本文主要是介绍十一、多模态大语言模型(LLaVA),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 LLaVA多模态大语言模型的训练过程
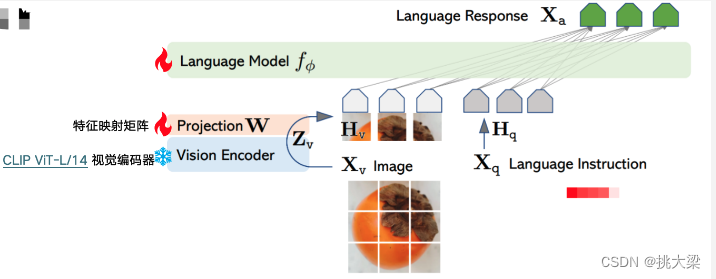
两个阶段
- 特征对齐的预训练。只更新特征映射矩阵
- 端到端微调。特征投影矩阵和LLM都进行更新
2 LLaVA1.5多模态大语言模型的训练
LLaVA官网
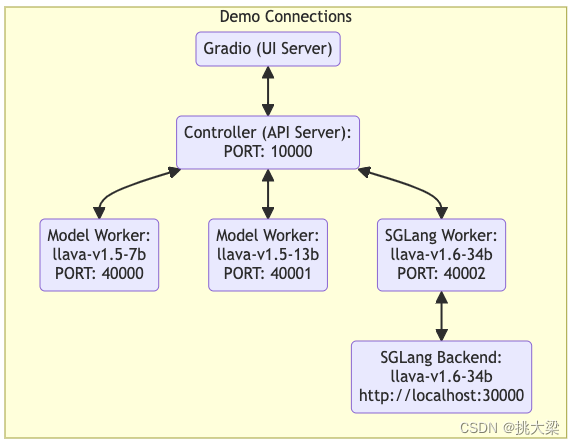
python -m llava.serve.controller --host 0.0.0.0 --port 10000
python -m llava.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
3 LLaVA1.6改进
Vsion Encoder改进
- 输入图像分辨率像素增加,使能够抓住更多细节。支持:672x672 336x1344 1344 x 336
- 改进视觉指令调整数据混合,实现更好的视觉推理和OCR能力
- 在更多的场景下进行更好的视觉对话,涵盖不同的应用
- 更好的世界知识和逻辑推理能力,通过SGLang实现高效部署和推理
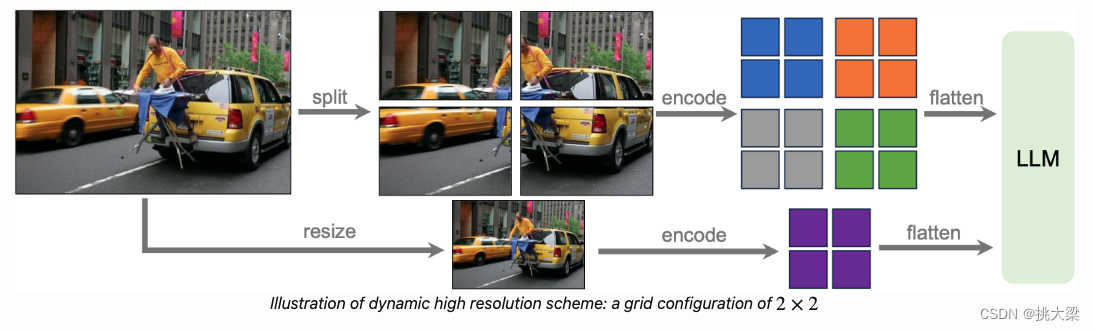
Projection机制改进
InternLM-XComposer2
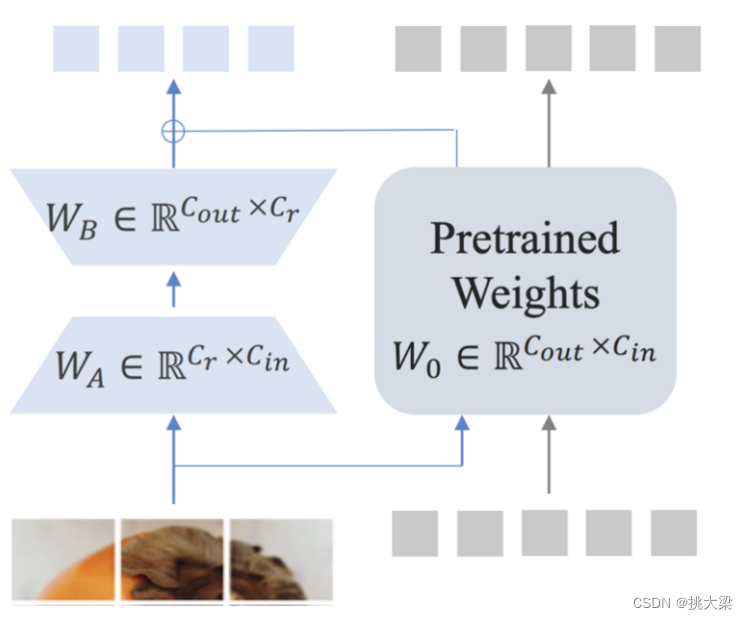
4 LLaVA-Plus
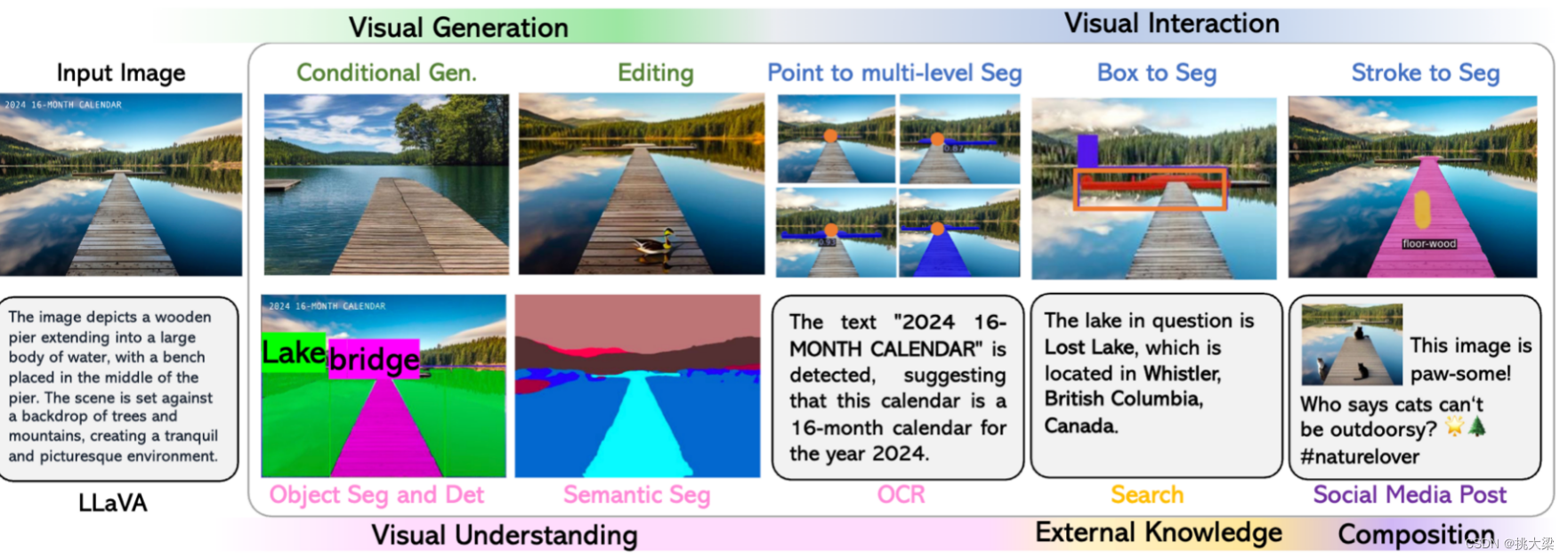
5 总结
- 多模态学习的核心在于特征对齐
- 多模态大语言模型的本质在于All-to-one(LLM)的特征对齐范式
- 多模态大语言模型在处于飞速发展阶段
这篇关于十一、多模态大语言模型(LLaVA)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







