本文主要是介绍多模态基础模型:LLAVA系列大解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
〔探索AI的无限可能,微信关注“AIGCmagic”公众号,让AIGC科技点亮生活〕
本文作者:AIGCmagic社区 刘一手
前言
在人工智能领域,多模态大模型正成为研究的热点。作为一种能够处理和理解多种模态数据(如文本、图像、声音等)的人工智能模型,LLAVA系列多模态大模型以其强大的表现力和广泛的应用前景,吸引了众多科研人员和企业关注。本文将为您带来LLAVA多模态大模型系列的深度解读,从原始论文中抽丝剥茧,带您领略这一前沿技术的魅力。

LLaVA(视觉指令微调)
paper:Visual Instruction Tuning
arXiv:https://arxiv.org/pdf/2304.08485
背景概述
1.研究问题:这篇文章要解决的问题是如何利用机器生成的指令跟随数据来调优大型语言模型(LLMs),以提升其在多模态领域的零样本能力。具体来说,作者提出了使用语言模型的图像指令跟随数据来训练一个通用的视觉和语言理解模型。
2.研究难点:该问题的研究难点包括:缺乏视觉语言指令跟随数据、如何有效地将图像文本对转换为指令跟随格式、以及如何在大规模多模态数据上进行模型训练。
3.相关工作:该问题的研究相关工作包括两类:端到端训练的模型和通过LangChain/LLMs协调的各种模型。在指令调优方面,已有研究主要集中在自然语言处理领域,如InstructGPT和ChatGPT等。

研究方法
这篇论文提出了视觉指令调优的方法,用于解决多模态指令跟随问题。具体来说:
- 数据生成:首先,作者提出了一种基于ChatGPT/GPT-4的数据生成方法,将图像文本对转换为指令跟随格式。具体步骤包括:
-
使用图像标题和边界框作为符号表示,将图像编码为LLM可识别的序列。
-
设计对话、详细描述和复杂推理三种类型的指令跟随数据。

-
通过上下文学习查询GPT-4,生成高质量的指令跟随数据。
-
- 模型架构:作者选择Vicuna作为LLM,CLIP作为视觉编码器。具体架构如下:
- 输入图像通过CLIP视觉编码器得到视觉特征
。
- 使用一个简单的线性层将图像特征转换为词嵌入空间的语言嵌入令牌 :
。
- 通过LLM的原始自回归训练目标进行指令调优。
- 输入图像通过CLIP视觉编码器得到视觉特征
- 训练过程:训练分为两个阶段:
- 预训练阶段:固定视觉编码器和LLM权重,最大化图像特征与预训练LLM词嵌入的对齐。
- 微调阶段:保持视觉编码器权重不变,更新投影层和LLM的权重,进行端到端微调。
实验设计
- 数据收集:收集了158K独特的语言图像指令跟随样本,包括58K的对话数据、23K的详细描述数据和77K的复杂推理数据。
- 实验设置:在8x A100s上训练所有模型,预训练阶段在过滤后的CC-595K子集上进行1个epoch,微调阶段在生成的LLaVA-Instruct-158K数据集上进行3个epoch。
- 实验设计:主要评估LLaVA在指令跟随和视觉推理能力方面的表现,分别在多模态聊天机器人和科学问答数据集上进行实验。
结果与分析
- 多模态聊天机器人:
-
LLaVA在多模态聊天机器人实验中表现出色,能够准确回答用户的问题,并提供详细的描述和复杂的推理。

-
与BLIP-2和OpenFlamingo相比,LLaVA在对话和详细描述任务上表现更好。
-
- 科学问答数据集:
- 在科学问答数据集上,LLaVA达到了90.92%的准确率,接近当前最先进的91.68%。
- 通过结合GPT-4的预测结果,LLaVA的最终准确率达到了92.53%,创下了新的最先进记录。

关键问题及回答
问题1:LLaVA模型在生成多模态指令跟随数据时,具体采用了哪些方法来提高数据的质量和多样性?
- 对话数据:设计了一个对话场景,其中助手回答关于图像内容的问题。这些问题包括对象类型、计数、对象动作、对象位置等。
- 详细描述数据:创建了一系列问题,要求助手对图像进行详细描述。这些问题旨在涵盖图像中的各个方面,生成丰富而全面的描述。
- 复杂推理数据:设计了深入推理的问题,答案通常需要逐步推理过程。这些问题要求助手遵循严格的逻辑来回答问题。
此外,作者还通过上下文学习查询GPT-4,生成高质量的指令跟随数据。具体步骤包括:
- 使用图像标题和边界框作为符号表示,将图像编码为LLM可识别的序列。
- 通过上下文学习查询GPT-4,生成高质量的指令跟随数据。
问题2:在科学问答数据集上,LLaVA模型的表现如何,与其他方法相比有何优势?
LLaVA模型在科学问答数据集上达到了90.92%的准确率,接近当前最优方法91.68%。与其他方法相比,LLaVA模型具有以下优势:
- 集成GPT-4:通过与GPT-4的集成,LLaVA的最终准确率达到了92.53%,刷新了记录。具体方法是让GPT-4作为判断者,对LLaVA和GPT-4的回答进行比较,并给出最终答案。
- 多模态推理能力:LLaVA模型不仅能够理解图像内容,还能进行详细的推理和多步骤的逻辑分析,这在科学问答任务中尤为重要。
- 预训练和微调:通过预训练和微调的结合,LLaVA模型在多模态特征对齐和大规模数据上表现出色,显著提高了模型的性能。
问题3:LLaVA模型在多模态聊天机器人实验中表现如何,与BLIP-2和OpenFlamingo相比有何优势?
LLaVA模型在多模态聊天机器人实验中表现出色,能够准确回答用户的问题,并提供详细的描述和复杂的推理。与BLIP-2和OpenFlamingo相比,LLaVA模型具有以下优势:
- 对话能力:LLaVA模型在多轮对话中表现良好,能够持续地与用户进行有意义的交流,并提供连贯且有深度的回答。
- 详细描述:LLaVA模型能够生成详细的图像描述,涵盖了图像中的各个方面,而不仅仅是简单描述图像内容。
- 复杂推理:LLaVA模型能够进行复杂推理,回答需要多步骤逻辑分析的问题,显示出更强的理解能力和推理能力。
相比之下,BLIP-2和OpenFlamingo模型虽然也能描述图像,但在对话和复杂推理方面的表现不如LLaVA模型。
LLaVA-Med(生物医学图像问答)
paper:LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
arXiv:https://arxiv.org/abs/2306.00890
背景概述
- 研究问题:这篇文章要解决的问题是如何训练一个能够回答生物医学图像开放性问题的大型语言和视觉助手(LLaVA-Med)。当前的对话生成AI主要集中在单模态文本上,而多模态对话AI虽然在公共网络上利用了数十亿张图像-文本对取得了快速进展,但这些通用领域的视觉-语言模型在理解和对话生物医学图像方面仍然缺乏复杂性。
- 研究难点:该问题的研究难点包括:生物医学图像-文本对与通用网络内容存在显著差异,通用领域的视觉助手在处理生物医学问题时可能会表现得像一个外行或产生错误的响应;现有的生物医学视觉问答(VQA)方法大多将问题表述为分类任务,不适合开放式的指令跟随。
- 相关工作:该问题的研究相关工作包括:基于开源指令调优的大型语言模型(LLMs)在一般领域的成功应用,如ChatGPT和GPT-4;已有的生物医学LLM聊天机器人,如ChatDoctor和Med-Alpaca;以及现有的生物医学VQA方法,主要分为判别方法和生成方法。
研究方法
这篇论文提出了LLaVA-Med,用于解决生物医学图像开放性问题。具体来说,
-
数据生成:首先,利用PMC-15M提取的大规模生物医学图像-文本对,通过机器-人工共同策划的流程创建多样化的生物医学多模态指令跟随数据。数据生成过程如下:
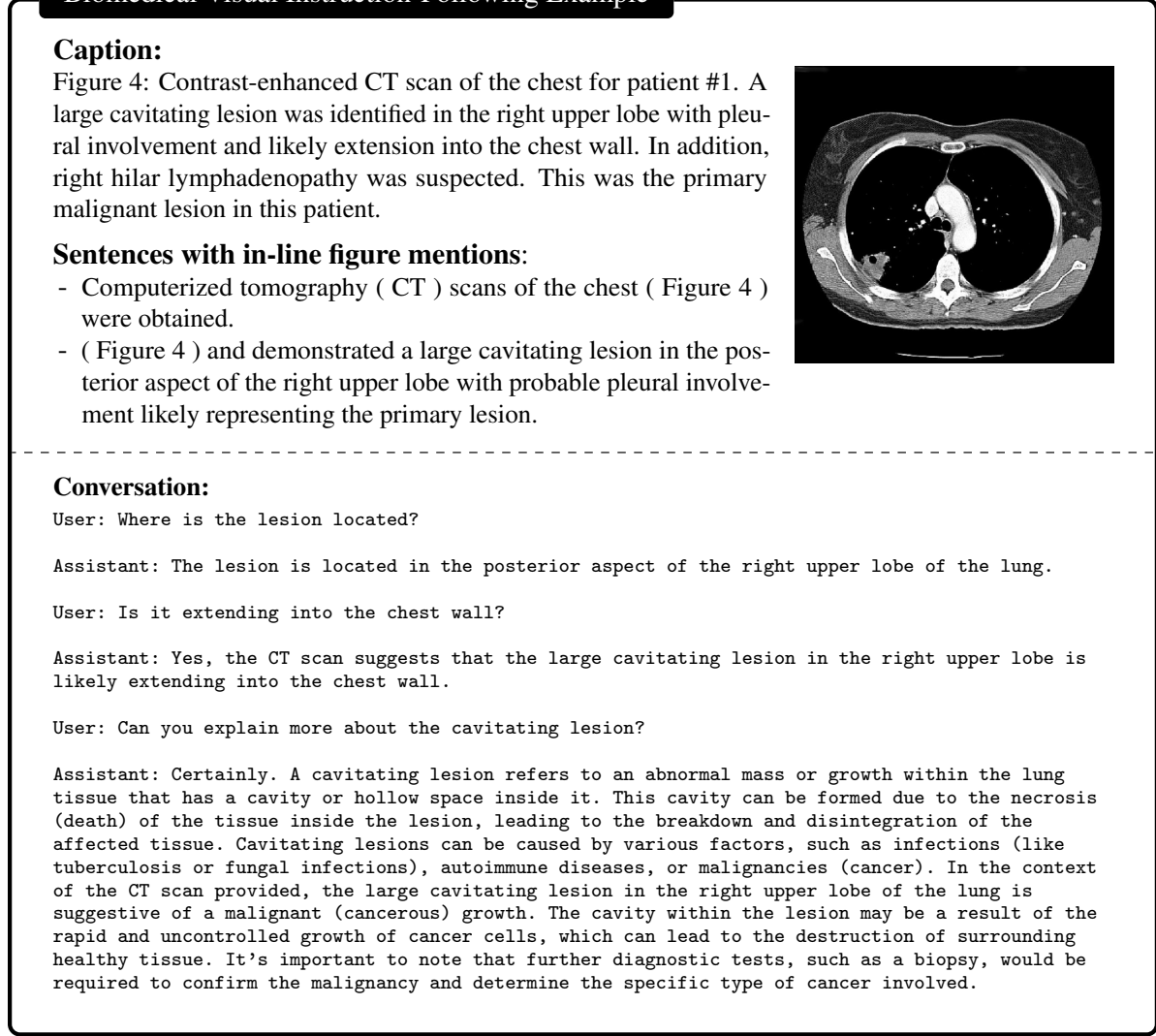
- 从PMC-15M中抽取生物医学图像-文本对。
- 使用GPT-4从文本中生成指令,这些指令成为预期的输出。
- 生成的数据包括概念对齐数据和指令跟随数据,分别用于不同阶段的训练。
-
模型训练:使用LLaVA作为初始的通用领域多模态对话模型,通过两阶段训练过程将其适应到生物医学领域:

- 阶段1:生物医学概念特征对齐:过滤PMC-15M到600K图像-文本对,使用简单的扩展方法将这些对转换为指令跟随数据。模型被要求预测原始标题,同时保持视觉编码器和语言模型的权重冻结,只更新投影矩阵。
- 阶段2:端到端指令调优:仅保持视觉编码器的权重冻结,继续更新投影层和语言模型的预训练权重。通过在收集的生物医学语言-图像指令跟随数据上微调模型,使其能够遵循各种指令并以对话方式完成任务。
-
微调下游数据集:在某些特定的生物医学场景中,需要在微调后开发高度准确和特定于数据集的模型,以提高助手的服务质量。在两个阶段训练后,LLaVA-Med在三个生物医学VQA数据集上进行微调,覆盖不同的数据集大小和多样的生物医学主题。
实验设计
-
数据收集:使用PMC-15M作为主要数据源,从中抽取600K图像-文本对用于概念对齐数据,再通过GPT-4生成60K指令跟随数据。为了提供更多的上下文信息,还从原始PubMed论文中提取提及图像的句子。
-
实验设置:实验分为两个阶段:
- 阶段1:使用600K图像-文本对进行训练,模型被要求预测原始标题,保持视觉编码器和语言模型的权重冻结。
- 阶段2:使用生成的指令跟随数据进行训练,模型被要求遵循各种指令并以对话方式完成任务。
-
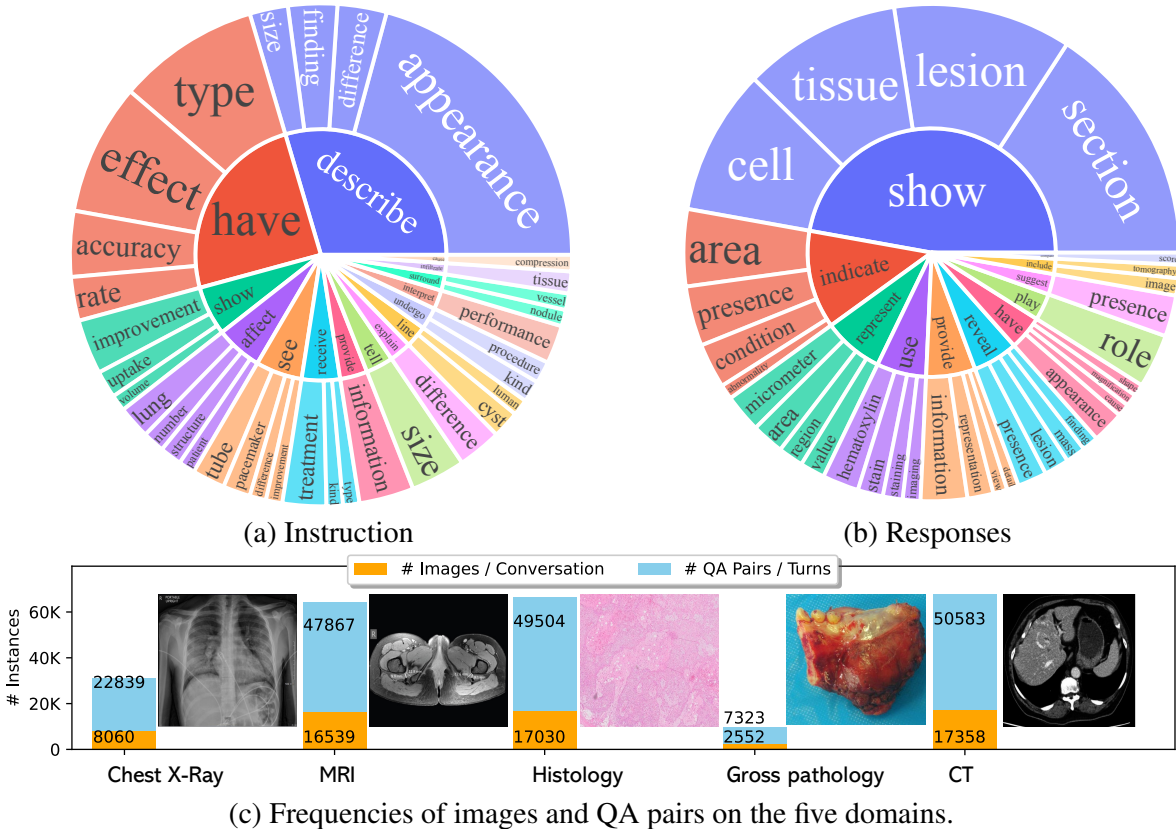
样本选择:从PMC-15M中抽取60K图像-文本对,涵盖五种常见的成像方式:CXR、CT、MRI、组织病理学和大体病理学。
-
参数配置:在阶段1中,使用8个A100 GPU进行训练,每个GPU的批处理大小为128,训练时间为7小时。在阶段2中,继续使用相同的硬件配置,训练时间为8小时。
结果与分析
-
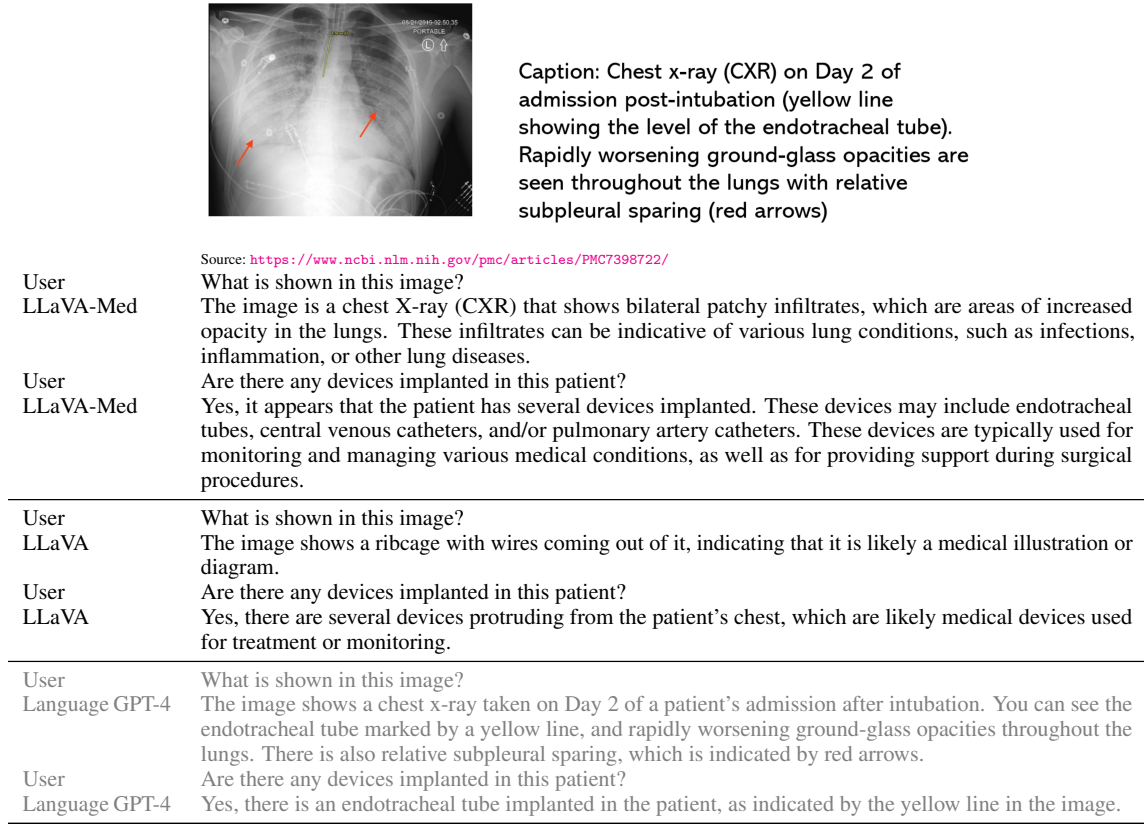
生物医学视觉聊天机器人:在包含193个新颖问题的评估数据集上,LLaVA-Med在对话和详细描述问题上的表现分别达到了49.4%和52.4%。与通用领域的LLaVA相比,LLaVA-Med在遵循多样化指令的能力显著提升。
-
标准基准测试:
- 在VQA-RAD数据集上,LLaVA-Med在开放式问题上的召回率为86.78%,在封闭式问题上的准确率为87.11%。
- 在SLAKE数据集上,LLaVA-Med在开放式问题上的召回率为91.09%,在封闭式问题上的准确率为89.70%。
- 在PathVQA数据集上,LLaVA-Med在开放式问题上的召回率为83.08%,在封闭式问题上的准确率为84.24%。
-
消融研究:
- LLaVA-Med在零样本和微调设置下的表现均优于LLaVA,表明生物医学领域特定的适应策略的有效性。
- 训练阶段1的时间越长,零样本转移性能越好,但单独的阶段1训练不足以使模型具备遵循多样化指令的能力。
- 阶段2中的指令跟随数据至关重要,数据量从10K增加到60K时,性能显著提高。
- 在下游数据集上微调更长时间(至9个epoch)有助于提高性能,尤其是对于在阶段2中训练3个epoch的检查点。
关键问题及回答
问题1:LLaVA-Med的数据生成过程是怎样的?
LLaVA-Med的数据生成过程主要包括两个步骤:
-
生物医学概念对齐数据:从PMC-15M中采样60万张图像-文本对,并从中创建单轮指令跟随示例。具体来说,为一个生物医学图像及其相关的标题生成一个问题,要求描述该图像。问题和图像-文本对组成一个示例,用于训练模型理解生物医学图像的概念。
-
生物医学指令调优数据:为了使模型能够遵循各种指令,使用GPT-4生成多轮对话数据。具体步骤如下:
- 给定一个图像标题,设计提示要求GPT-4生成多轮问题和答案,就好像它能看到图像一样。
- 如果图像标题太短,无法生成有意义的问题和答案,则还包括原始PubMed论文中提到该图像的句子,以提供更多上下文。
- 通过这种方式,生成了60K的指令调优数据,并进一步创建了三个版本的数据:60K-IM(包含内联提及)、60K(不包含内联提及)和10K(最小数据集)。
这些数据通过机器-人工共同策划程序生成,确保了数据的多样性和代表性。
问题2:LLaVA-Med的两阶段训练方法具体是如何进行的?
LLaVA-Med的两阶段训练方法具体如下:
- 阶段1:生物医学概念特征对齐:
- 过滤PMC-15M到60万张图像-文本对。
- 使用简单的扩展方法将这些对转换为指令跟随数据,任务是将图像描述为一句话。
- 在训练过程中,保持视觉编码器和语言模型的权重冻结,只更新投影矩阵。这样,模型可以学习将新的生物医学视觉概念与其文本词嵌入对齐。
- 阶段2:端到端指令调优:
- 仅保持视觉编码器的权重冻结,继续更新投影层和语言模型的预训练权重。
- 在收集的生物医学语言-图像指令跟随数据上微调模型,使其能够遵循各种指令并以对话方式完成任务。
- 通过这种方式,模型不仅能够作为生物医学视觉助手与用户交互,还能在标准的生物医学VQA数据集上实现良好的零样本任务转移性能。
这两个阶段的训练使得LLaVA-Med能够在生物医学领域实现高效的指令跟随和视觉问答任务。
问题3:LLaVA-Med在标准生物医学VQA数据集上的表现如何?
LLaVA-Med在三个标准生物医学VQA数据集上的表现优于现有的监督最先进方法:
-
VQA-RAD:在VQA-RAD数据集上,LLaVA-Med在开放式问题上的召回率达到84.19%,在封闭式问题上的准确率达到83.08%。这些结果表明,LLaVA-Med在提供明确指令的情况下,能够有效地完成生物医学任务。
-
SLAKE:在SLAKE数据集上,LLaVA-Med在开放式问题上的召回率达到91.21%。这一结果显示了LLaVA-Med在处理需要外部医学知识的开放式问题时的强大能力。
-
PathVQA:在PathVQA数据集上,LLaVA-Med在开放式问题上的表现也较为出色,尽管与SLAKE相比略有逊色,但在某些指标上仍达到了较高的水平。
总体而言,LLaVA-Med在多个生物医学VQA数据集上表现出色,特别是在处理开放式问题和对齐生物医学概念方面表现突出。
LLaVA-1.5(通过视觉指令微调改进基线性能)
paper:Improved Baselines with Visual Instruction Tuning
arXiv:https://arxiv.org/abs/2310.03744
背景概述
- 研究问题:本文研究了在大规模多模态模型(LMM)中,如何在受控设置下设计选择以通过视觉指令调优实现更好的性能。具体来说,研究了如何通过简单的修改来提高LLaVA框架下的基线性能。
- 研究难点:该问题的研究难点包括:如何选择合适的数据和模型架构以提高多模态理解能力;如何在有限的训练数据下实现高效的训练;以及如何扩展模型以处理更高分辨率的输入。
- 相关工作:相关研究包括LLaVA和MiniGPT-4在自然指令跟随和视觉推理能力方面的出色表现。其他工作还通过扩大预训练数据、指令跟随数据、视觉编码器和语言模型来提高性能。
研究方法
这篇论文提出了通过改进LLaVA框架的设计选择来解决大规模多模态模型的训练问题。具体来说,
-
全连接视觉-语言连接器:研究发现LLaVA中的全连接视觉-语言连接器非常强大且数据高效。通过使用CLIP-ViT-L-336px和MLP投影,显著提高了多模态理解能力。
-
响应格式提示:为了更好地处理短答案,提出了一种单一的响应格式提示,明确指出输出格式。例如,在VQA问题上添加“Answer the question using a single word or phrase.”
-
数据扩展:通过添加学术任务相关的VQA、OCR和区域级感知数据集,增强了模型在各种任务中的能力。
-
高分辨率输入:通过将图像分割成网格并独立编码,实现了模型在高分辨率下的扩展。具体来说,使用CLIP-ViT-L-336px作为视觉编码器,并将图像分辨率提高到336*336。

实验设计
- 数据收集:最终训练数据混合包含了多种数据集,包括VQA、OCR、区域级VQA、视觉对话和语言对话数据。具体数据集包括COCO、Visual Genome、RefCOCO等。

- 实验设置:使用最新的Vicuna v1.5作为基础语言模型,保持与原始LLaVA相同的训练迭代次数和批量大小。由于图像输入分辨率提高到336*336,训练时间约为LLaVA的两倍。
- 参数配置:预训练阶段的学习率为1e-3,微调阶段的学习率为2e-5,使用AdamW优化器。

结果与分析
-
基准测试:在12个基准测试中,LLaVA-1.5取得了最佳的整体性能,尽管其预训练和微调数据量比其他方法少得多。特别是在指令跟随多模态模型的任务中,LLaVA-1.5显著优于LLaVA。
-
高分辨率扩展:将图像分辨率提高到448*448后,LLaVA-1.5-HD在所有基准测试中的整体性能进一步提高,特别是在需要图像细节感知能力的任务中(如MM Vet中的OCR)。
-
数据效率:随机下采样训练数据混合高达75%并不会显著降低模型性能,表明可以进一步改进数据压缩策略以提高LLaVA的训练效率。
-
模型组合能力:LLaVA-1.5在独立训练的任务上表现出组合能力,无需显式联合训练即可推广到需要组合这些能力的任务。

关键问题及回答
问题1:LLaVA-1.5在处理短答案方面有哪些具体的改进?
LLaVA-1.5通过引入单一的响应格式提示来改进处理短答案的能力。具体来说,LLaVA-1.5在VQA问题上添加了“Answer the question using a single word or phrase.”这样的提示,明确指示模型输出短答案。这种提示方式有效地引导模型在生成答案时选择简短的形式,避免了模型在自然视觉对话中过度倾向于长答案的问题。实验结果表明,仅仅通过这种简单的提示,LLaVA-1.5在MME数据集上的性能从809.6提高到1323.8,显著优于InstructBLIP。
问题2:LLaVA-1.5如何实现高分辨率输入的扩展,这种方法有哪些优势?
LLaVA-1.5通过将图像分割成网格并独立编码来实现高分辨率输入的扩展。具体来说,使用CLIP-ViT-L-336px作为视觉编码器,并将图像分辨率提高到3362。为了保持数据的效率,LLaVA-1.5将图像分割成多个小网格,每个网格单独编码,然后将编码后的特征图合并成一个大的特征图。此外,为了提供全局上下文,还将下采样的图像特征与合并后的特征图进行拼接。这种方法的优势在于:1)模型可以在不进行位置嵌入插值的情况下扩展到任意分辨率;2)通过拼接下采样图像的特征,模型能够保持对全局信息的感知,减少分割-合并操作带来的伪影。实验结果显示,LLaVA-1.5-HD在所有基准测试中的整体性能进一步提高,特别是在需要图像细节感知能力的任务中(如MM Vet中的OCR)。
问题3:LLaVA-1.5在数据效率方面有哪些发现,这些发现对未来研究有何启示?
LLaVA-1.5发现随机下采样训练数据混合高达75%并不会显著降低模型性能,这表明可以通过进一步改进数据压缩策略来提高LLaVA的训练效率。具体来说,尽管LLaVA-1.5的训练时间约为LLaVA的两倍(由于图像分辨率提高到3362),但模型在大多数基准测试中的性能仍然保持在98%以上。这一发现对未来研究的启示包括:1)可以在保证模型性能的前提下,进一步探索数据压缩和高效训练的方法;2)研究是否可以设计更复杂的数据采样策略,以在更少的训练数据下实现更好的模型性能。
LLaVA-Plus(多模态Agent智能系统)
paper:LLaVA-Plus: Learning to Use Tools for Creating Multimodal Agents
arXiv:https://arxiv.org/abs/2311.05437
背景概述
- 研究问题:这篇文章要解决的问题是如何开发一种通用多模态助手(LLaVA-Plus),使其能够通过端到端训练的方式系统地扩展大型多模态模型(LMMs)的能力,从而能够使用各种工具来完成现实世界中的任务。
- 研究难点:该问题的研究难点包括:如何设计一个能够无缝整合多种技能的架构,如何通过视觉指令调优来增强模型的灵活性和人机交互能力,以及如何在训练过程中有效地生成和使用多模态工具指令数据。
- 相关工作:该问题的研究相关工作包括两类方法:一类是通过端到端训练LLM来提升其处理视觉信息的能力;另一类是通过工具链式调用LLM来执行子任务。现有的代表性工作包括Flamingo、MiniGPT-4、VisProg、ViperGPT、Visual ChatGPT和X-GPT等。
研究方法

这篇论文提出了LLaVA-Plus,用于解决多模态助手在计算机视觉和视觉语言任务中的通用性问题。具体来说,
-
模块化系统架构:LLaVA-Plus采用模块化系统架构,允许作为规划器的LMM大规模地学习使用各种技能。该架构包括一个技能库,其中包含广泛的视觉和视觉语言专用模型作为工具。
-
技能库:技能库中的工具涵盖视觉理解、生成、外部知识检索及其组合等多种技能。通过自指令方法生成工具使用的多模态指令数据,利用GPT-4作为标注工具。
-
视觉指令调优:LLaVA-Plus通过视觉指令调优进行训练,使用统一的模型预测格式来表示有无技能调用的对话。
-
训练目标:LLaVA-Plus在训练时使用自回归目标,仅使用绿色子序列(或标记)计算损失,从而学习预测技能使用、答案和何时停止。
实验设计
- 数据收集:通过自指令方法生成多模态工具使用的指令数据,利用GPT-4作为标注工具。数据涵盖视觉理解、生成、外部知识检索及其组合等多种技能。
- 实验设置:LLaVA-Plus分为两种设置:(i)LLaVA-Plus(所有工具),利用除分割外的所有视觉理解工具处理输入图像;(ii)LLaVA-Plus(即时使用工具),仅提供相关工具的执行结果。
- 模型训练:结合生成的工具使用指令数据和LLaVA-158K数据集进行训练。使用FastChat系统进行服务,模型和所有工具可以在80G GPU上加载和服务。
结果与分析

-
现有能力提升:在LLaVA-Bench和SEED-Bench基准测试上,LLaVA-Plus的变体均优于LLaVA,证明了添加新技能视觉识别结果的有效性。
-
新能力展示:LLaVA-Plus展示了多项新能力,包括对象检测和视觉聊天、语义分割和基于掩码的条件图像生成、多模态社交媒体帖子生成等。
-
与现有系统的比较:在MMVet和VisIT-Bench基准测试上,LLaVA-Plus显著优于LLaVA和其他现有系统,特别是在OCR和空间能力方面。

关键问题及回答
问题1:LLaVA-Plus的模块化系统架构是如何设计的?它如何实现大规模学习使用各种技能?
LLaVA-Plus采用模块化系统架构,允许作为规划器的LMM大规模学习使用各种技能。具体来说,LLaVA-Plus包含一个技能库,技能库中汇集了广泛的视觉和视觉语言专用模型。LMM可以根据用户输入的多模态数据(如图像和自然语言指令),分析并选择合适的工具来执行任务。工具执行完成后,其结果会返回给LMM,LMM再将这些结果与用户输入聚合,生成最终的回应。这种模块化设计使得LMM能够灵活地扩展其能力,并通过视觉指令调优不断学习新技能。
问题2:LLaVA-Plus在视觉指令调优过程中是如何生成工具使用指令数据的?
LLaVA-Plus通过自指令方法生成工具使用指令数据。具体步骤包括:首先,使用GPT-4作为标签器,生成需要使用工具才能回答的用户指令。然后,根据这些指令,随机选择一个问题和重写问题以增加数据多样性。接着,生成工具的“思考”和“值”字段,其中“思考”表示是否需要调用技能库中的工具,“值”是工具的输出结果。最后,将工具的输出结果与初始问题一起重复,形成完整的指令数据。这种方法确保了数据集的多样性和一致性,有助于模型学习到更丰富的技能使用场景。
问题3:LLaVA-Plus在多个基准测试中的表现如何?它展示了哪些新能力?
LLaVA-Plus在多个基准测试中显著优于现有的多模态系统。具体来说,LLaVA-Plus在LLaVA-Bench和SEED-Bench基准上均优于LLaVA,证明了添加新技能的视觉识别结果在LMM管道中的有效性。此外,LLaVA-Plus在MMVet和VisIT-Bench基准上也显著优于现有的多模态系统,特别是在OCR和空间推理方面表现突出。
LLaVA系列表格一览
| 特征 | LLaVA | LLaVA-Med | LLaVA-1.5 | LLaVA-Plus |
|---|---|---|---|---|
| 目标 | 多模态视觉理解与推理 | 生物医学领域多模态对话 | 提升LLaVA性能,实现更广泛的能力 | 扩展LLaVA功能,使其能够使用工具 |
| 数据 | 利用ChatGPT生成视觉指令数据 | 利用PubMed Central数据生成指令数据 | 利用公开数据集和响应格式化提示 | 利用公开数据集和多种工具使用示例 |
| 模型架构 | 视觉特征到语言模型的线性投影 | 与LLaVA相同,但预训练和微调策略不同 | 使用MLP投影和学术任务导向数据 | 与LLaVA相同,但包含技能库 |
| 训练方法 | 两阶段训练:特征对齐和指令微调 | 课程学习:先对齐生物医学词汇,再学习开放式对话语义 | 提升响应格式化提示和模型规模 | 利用视觉指令数据进行训练 |
| 能力 | 视觉对话、复杂推理 | 生物医学图像理解与对话 | 多模态理解、多任务平衡、高分辨率支持 | 视觉理解、生成、外部知识检索、技能组合 |
| 优势 | 简单高效、数据高效 | 成本低、可扩展 | 性能优异、数据高效 | 功能强大、可扩展 |
| 局限 | 生成对抗样本、幻觉 | 幻觉、深度推理不足 | 训练时间长、多图像理解有限 | 幻觉、工具使用冲突 |
| 应用场景 | 多模态对话、视觉推理 | 生物医学领域辅助 | 多模态任务、学术任务 | 多模态任务、工具辅助 |
| 开源 | 是 | 是 | 是 | 是 |
推荐阅读
《三年面试五年模拟》版本更新白皮书,迎接AIGC时代
AIGC |「多模态模型」系列之OneChart:端到端图表理解信息提取模型
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之LLM主干(1):ChatGLM系列
AI多模态模型架构之LLM主干(2):Qwen系列
AI多模态模型架构之LLM主干(3):Llama系列
AI多模态教程:从0到1搭建VisualGLM图文大模型案例
AI多模态教程:Mini-InternVL1.5多模态大模型实践指南
AI多模态教程:Qwen-VL多模态大模型实践指南
AI多模态实战教程:面壁智能MiniCPM-V多模态大模型问答交互、llama.cpp模型量化和推理
智谱推出创新AI模型GLM-4-9B:国家队开源生态的新里程碑
这篇关于多模态基础模型:LLAVA系列大解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






