本文主要是介绍详解Mixtral-8x7B背后的MoE!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高端的模型往往只需最朴素的发布方式。


这个来自欧洲的大模型团队在12月8日以一条磁力链接的方式发布了Mixtral-8x7B,这是一种具有开放权重的**「高质量稀疏专家混合模型」**(SMoE)。
该模型在大多数基准测试中都优于Llama2-70B,相比之下推理速度快了6倍,同时在大多数标准基准测试中匹配或优于GPT-3.5。
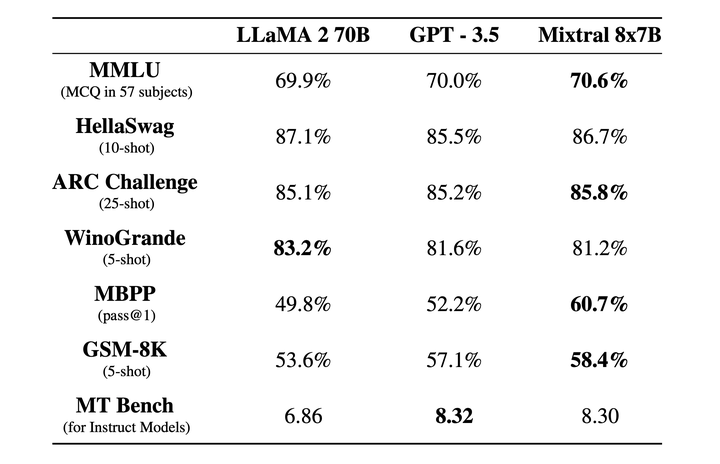

之后,Mixtral AI将模型权重推送至HuggingFace,并一起推送了Mixtral-8x7B-Instruct。该模型已通过监督微调和直接偏好优化(DPO)进行优化,更加遵循指令。在MT-Bench上,它达到了8.30的分数,使其成为最好的开源模型,性能可与GPT3.5相媲美。
Mixtral-8x7B共有46.7B个参数,但每个token仅使用12.9B个参数。也就是说该模型可以每次只需要120亿参数参与推理就可以达到700亿的LLaMA2
这篇关于详解Mixtral-8x7B背后的MoE!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







