本文主要是介绍【LLM多模态】Cogview3、DALL-E3、CogVLM、LLava模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
note
文章目录
- note
- VisualGLM-6B模型
- 图生文:CogVLM-17B模型
- 0. 直接部署推理模型
- Situation 2.1 CLI (SAT version)
- Situation 2.2 CLI (Huggingface version)
- Situation 2.3 Web Demo
- 1. 模型架构
- 2. 模型效果
- 3. 训练数据:CogVLM-SFT-311K
- 数据集信息
- 数据集数量
- 数据集格式
- 4. 代码实践
- 5. 处理的任务
- 6. 注意事项
- 文生图:CogView3模型
- DALL-E3模型
- LLava模型
- minigpt-4模型
- CogVideo模型
- 网易伏羲-丹青模型
- Intern系列模型
- InternVL-6B模型
- InternLM-XComposer2模型
- 浦医2.0(OpenMEDLab2.0)模型
- 书生·筑梦(Vchitect)模型
- AnimateDiff模型
- MiniGPT-4模型
- 其他多模态模型
- Reference
VisualGLM-6B模型
VisualGLM 是一个依赖于具体语言模型的多模态模型,而CogVLM则是一个更广阔的系列,不仅有基于GLM的双语模型,也有基于Llama2系列的英文模型。这次开源的 17B 模型就是基于Vicuna-7B 的英文模型。
图生文:CogVLM-17B模型
多模态模型CogVLM-17B(开源):
Github:https://github.com/THUDM/CogVLM
Huggingface:https://huggingface.co/THUDM/CogVLM
魔搭社区:https://www.modelscope.cn/models/ZhipuAI/CogVLM
Paper:https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf
开源的对应模型:
| 模型名称 | 输入分辨率 | 介绍 | Huggingface model | SAT model |
|---|---|---|---|---|
| cogvlm-chat-v1.1 | 490 | 支持同时进行多轮聊天和视觉问答,支持自由的提示词。 | link | link |
| cogvlm-base-224 | 224 | 文本-图像预训练后的原始检查点。 | link | link |
| cogvlm-base-490 | 490 | 通过从 cogvlm-base-224 进行位置编码插值,将分辨率提升到490。 | link | link |
| cogvlm-grounding-generalist | 490 | 此检查点支持不同的视觉定位任务,例如REC,定位字幕等。 | link | link |
0. 直接部署推理模型
# CUDA >= 11.8
pip install -r requirements.txt
python -m spacy download en_core_web_sm
所有的推理代码都位于 basic_demo/ 目录下。请在进行进一步操作之前,先切换到这个目录。
Situation 2.1 CLI (SAT version)
注:这里的SAT是指使用了SwissArmyTransformer库。
通过以下方式运行CLI演示:
# CogAgent
python cli_demo_sat.py --from_pretrained cogagent-chat --version chat --bf16 --stream_chat
python cli_demo_sat.py --from_pretrained cogagent-vqa --version chat_old --bf16 --stream_chat# CogVLM
python cli_demo_sat.py --from_pretrained cogvlm-chat --version chat_old --bf16 --stream_chat
python cli_demo_sat.py --from_pretrained cogvlm-grounding-generalist --version base --bf16 --stream_chat
该程序将自动下载卫星模型并在命令行中进行交互。您可以通过输入指令并按回车来生成回复。输入clear 以清除对话历史,输入stop 以停止程序。
我们也支持模型并行推理,该推理将模型分割到多个(2/4/8)GPU上。使用 --nproc-per-node=[n] 控制使用的GPU数量。
torchrun --standalone --nnodes=1 --nproc-per-node=2 cli_demo_sat.py --from_pretrained cogagent-chat --version chat --bf16
-
如果你想手动下载权重,你可以用模型路径替换
--from_pretrained后的路径。 -
我们的模型支持SAT的4位量化和8位量化。你可以将
--bf16更改为--fp16, 或--fp16 --quant 4, 或--fp16 --quant 8.例如
python cli_demo_sat.py --from_pretrained cogagent-chat --fp16 --quant 8 --stream_chat python cli_demo_sat.py --from_pretrained cogvlm-chat-v1.1 --fp16 --quant 4 --stream_chat # In SAT version,--quant should be used with --fp16 -
该程序提供以下超参数来控制生成过程:
usage: cli_demo_sat.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE]optional arguments: -h, --help show this help message and exit --max_length MAX_LENGTHmax length of the total sequence --top_p TOP_P top p for nucleus sampling --top_k TOP_K top k for top k sampling --temperature TEMPERATUREtemperature for sampling -
点击 这里 查看不同模型与
--version参数之间的对应关系的对应关系。
Situation 2.2 CLI (Huggingface version)
通过以下方式运行CLI演示:
# CogAgent
python cli_demo_hf.py --from_pretrained THUDM/cogagent-chat-hf --bf16
python cli_demo_hf.py --from_pretrained THUDM/cogagent-vqa-hf --bf16# CogVLM
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-chat-hf --bf16
python cli_demo_hf.py --from_pretrained THUDM/cogvlm-grounding-generalist --bf16
-
如果你想手动下载权重,你可以将
--from_pretrained后的路径替换为模型路径。 -
你可以将
--bf16更改为--fp16, 或者--quant 4。例如,我们的模型支持Huggingface的4-bit quantization:python cli_demo_hf.py --from_pretrained THUDM/cogvlm-chat-hf --quant 4
Situation 2.3 Web Demo
我们还提供了一个基于Gradio的本地网络演示。首先,通过运行 pip install gradio 来安装Gradio。然后下载并进入这个仓库,运行 web_demo.py。
python web_demo.py --from_pretrained cogagent-chat --version chat --bf16
python web_demo.py --from_pretrained cogagent-vqa --version chat_old --bf16
python web_demo.py --from_pretrained cogvlm-chat-v1.1 --version chat_old --bf16
python web_demo.py --from_pretrained cogvlm-grounding-generalist --version base --bf16
1. 模型架构
思想:视觉优先
之前的多模态模型:通常都是将图像特征直接对齐到文本特征的输入空间去,并且图像特征的编码器通常规模较小,这种情况下图像可以看成是文本的“附庸”,效果自然有限。
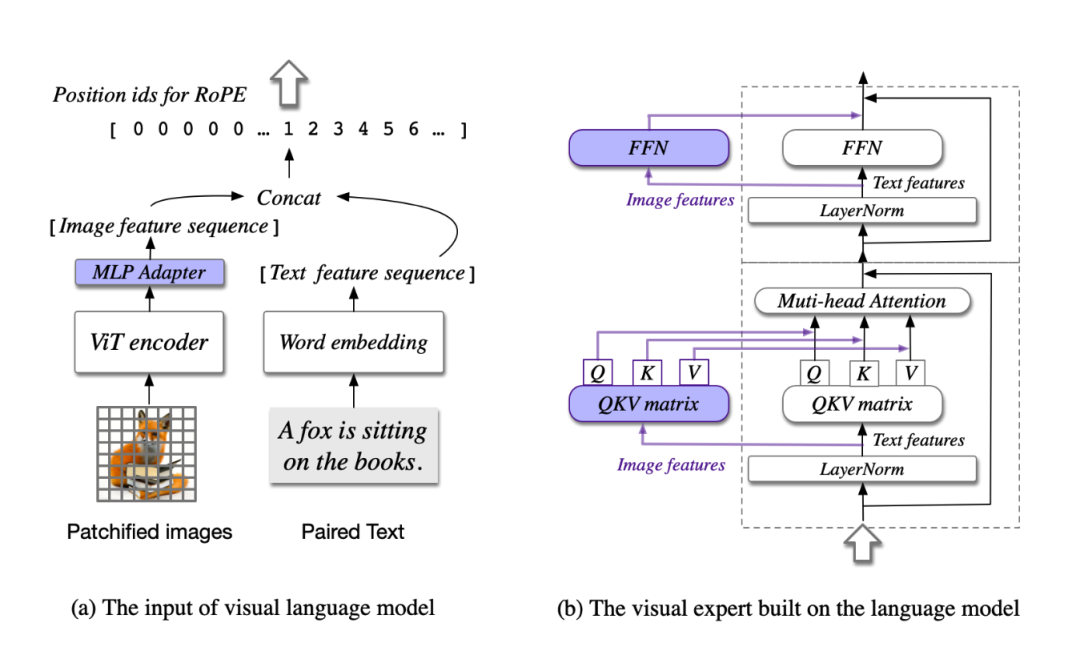
模型共包含四个基本组件:ViT 编码器,MLP 适配器,预训练大语言模型(GPT-style)和视觉专家模块。
- ViT编码器:在 CogVLM-17B 中,采用预训练的 EVA2-CLIP-E。也就是上图将图片进入vit encoder编码
- MLP 适配器:MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特征相同的空间。
- 预训练大语言模型:CogVLM 的模型设计与任何现有的 GPT-style的预训练大语言模型兼容。具体来说,CogVLM-17B 采用 Vicuna-7B-v1.5 进行进一步训练;也选择了 GLM 系列模型和 Llama 系列模型做了相应的训练。
- 视觉专家模块:在每层添加一个视觉专家模块,以实现深度的视觉 - 语言特征对齐。具体来说,每层视觉专家模块由一个 QKV 矩阵和一个 MLP 组成。
训练方式:
- 模型在15亿张图文对上预训练了4096个A100*days,并在构造的视觉定位(visual grounding)数据集上进行二阶段预训练。
- 在对齐阶段,CogVLM使用了各类公开的问答对和私有数据集进行监督微调,使得模型能回答各种不同类型的提问。
class CogVLMModel(LLaMAModel):def __init__(self, args, transformer=None, parallel_output=True, **kwargs):super().__init__(args, transformer=transformer, parallel_output=parallel_output, **kwargs)self.image_length = args.image_lengthself.add_mixin("eva", ImageMixin(args))self.del_mixin("mlp")self.add_mixin("mlp", LlamaVisionExpertFCMixin(args.hidden_size, args.inner_hidden_size, args.num_layers, 32))self.del_mixin("rotary")self.add_mixin("rotary", LlamaVisionExpertAttnMixin(args.hidden_size, args.num_attention_heads, args.num_layers, 32))@classmethoddef add_model_specific_args(cls, parser):group = parser.add_argument_group('CogVLM', 'CogVLM Configurations')group.add_argument('--image_length', type=int, default=256)group.add_argument('--eva_args', type=json.loads, default={})return super().add_model_specific_args(parser)def forward(self, input_ids, vision_expert_mask, image_embed_mask, **kwargs):if input_ids.shape[1] > 1:return super().forward(input_ids=input_ids, vision_expert_mask=vision_expert_mask, image_embed_mask=image_embed_mask, **kwargs)return super().forward(input_ids=input_ids, **kwargs)class FineTuneTrainCogVLMModel(CogVLMModel):def __init__(self, args, transformer=None, parallel_output=True, **kw_args):super().__init__(args, transformer=transformer, parallel_output=parallel_output, **kw_args)self.args = args# If you want to use model parallel with a mp_size=1 checkpoint, and meanwhile you also want to use lora,# you have to add_mixin after loading model checkpoint.@classmethoddef add_model_specific_args(cls, parser):group = parser.add_argument_group('CogVLM-finetune', 'CogVLM finetune Configurations')group.add_argument('--pre_seq_len', type=int, default=8)group.add_argument('--lora_rank', type=int, default=10)group.add_argument('--use_ptuning', action="store_true")group.add_argument('--use_lora', action="store_true")group.add_argument('--use_qlora', action="store_true")group.add_argument('--layer_range', nargs='+', type=int, default=None)return super().add_model_specific_args(parser)
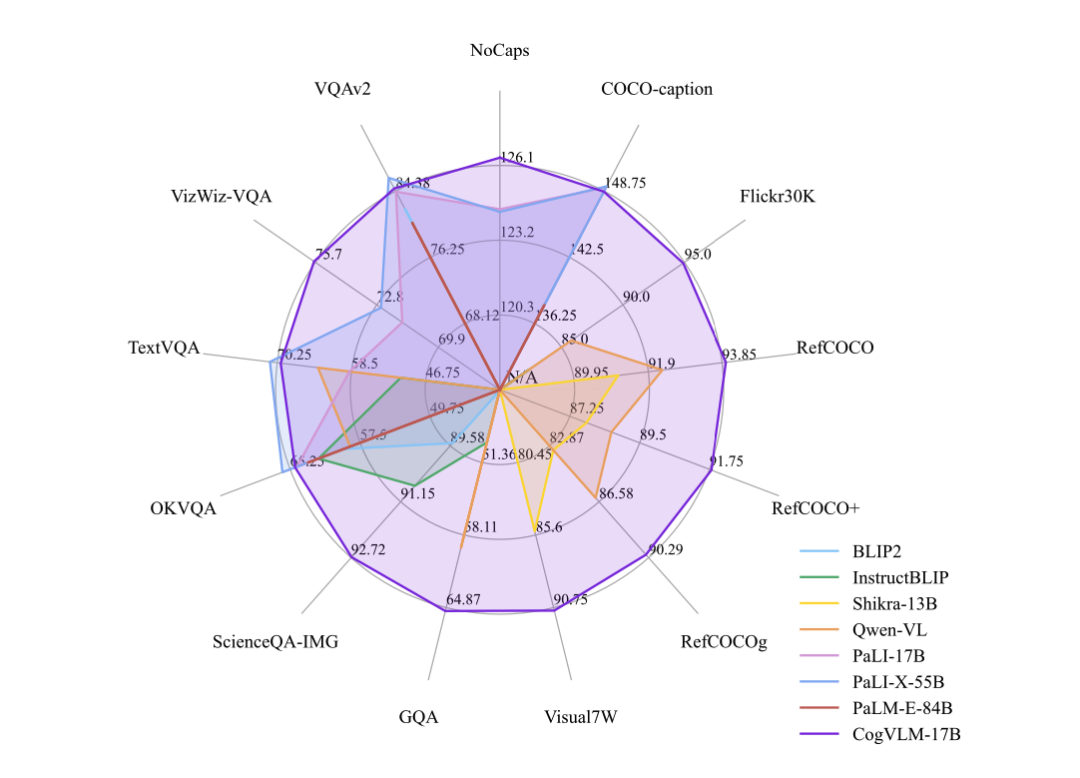
2. 模型效果
CogVLM 可以在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合。训练的 CogVLM-17B 是目前多模态权威学术榜单上综合成绩第一的模型,在14个数据集上取得了state-of-the-art或者第二名的成绩。这些基准大致分为三类(共 14 个),包括图像字幕(Image Captioning)、视觉问答(Visual QA)、视觉定位(Visual Grounding)。
3. 训练数据:CogVLM-SFT-311K
CogVLM-SFT-311K:CogVLM SFT 中的双语视觉指令数据集
链接: CogVLM-SFT-311K
CogVLM-SFT-311K 是在训练 CogVLM v1.0 最初版本时使用的主要对齐语料库。此数据集的构建过程如下:
- 从开源的 MiniGPT-4 中选取了大约3500个高质量数据样本,称为 minigpt4-3500。
- 将 minigpt4-3500 与 Llava-Instruct-150K 整合,并通过语言模型翻译获得中文部分。
- 发现在 minigpt4-3500 和 Llava-instruct 的详细描述部分存在许多噪声。因此,我们纠正了这两部分的中文语料,并将纠正后的语料重新翻译成英语。
数据集信息
数据集共有三个文件夹,分别对应混合 minigpt4-3500 与llava混合的一部分数据集,llava 单论对话和多轮对话数据集。其布局如下:
.CogVLM-SFT-311K
├── llava_details-minigpt4_3500_formate
├── llava_instruction_multi_conversations_formate
└── llava_instruction_single_conversation_formate
在开源的数据中,数据集按照以下格式分布
.llava_details-minigpt4_3500_formate
├── images
│ └── 00000001.jpg
└── labels└── 00000001.json
其中,images存储图像数据,而labels存储这张图像对应的描述或对话。
数据集数量
- llava_details-minigpt4_3500_formate 22464 张图片和描述
- llava_instruction_muti_conversations_formate 56673 张图片和多轮连续对话
- llava_instruction_single_conversation_formate 76634 张图片和单轮对话
数据集格式
图像描述 Caption 格式:
{"captions": [{"role": "caption","content": "这张照片展示了一男一女,他们都穿着红嘿色衣服,坐在桌子旁,在参加活动时面带微笑。这对情侣正在一起摆姿势,背景中还有其他人。在整个场景中可以看到另外几个人,一些人坐在附近的桌子旁,另一些人坐得离这对夫妇更近。各种餐桌设置,如酒杯和杯子,被放置在桌子上。排在最前面的男子打着领带。"}]
}
图像对话 Json 格式:
{"conversations": [{"role": "user","content": "在尝试保持这个浴室有序时可能会遇到哪些挑战?",},{"role": "assistant","content": "在尝试保持这空间和各种物品的存在,例如杯子和手机占用了可用的空间。在图像中,浴室柜台上只有一个水槽可用,这导致多个用户可能必须共享空间放置自己的物品。这可能导致杂乱和混乱外的储物解决方案,如架子、橱柜或墙壁挂架,以保持浴室有序并最小化柜台上的杂乱。"},]
}
4. 代码实践
(1)环境准备和数据处理
# 启动docker环境
docker run -i -t --gpus "device=all" --shm-size="10gb" -v /zhipu-data/official_pretrains/sat_home/:/.sat_models -v ./checkpoints/:/checkpoints/ -v ./examples/:/test/ cogvlm_cuda:v2.0 "/usr/bin/bash"
示例数据:
project dir
... ...
---- scripts
---- examples
-- example_inputs.jsonl
-- 1.png
-- 2.jpeg
-- 3.jpg
-- 4.jpg
-- 5.jpg
-- 6.jpg
example_inputs.jsonl
image键值为项目路径:
{"id":1, "prompt": "Describe this image", "text": "answer", "image": "examples/1.png"}
{"id":2, "prompt": "what did Musk talk about?", "text": "answer", "image": "examples/2.jpeg"}
处理数据的脚本split_dataset.py文件:
import os
import shutildef find_all_files(path, suffix=".jpg"):target_files = []for cur_dir, _, files in os.walk(path, followlinks=True):for f in files:if f.endswith(suffix):target_files.append(os.path.join(cur_dir, f))print(f'find {len(target_files)} files...')return target_filesall_files = find_all_files('archive')
os.makedirs("archive_split", exist_ok=True)
os.makedirs("archive_split/train", exist_ok=True)
os.makedirs("archive_split/valid", exist_ok=True)
os.makedirs("archive_split/test", exist_ok=True)import random
random.seed(2023)
random.shuffle(all_files)
train = all_files[:8000]
valid = all_files[8000:8000+500]
test = all_files[8000+500:8000+500+1500]print("building train")
for file in train:shutil.move(file, os.path.join("archive_split/train", file.split("/")[-1]))
print("building valid")
for file in valid:shutil.move(file, os.path.join("archive_split/valid", file.split("/")[-1]))
print("building test")
for file in test:shutil.move(file, os.path.join("archive_split/test", file.split("/")[-1]))
print("done")
(2)模型训练
bash scripts/finetune_official.sh 8 1 /.sat_models cogvlm-base-490 base 2088 10 /test 40 20 20 "/checkpoints" 8 expert
注意对应的参数:
- NUM_GPUS_PER_WORKER=$1:当前节点训练使用的gpu数量
- MP_SIZE=$2:模型并行数
- SAT_HOME=$3:挂载sat home到docker后的当前路径
- MODEL_TYPE=$4:[cogvlm-base-224, cogvlm-base-490, cogvlm-chat-v1.1, cogvlm-grounding-generalist] 当前实例使用base-490
- VERSION=$5:[base,chat,vqa]chat会提供更详细的回答,vqa只回答一个字
- MAX_LENGTH=$6:最长seq字符长度
- LORA_RANK=$7:lora_rank 越大投入资源越多,设置为-1时不使用lora
- TRAIN_DATA=$8:挂载训练数据路径到docker后的路径
- TRAIN_ITERS=$9:训练步数
- SAVE_INTERVAL=${10}:保存间隔,如果不想保存中间结果可输入一个极大值
- EVAL_INTERVAL=${11}:eval间隔
- SAVE_PATH=${12}:ckpt保存文件夹路径,包括中间模型ckpt和merged_lora模型ckpt
- BATCH_SIZE=${13}:batch size
- TRAINABLE=${14}:可训练参数设置[‘expert’,‘all’]:'expert’只训练visual expert参数,设置’all’且loar_rank=-1时训练全部参数。
(3)模型推理
- cogvlm-chat 用于对齐的模型,在此之后支持像 GPT-4V 一样的聊天。
- cogvlm-base-224 文本-图像预训练后的原始权重。
- cogvlm-base-490 从 cogvlm-base-224 微调得到的 490px 分辨率版本。
- cogvlm-grounding-generalist 这个权重支持不同的视觉定位任务,例如 REC、Grounding Captioning 等。
参数说明:
–from_pretrained:ckpt路径
–version:版本,与训练时版本对应
–english:输入/输出时为英文
–bf16/fp16:与训练时对应
–no_prompt:是否不要prompt
/usr/bin/python3 cli_demo.py --from_pretrained cogvlm-base-224_path --version base --english --bf16 --no_prompt
/usr/bin/python3 cli_demo.py --from_pretrained cogvlm-base-490_path --version base --english --bf16
/usr/bin/python3 cli_demo.py --from_pretrained cogvlm-chat_path --version chat --english --bf16
/usr/bin/python3 cli_demo.py --from_pretrained cogvlm-grounding-generalist_path --version base --english --bf16
5. 处理的任务
这些任务主要是基于图像理解和语言生成的任务:
- 图像字幕任务(Image Captioning):根据给定的图片生成描述图片内容的自然语言句子。数据集包括COCO、Flickr30K等,这些数据集包含了数十万张图片,每张图片都有人工生成的多个描述。
- 视觉问答任务(Visual Question Answering, VQA):根据给定的图片和关于图片内容的问题,生成回答问题的自然语言文本。数据集包括VQAv2、OKVQA等,这些数据集包含了数百万个图像-问题-答案三元组。
- 视觉定位任务(Visual Grounding):确定文本中提到的目标和图像中的具体位置区域之间的对应关系。数据集包括Visual7W、RefCOCO系列等。例如,模型需要从给定的图像中定位出文本提到的对象。
- 图像字幕任务(Grounded Captioning):生成图像的描述句子,其中每个名词短语的对应对象在图像中用边界框标注。数据集包括Flickr30K Entities。
- 定位描述生成任务(Referring Expression Generation, REG):为图像中的每个边界框生成描述其内容的文本表达。数据集包括VisualGenome。
- 定位描述理解任务(Referring Expression Comprehension, REC):根据文本描述的内容在图像中定位出对应区域。数据集包括RefCOCO系列。
这些任务在图像-语言建模的下游应用中扮演重要角色,需要模型理解深层的视觉语义信息。其中,视觉定位任务比较独特,需要确保文本描述与图像区域之间的对齐匹配。
6. 注意事项
选择适合的模型:由于模型功能的差异,不同的模型版本可能会有不同的文本处理器 --version,这意味着使用的提示格式会有所不同。
| model name | –version |
|---|---|
| cogagent-chat | chat |
| cogagent-vqa | chat_old |
| cogvlm-chat | chat_old |
| cogvlm-chat-v1.1 | chat_old |
| cogvlm-grounding-generalist | base |
| cogvlm-base-224 | base |
| cogvlm-base-490 | base |
文生图:CogView3模型
链接:https://github.com/THUDM/CogView
DALL-E3模型
论文:https://cdn.openai.com/papers/dall-e-3.pdf
LLava模型
论文:https://arxiv.org/pdf/2304.08485.pdf
minigpt-4模型
论文:https://arxiv.org/pdf/2304.10592.pdf
CogVideo模型
论文链接:https://arxiv.org/abs/2205.15868
代码链接:https://github.com/THUDM/CogVideo
模型训练方法:
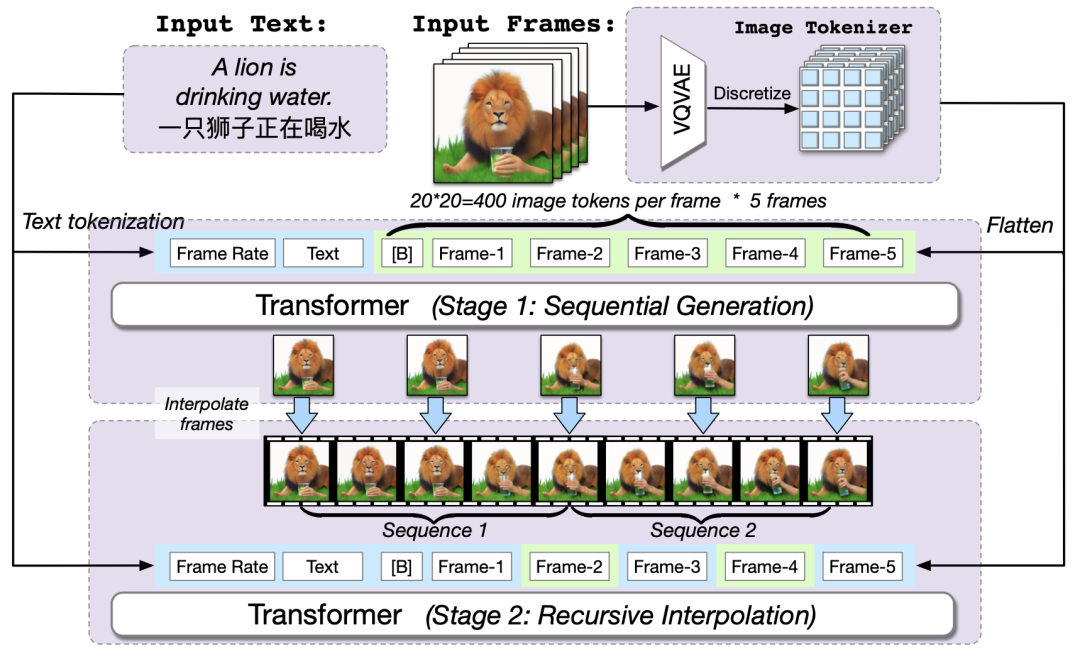
- 首先基于本文作者团队提出的文本合成图像模型CogView2,CogView2是一个包含60亿参数的预训练transformer模型,CogVideo可以看做是CogView2的视频升级版本,CogVideo共有94亿个参数,并在540万个文本视频对上进行了训练。
- CogVideo的训练主要基于本文提出的多帧分层生成框架,具体来说就是先根据CogView2通过输入文本生成几帧图像,然后再根据这些图像进行插帧提高帧率完成整体视频序列的生成。为了更好的在嵌入空间中对齐文本和视频片段,提高模型对文本预训练知识的迁移,作者提出了一种双通道注意力机制来提高性能。
- 此外为了应对模型超大的参数和长视频序列的存储压力,作者将Swin Transformer[4]中的滑动窗口引入到了本文的自回归视频生成任务中
多帧率分层训练方法:
网易伏羲-丹青模型
丹青模型基于原生中文语料数据及网易自有高质量图片数据训练,与其他文生图模型相比,丹青模型的差异化优势在于对中文的理解能力更强,对中华传统美食、成语、俗语、诗句的理解和生成更为准确。比如,丹青模型生成的图片中,鱼香肉丝没有鱼,红烧狮子头没有狮子。基于对中文场景的理解,丹青模型生成的图片更具东方美学,能生成“飞流直下三千尺”的水墨画,也能生成符合东方审美的古典美人。
Intern系列模型
链接:https://github.com/InternLM/InternLM
InternVL-6B模型
以不到1/3的参数量超越视觉模型标杆谷歌ViT-22B,在MMBench等评测上比肩GPT-4V和GeminiPro
InternLM-XComposer2模型
链接:https://github.com/InternLM/InternLM-XComposer
能力全面升级,支持个性化高质量图文创作,图文理解和创作能力领先开源社区
浦医2.0(OpenMEDLab2.0)模型
首个医疗多模态基础模型群,参数规模扩展至200亿,涵盖10余种医疗数据模态,赋能合作医疗机构助力智慧医疗应用场景建设
书生·筑梦(Vchitect)模型
首个支持分钟级视频故事生成的开源文生视频大模型,在多镜头一致性上表现出色.
AnimateDiff模型
通过SparseCtrl支持对视频动效生成更灵活的控制,被用于制作《枕着光的她》中的AI视频,登上2024年yscw舞台
MiniGPT-4模型
三部分组成:预训练的大语言模型 Vicuna[39],预训练的视觉编码器以及一个单一的线性投影层。
其他多模态模型

Reference
[1] https://github.com/THUDM/CogVLM
[2] CogVLM:智谱AI 新一代多模态大模型
[3] CogView:通过Transformer掌握文本到图像的生成
[4] 清华联合BAAI提出第一个开源预训练文本视频生成模型CogVideo
[5] OpenAI最新的文本生成图像大模型DALL·E3
[6] (2023,DALL-E3,两步微调,标题重建)通过更好的标题改进图像生成
[7] AI作画如此简单(7):解读 CogView
[8] cogvlm微调数据:https://huggingface.co/datasets/THUDM/CogVLM-SFT-311K
[9] https://huggingface.co/THUDM/CogView2
[10] Zhu, D., Chen, J., Shen, X., Li, X., & Elhoseiny, M. (2023). MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv preprint arXiv:2304.10592.
[11] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual Instruction Tuning. arXiv:2304.08485.
[12] 大规模语言模型:从理论到实践.张奇、桂韬、郑锐、黄萱菁
[13] SwissArmyTransformer瑞士军刀工具箱使用手册
[14] https://github.com/gscr10/SwissArmyTransformer/tree/main/SwissArmyTransformer
[15] 原创AI:上海AI实验室近期科研成果速览
[16] https://github.com/InternLM/InternLM-XComposer
[17] 多模态大模型进展:https://mm-llms.github.io/posts/getting-started/
[18] 【vlm多模态大模型】minigpt-4详细解析
这篇关于【LLM多模态】Cogview3、DALL-E3、CogVLM、LLava模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









