chunyuan Li∗, Cliff Wong∗, Sheng Zhang∗, Naoto Usuyama, Haotian Liu, Jianwei Yang Tristan Naumann, Hoifu
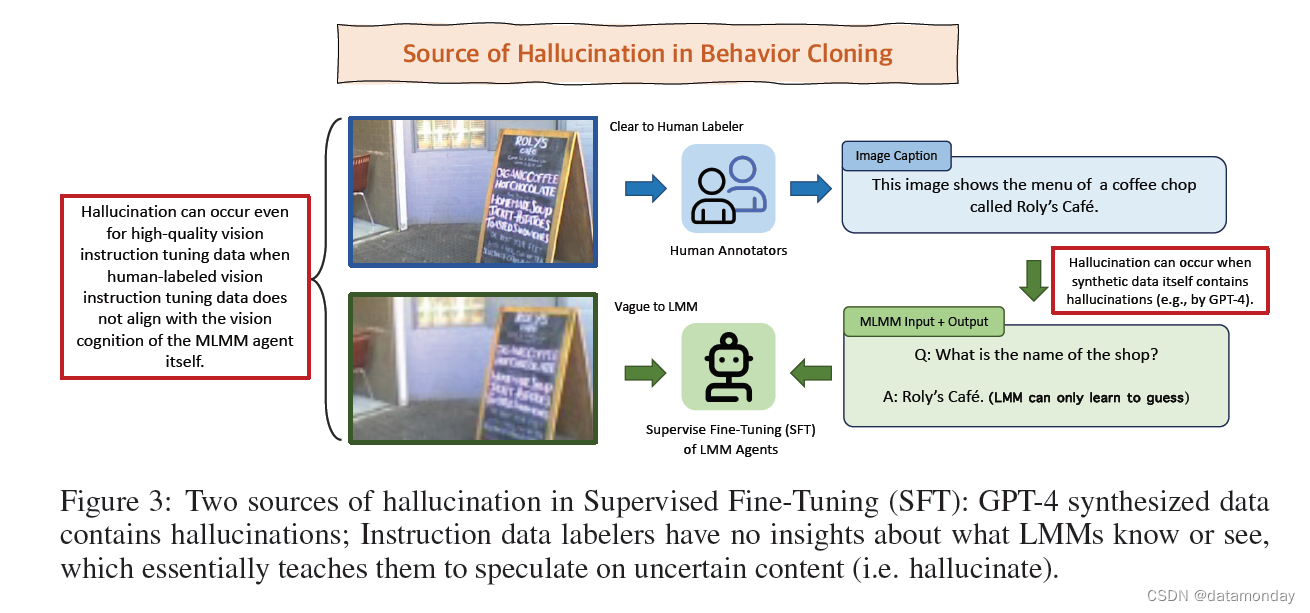
【LMM 004】LLaVA-RLHF:用事实增强的 RLHF 对齐大型多模态模型
论文标题:Aligning Large Multimodal Models with Factually Augmented RLHF 论文作者:Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming