cogvlm专题
CogVLM 本地部署体验(问题解决)docker容器版
硬件要求(模型推理): INT4 : RTX30901,显存24GB,内存32GB,系统盘200GB INT4 : RTX40901或RTX3090*2,显存24GB,内存32GB,系统盘200GB 模型微调硬件要求更高。一般不建议个人用户环境使用 如果要运行官方web界面streamlit run composite_demo/main.py 显存需要40G以上,至少需两张RTX3090显卡。
CogVLM 本地部署体验(问题解决)
硬件要求(模型推理): INT4 : RTX30901,显存24GB,内存32GB,系统盘200GB INT4 : RTX40901或RTX3090*2,显存24GB,内存32GB,系统盘200GB 模型微调硬件要求更高。一般不建议个人用户环境使用 如果要运行官方web界面streamlit run composite_demo/main.py 显存需要40G以上,至少需两张RTX3090显卡。

【LLM多模态】Cogview3、DALL-E3、CogVLM、LLava模型
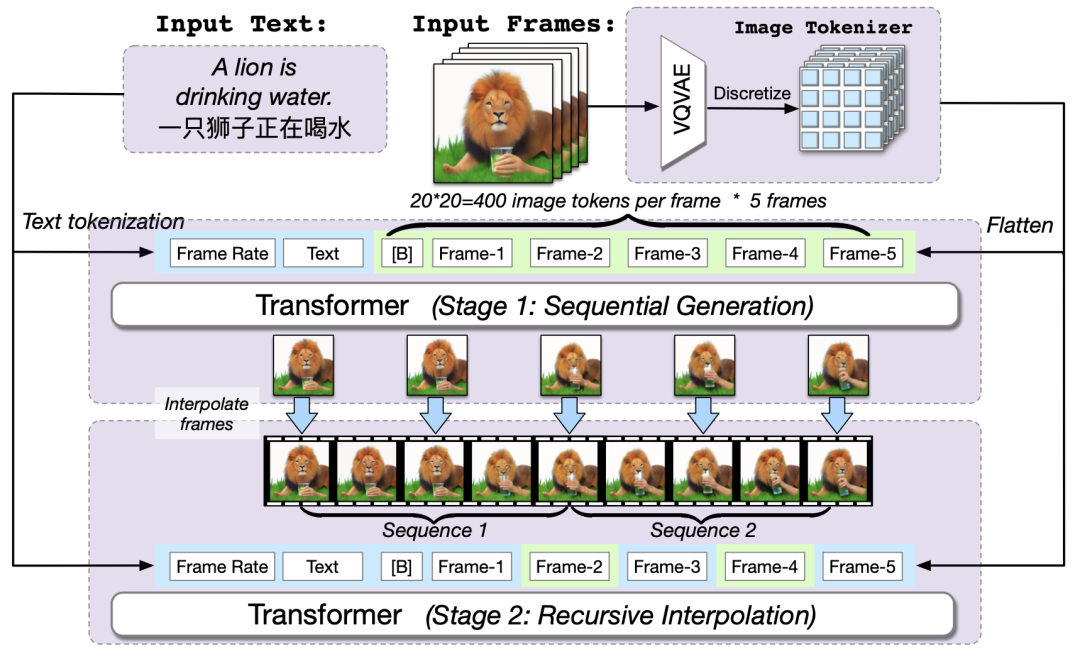
note 文章目录 noteVisualGLM-6B模型图生文:CogVLM-17B模型0. 直接部署推理模型Situation 2.1 CLI (SAT version)Situation 2.2 CLI (Huggingface version)Situation 2.3 Web Demo 1. 模型架构2. 模型效果3. 训练数据:CogVLM-SFT-311K数据集信息数据集数量数
【LLM多模态】Cogview3、DALL-E3、CogVLM、CogVideo模型
note 文章目录 noteVisualGLM-6B模型图生文:CogVLM-17B模型1. 模型架构2. 模型效果 文生图:CogView3模型DALL-E3模型CogVideo模型网易伏羲-丹青模型Reference VisualGLM-6B模型 VisualGLM 是一个依赖于具体语言模型的多模态模型,而CogVLM则是一个更广阔的系列,不仅有基于GLM的双语模型,也有基

VLM 系列——COGVLM—— 论文解读
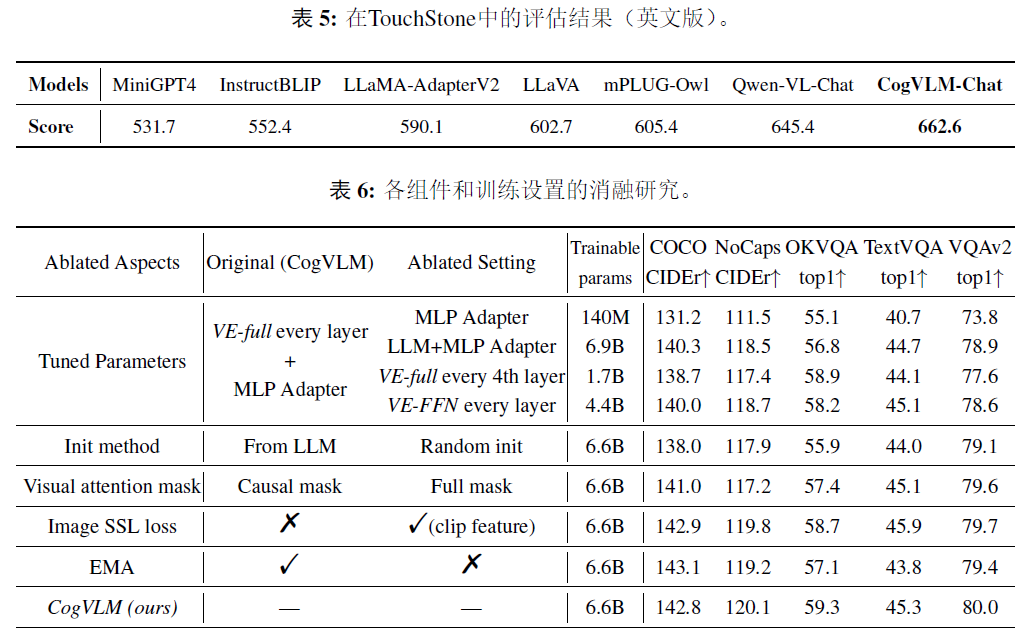
一、概述 1、是什么 COGVLM 全称《VISUAL EXPERT FOR LARGE LANGUAGE》,是一个多模态的视觉-文本模型,当前CogVLM-17B(20231130)可以完成对一幅图片进行描述、图中物体或指定输出检测框、相关事物进行问答,但是这个版本只支持一个图片(为且必为首次输入),只支持英文,几乎不支持写代码(目前测试是的)。 2、亮点 论文认为:在不
cogvlm:visual expert for large lanuage models
CogVLM: Visual Expert For Large Language Models论文笔记 - 知乎github: https://github.com/THUDM/CogVLM简介认为原先的shallow alignment效果不好(如blip-2,llava等),提出了visual expert module用于特征的deep fusion在10项任务上达到SOTA,效果堪比PaL
激发创新,助力研究:CogVLM,强大且开源的视觉语言模型亮相
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。 专栏订阅:项目大全提升自身的硬实力 [专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项