本文主要是介绍【LLM多模态】Cogview3、DALL-E3、CogVLM、CogVideo模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
note
文章目录
- note
- VisualGLM-6B模型
- 图生文:CogVLM-17B模型
- 1. 模型架构
- 2. 模型效果
- 文生图:CogView3模型
- DALL-E3模型
- CogVideo模型
- 网易伏羲-丹青模型
- Reference
VisualGLM-6B模型
VisualGLM 是一个依赖于具体语言模型的多模态模型,而CogVLM则是一个更广阔的系列,不仅有基于GLM的双语模型,也有基于Llama2系列的英文模型。这次开源的 17B 模型就是基于Vicuna-7B 的英文模型。
图生文:CogVLM-17B模型
多模态模型CogVLM-17B(开源):
Github:https://github.com/THUDM/CogVLM
Huggingface:https://huggingface.co/THUDM/CogVLM
魔搭社区:https://www.modelscope.cn/models/ZhipuAI/CogVLM
Paper:https://github.com/THUDM/CogVLM/blob/main/assets/cogvlm-paper.pdf
1. 模型架构
思想:视觉优先
之前的多模态模型:通常都是将图像特征直接对齐到文本特征的输入空间去,并且图像特征的编码器通常规模较小,这种情况下图像可以看成是文本的“附庸”,效果自然有限。
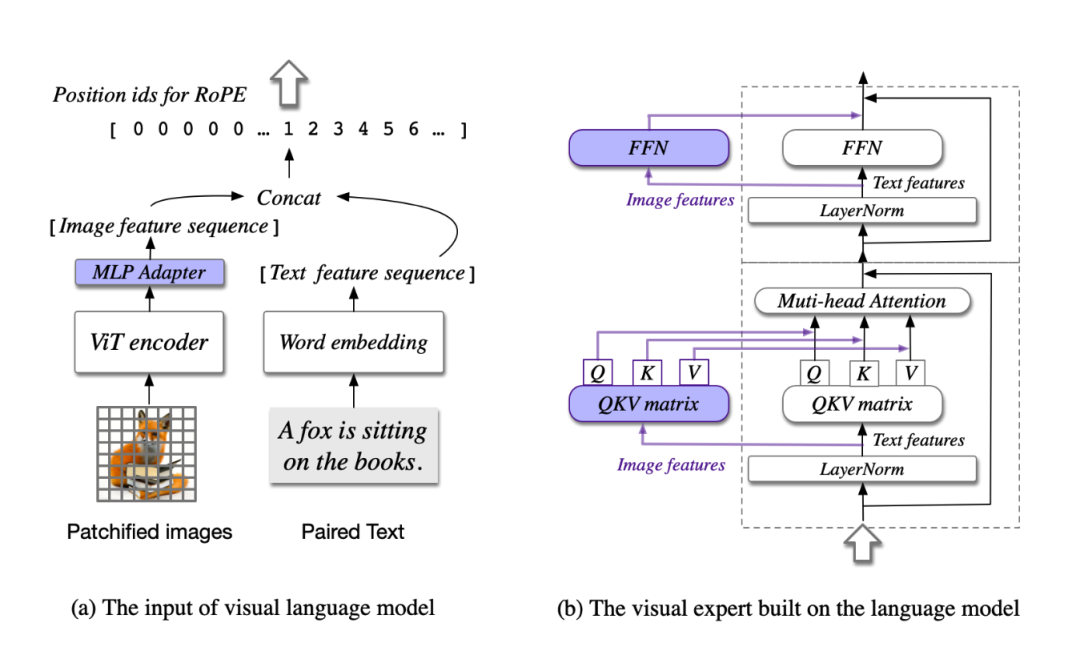
模型共包含四个基本组件:ViT 编码器,MLP 适配器,预训练大语言模型(GPT-style)和视觉专家模块。
- ViT编码器:在 CogVLM-17B 中,采用预训练的 EVA2-CLIP-E。
- MLP 适配器:MLP 适配器是一个两层的 MLP(SwiGLU),用于将 ViT 的输出映射到与词嵌入的文本特征相同的空间。
- 预训练大语言模型:CogVLM 的模型设计与任何现有的 GPT-style的预训练大语言模型兼容。具体来说,CogVLM-17B 采用 Vicuna-7B-v1.5 进行进一步训练;也选择了 GLM 系列模型和 Llama 系列模型做了相应的训练。
- 视觉专家模块:在每层添加一个视觉专家模块,以实现深度的视觉 - 语言特征对齐。具体来说,每层视觉专家模块由一个 QKV 矩阵和一个 MLP 组成。
训练方式:
- 模型在15亿张图文对上预训练了4096个A100*days,并在构造的视觉定位(visual grounding)数据集上进行二阶段预训练。
- 在对齐阶段,CogVLM使用了各类公开的问答对和私有数据集进行监督微调,使得模型能回答各种不同类型的提问。
2. 模型效果
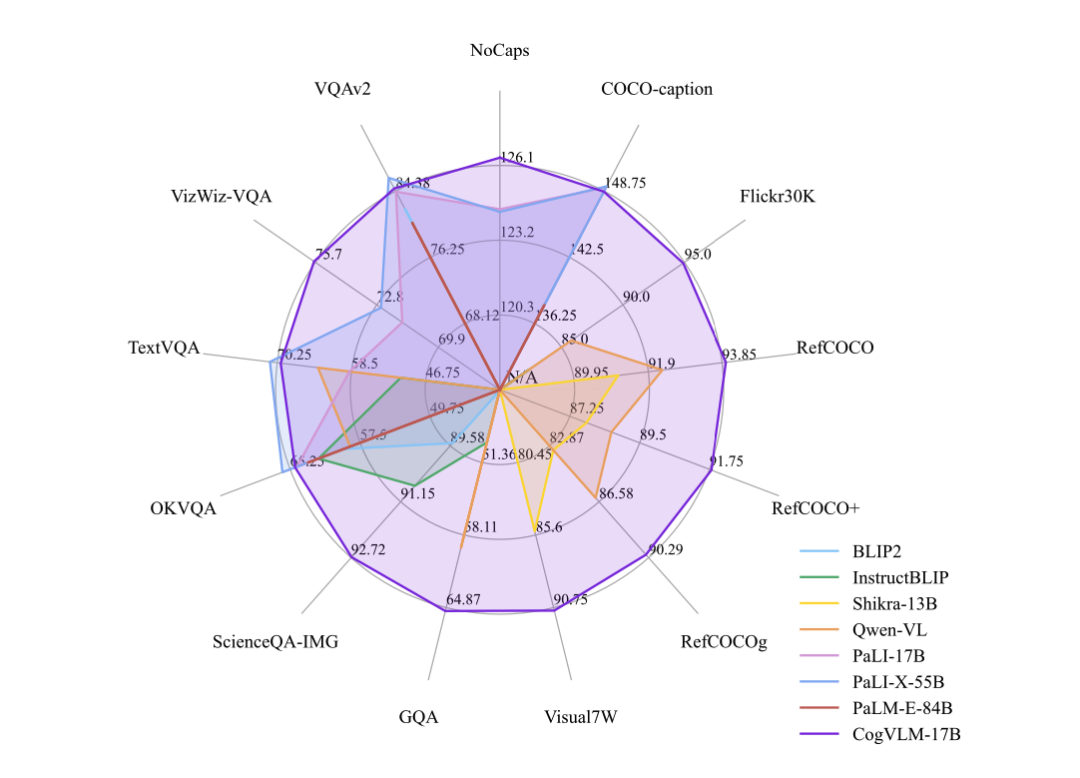
CogVLM 可以在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合。训练的 CogVLM-17B 是目前多模态权威学术榜单上综合成绩第一的模型,在14个数据集上取得了state-of-the-art或者第二名的成绩。这些基准大致分为三类(共 14 个),包括图像字幕(Image Captioning)、视觉问答(Visual QA)、视觉定位(Visual Grounding)。
文生图:CogView3模型
链接:https://github.com/THUDM/CogView
DALL-E3模型
论文:https://cdn.openai.com/papers/dall-e-3.pdf
CogVideo模型
论文链接:https://arxiv.org/abs/2205.15868
代码链接:https://github.com/THUDM/CogVideo
模型训练方法:
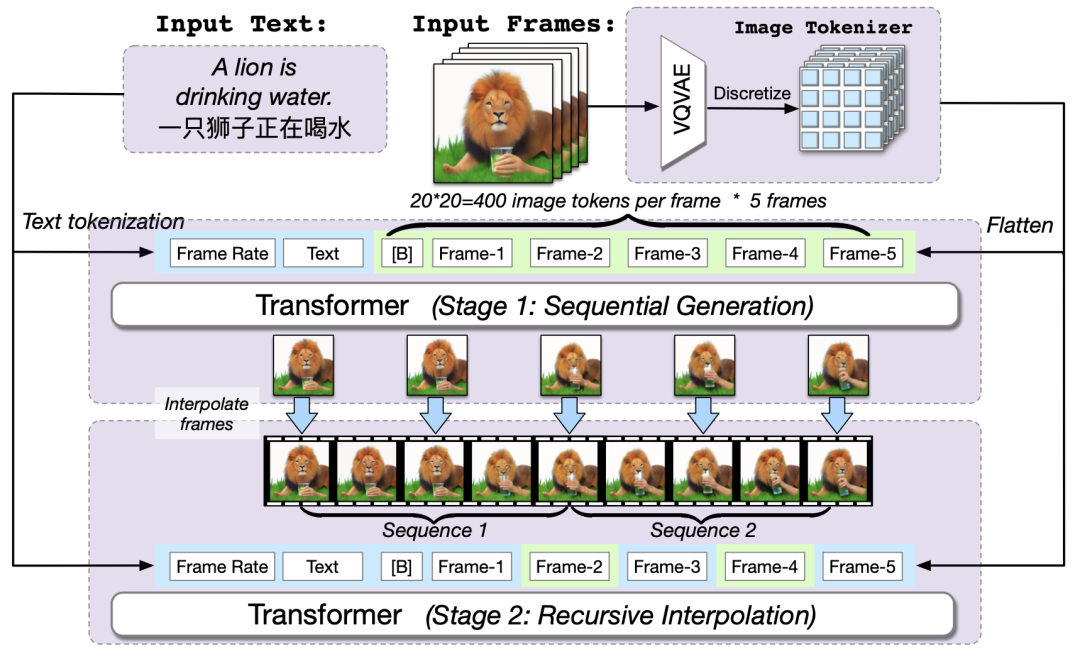
- 首先基于本文作者团队提出的文本合成图像模型CogView2,CogView2是一个包含60亿参数的预训练transformer模型,CogVideo可以看做是CogView2的视频升级版本,CogVideo共有94亿个参数,并在540万个文本视频对上进行了训练。
- CogVideo的训练主要基于本文提出的多帧分层生成框架,具体来说就是先根据CogView2通过输入文本生成几帧图像,然后再根据这些图像进行插帧提高帧率完成整体视频序列的生成。为了更好的在嵌入空间中对齐文本和视频片段,提高模型对文本预训练知识的迁移,作者提出了一种双通道注意力机制来提高性能。
- 此外为了应对模型超大的参数和长视频序列的存储压力,作者将Swin Transformer[4]中的滑动窗口引入到了本文的自回归视频生成任务中
多帧率分层训练方法:
网易伏羲-丹青模型
丹青模型基于原生中文语料数据及网易自有高质量图片数据训练,与其他文生图模型相比,丹青模型的差异化优势在于对中文的理解能力更强,对中华传统美食、成语、俗语、诗句的理解和生成更为准确。比如,丹青模型生成的图片中,鱼香肉丝没有鱼,红烧狮子头没有狮子。基于对中文场景的理解,丹青模型生成的图片更具东方美学,能生成“飞流直下三千尺”的水墨画,也能生成符合东方审美的古典美人。
Reference
[1] https://github.com/THUDM/CogVLM
[2] CogVLM:智谱AI 新一代多模态大模型
[3] CogView:通过Transformer掌握文本到图像的生成
[4] 清华联合BAAI提出第一个开源预训练文本视频生成模型CogVideo
[5] OpenAI最新的文本生成图像大模型DALL·E3
[6] (2023,DALL-E3,两步微调,标题重建)通过更好的标题改进图像生成
这篇关于【LLM多模态】Cogview3、DALL-E3、CogVLM、CogVideo模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








