本文主要是介绍多模态 ——LLaVA 集成先进图像理解与自然语言交互GPT-4的大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
提出了一种大型模型 LLaVA,它使用 GPT-4 生成多模态语言图像指令跟随数据,并利用该数据将视觉和语言理解融为一体。初步实验表明,LLaVA 展示了出色的多模态聊天能力,在合成多模态指令上的表现优于 GPT-4。 在科学质量保证中进行微调时,LLaVA 和 GPT-4 的协同作用实现了新的一流准确性。
论文链接:http://arxiv.org/abs/2304.08485
代码链接:https://github.com/haotian-liu/LLaVA
demo链接:https://llava-vl.github.io/
导言
本文的重点是开发结合视觉和语言的人工智能助手。在传统模型中,每项任务都是独立解决的,语言只能描述图像内容。然而,随着大规模语言模型(LLM)的发展,语言能够指导各种各样的任务。本文介绍了一种名为视觉指令调整的新技术,该技术可生成视觉数据来构建大规模多模态模型(LMM)。生成的数据用于微调 LMM,并构建通用的指令跟随视觉代理。 使用 GPT-4 在科学 QA 多模态推理数据集上实现卓越性能。
相关研究
本文将重点讨论如何构建能够遵从视觉和语言指令的代理。现有工作大致可分为端到端训练模型和通过 LangChain 等系统调整不同模型的模型。我们还将自然语言处理(NLP)研究中提出的 LLM 指令调整方法应用于视觉任务,目的是建立一个通用的指令遵循视觉代理。我们认为,这将提高对指令的有效理解和概括,并可能适用于新的多模态任务。
GPT 辅助生成视觉指示数据
虽然社会上公开的图像和文本数据激增,但多模态教学数据却很有限。为了应对这一挑战,有人提议使用 ChatGPT/GPT-4 从大量图像对数据中收集多模态教学数据。

我们提出了一种使用 GPT-4 生成基于图像-文本对的自然问题的方法。由于通常的扩展方法缺乏多样性和深度推理,因此提出了一种方法,利用纯语言 GPT-4 和 ChatGPT 作为教师,生成遵循视觉指令的数据。使用符号表示法对图像进行编码,生成不同类型的指令遵循数据。研究表明,GPT-4 可以提供高质量的指令跟随数据,而且比普通的数据增强方法效果更好。
视觉指令的调整
模型架构
主要目标是有效利用预训练 LLM 和视觉模型的能力。 网络架构如图 1 所示。

LaMA(Large Language Model for Instructions Following)即大型语言模型fφ(⋅),由参数 φ 参数化。这是因为它在仅针对开源语言的指令调整工作中被证明是有效的。ViT-L/14 提供视觉特征 Zv=g(Xv),并使用可训练的投影矩阵 W 将图像特征转换为语言嵌入标记 Hq。这确保了图像和语言模型具有相同的维度。
 因此,从图像中得出的视觉标记 Hv 过程序列既轻便又高效,可以快速迭代以数据为中心的实验。其他模型,如 Flamingo’s Gate Cross Attention 和 BLIP-2’s Q-former 或 SAM,都提供了对象级功能。未来的研究仍将探索更有效、更复杂的架构设计。
因此,从图像中得出的视觉标记 Hv 过程序列既轻便又高效,可以快速迭代以数据为中心的实验。其他模型,如 Flamingo’s Gate Cross Attention 和 BLIP-2’s Q-former 或 SAM,都提供了对象级功能。未来的研究仍将探索更有效、更复杂的架构设计。

模型训练
对于每幅图像,对话数据由若干个轮次(X1q、X1a、…)组成。XTq, XTa)。其中 T 代表回合总数。所有助手的回答都会被汇总,每个回合中的指令都会被整理为 Xtinstruct。 这种方法产生的多模态指令统一格式如表 2 所示。利用原始的自回归训练目标,对预测标记进行 LLM 指令调整。具体来说,就是计算在长度为 L 的序列中生成目标答案 Xa的概率。
这种方法产生的多模态指令统一格式如表 2 所示。利用原始的自回归训练目标,对预测标记进行 LLM 指令调整。具体来说,就是计算在长度为 L 的序列中生成目标答案 Xa的概率。 在训练模型时,我们考虑了两阶段的指令调整程序。其中,θ 是可训练参数,Xinstruct < i 和 Xa < i 分别是当前预测标记 xi之前所有回合中的指令和答案标记。在条件语句中,明确添加了 Xv,以强调图像是以所有答案为基础的,并且跳过了 Xsystem 消息和之前的所有
在训练模型时,我们考虑了两阶段的指令调整程序。其中,θ 是可训练参数,Xinstruct < i 和 Xa < i 分别是当前预测标记 xi之前所有回合中的指令和答案标记。在条件语句中,明确添加了 Xv,以强调图像是以所有答案为基础的,并且跳过了 Xsystem 消息和之前的所有
该方法也包括两个阶段。在第一阶段,从 CC3M 中选取 595K 对图像-文本,并使用简单的扩展方法将其转换为符合指令的数据,以便将其视为单轮对话。在此,随机抽样的问题被用作图像的指令,而原始标题则被训练为预期答案。在这一阶段,视觉编码器和 LLM 权重是固定的,只有投影矩阵 W 用于最大化可能性。
第二步,固定视觉编码器的权重,更新 LLaVA 的投影层和 LLM 的权重。换句话说,可训练参数就是投影矩阵 W 和 φ。聊天机器人的训练使用收集到的语言图像指令跟踪数据,并对多转和单转回答进行均匀采样;在 ScienceQA 基准中,问题以自然语言或图像的形式提供上下文,助手负责推理过程,推理过程包括在 ScienceQA 基准中,问题以自然语言或图像的形式提供上下文,助手负责推理过程,从多个选项中选择一个答案
安装与部署
获取代码:
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
安装软件包:
conda create -n llava python=3.10 -y
conda activate llava
python -mpip install --upgrade pip # enable PEP 660 support
pip install torch==2.0.1+cu117 torchvision==0.15.2+cu117 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu117
pip install -e .
pip uninstall bitsandbytes
如果想在本地启动 Gradio ui 演示,请依次运行以下命令。如果计划启动多个模型工作器以比较不同检查点之间的差异,只需要一次启动控制器和Web服务器。

启动项目:
python -m llava.serve.controller --host 0.0.0.0 --port 10000
试验
多模态聊天机器人
研究人员开发了一种名为 LLaVA 的新型多模态人工智能模型,并制作了一个聊天机器人演示,展示了它的图像理解和对话能力;LLaVA 仅在 80,000 张图像上进行了训练,并显示出与 GPT-4 相似的推理结果。这表明,LLaVA 可以遵循指令、理解场景并做出适当的回应。其他模型(BLIP-2 和 OpenFlamingo)则侧重于描述图像,对指令的反应有限。定量评估还比较了 LLaVA 和 GPT-4 在 COCO 验证集所选图像上的答题能力,试图从 GPT-4 的评分中了解 LLaVA 的表现。具体结果见表 3。
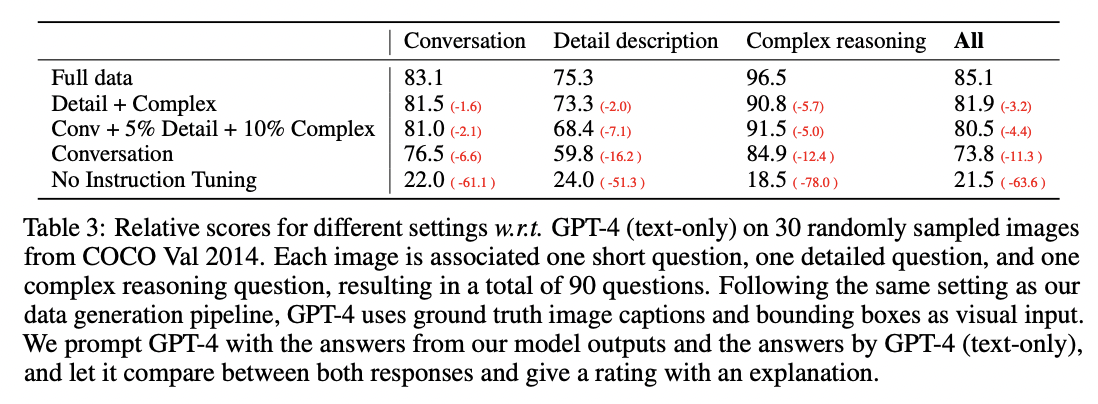
对说明的调整使模型遵循用户说明的能力提高了 50 多个百分点。增加详细说明和复杂推理问题后,模型的整体性能提高了 7 个百分点。模型在会话问题上的表现也有所提高,这表明推理能力与会话能力相辅相成。最后,将三种数据类型结合在一起取得了 85.1% 的最佳性能。该评估方案为全面评估和了解大型多模态模型的功能提供了一个基准。

在研究中,使用新适配器的 LLaVA 在 ScienceQA 数据集上达到了 90.92% 的高准确率,而 GPT-4 的结果为 82.69%。与 LLaVA 和 GPT-4 相结合,则能保持 90.97% 的高准确率。此外,还提出了一种通过再次提示 GPT-4 来生成唯一答案的方案,从而达到了 92.53% 的新的最高准确率。这项研究为利用 LLM 的模型组合提供了新的可能性。通过比较不同条件下的模型性能,我们对科学质量保证任务的适当模型配置有了更好的了解。
结论
本文展示了使用 GPT-4 语言模型进行视觉指令调整的有效性。本文引入了一个新的数据生成管道,以生成遵循语言和图像指令的数据,并在此基础上训练多模态模型 LLaVA。通过微调,ScienceQA 实现了新的 SoTA 准确率,多模态聊天数据实现了卓越的视觉聊天体验。未来的前景包括在更大的数据规模上进行预训练,并与其他视觉模型连接。这有望实现新的功能并提高性能。
这篇关于多模态 ——LLaVA 集成先进图像理解与自然语言交互GPT-4的大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






