本文主要是介绍英伟达发布 VILA 视觉语言模型,实现多图像推理、增强型上下文学习,性能超越 LLaVA-1.5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
近年来,大型语言模型 (LLM) 的发展取得了显著的成果,并逐渐应用于多模态领域,例如视觉语言模型 (VLM)。VLM 旨在将 LLM 的强大能力扩展到视觉领域,使其能够理解和处理图像和文本信息,并完成诸如视觉问答、图像描述生成等任务。然而,现有的 VLM 通常缺乏对视觉语言预训练过程的深入研究,导致模型在多模态任务上的性能和泛化能力受限。为了解决这个问题,英伟达的研究人员发布了 VILA,一种全新的 VLM,通过改进的预训练方法实现了多图像推理、增强型上下文学习等能力,并在多个基准测试中性能超越了 SOTA 模型 LLaVA-1.5。
-
Huggingface模型下载:https://huggingface.co/Efficient-Large-Model/Llama-3-VILA1.5-8B
-
AI快站模型免费加速下载:https://aifasthub.com/models/Efficient-Large-Model

技术特点
优化视觉语言预训练过程
VILA 的核心技术在于对视觉语言预训练过程的优化。研究人员通过对预训练数据集、训练策略和模型架构进行深入研究,发现了影响 VLM 性能的关键因素:
-
更新 LLM: 传统的 VLM 预训练方法通常冻结 LLM 参数,仅训练视觉编码器和投影层。而 VILA 发现,更新 LLM 参数对于模型的上下文学习能力至关重要。通过更新 LLM,模型能够更好地将视觉和文本特征融合到深层网络中,从而提高对多模态信息的理解能力。
-
交错式视觉语言数据: VILA 发现,使用交错式视觉语言数据(例如 MMC4 数据集)进行预训练,能够更好地保留 LLM 的文本处理能力,并提升模型在视觉语言任务上的性能。与仅包含图像-文本对的数据集相比,交错式数据集更接近于 LLM 预训练所使用的纯文本语料,因此能够更有效地进行模态对齐。
-
联合监督微调: 为了弥补预训练过程中 LLM 文本能力的下降,VILA 采用联合监督微调方法,将纯文本指令数据添加到视觉语言指令数据中进行微调。这种方法不仅能够恢复 LLM 的文本能力,还能提升模型在视觉语言任务上的准确率。
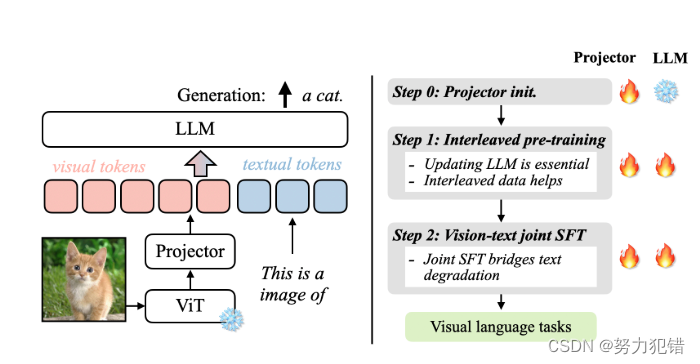
简单高效的模型架构
VILA 采用了简单高效的模型架构,包括视觉编码器、LLM 和投影层。视觉编码器用于提取图像特征,LLM 用于处理文本和视觉特征,投影层用于将视觉特征映射到 LLM 的输入空间。VILA 使用 CLIP 模型作为视觉编码器,并使用 Llama-2 作为 LLM。投影层则采用简单的线性层,以保证模型的效率。
性能表现
VILA 在 12 个视觉语言基准测试中展现出优异的性能,并超越了 SOTA 模型 LLaVA-1.5,例如:
-
VQAv2: VILA-13B 的准确率达到了 80.8%,高于 LLaVA-1.5-13B 的 80.0%。
-
GQA: VILA-13B 的准确率达到了 63.3%,高于 LLaVA-1.5-13B 的 63.3%。
-
TextVQA: VILA-13B 的准确率达到了 73.7%,高于 LLaVA-1.5-13B 的 71.6%。
-
多语言能力: VILA 在 MMBench-Chinese 基准测试中也取得了优异的成绩,表明其具有多语言处理能力。
此外,VILA 还表现出强大的文本处理能力,在 MMLU、BBH 和 DROP 等文本基准测试中也取得了与 Llama-2 相当的成绩。

应用场景
VILA 凭借其强大的性能和多模态理解能力,在众多应用场景中具有巨大潜力:
-
视觉问答: VILA 可以用于回答与图像相关的问题,例如“图片中有什么?”、“这个人正在做什么?”等。
-
图像描述生成: VILA 可以根据图像内容生成详细的描述,例如“这是一张海滩的照片,沙滩上有很多人在晒太阳”。
-
多模态对话: VILA 可以与用户进行多模态对话,例如用户可以上传一张图片并询问相关问题,VILA 可以根据图片内容进行回答。
-
多图像推理: VILA 能够理解多张图片之间的关系,并进行推理,例如找出多张图片中的共同点或差异。

总结
VILA 是英伟达发布的一款全新的视觉语言模型,通过优化预训练方法实现了多图像推理、增强型上下文学习等能力,并在多个基准测试中性能超越了 SOTA 模型 LLaVA-1.5。VILA 的发布表明,视觉语言预训练对于 VLM 的性能提升至关重要,而交错式数据、LLM 参数更新和联合监督微调则是提升 VLM 性能的关键因素。相信 VILA 将会推动 VLM 的进一步发展,为多模态人工智能应用带来更多可能性。
模型下载
Huggingface模型下载
https://huggingface.co/Efficient-Large-Model/Llama-3-VILA1.5-8B
AI快站模型免费加速下载
https://aifasthub.com/models/Efficient-Large-Model
这篇关于英伟达发布 VILA 视觉语言模型,实现多图像推理、增强型上下文学习,性能超越 LLaVA-1.5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






