mixtral专题
![[论文笔记]Mixtral of Experts](https://img-blog.csdnimg.cn/img_convert/b06b142a1959182b9b6723bbcd6914ba.png)
[论文笔记]Mixtral of Experts
引言 今天带来大名鼎鼎的Mixtral of Experts的论文笔记,即Mixtral-8x7B。 作者提出了Mixtral 8x7B,一种稀疏专家混合(Sparse Mixture of Experts,SMoE)语言模型。Mixtral与Mistral 7B具有相同的架构,不同之处在于每个层由8个前馈块(即专家)组成。对于每个令牌(Token),在每个层中,路由器网络选择两个专家处理当前
阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B!
本文原文来自DataLearnerAI官方网站:阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051714140775766 Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为
微软Phi-3,3.8亿参数能与Mixtral 8x7B和GPT-3.5相媲美,量化后还可直接在IPhone中运行
Phi-3系列 Phi-3是一系列先进的语言模型,专注于在保持足够紧凑以便在移动设备上部署的同时,实现高性能。Phi-3系列包括不同大小的模型: Phi-3-mini(38亿参数) - 该模型在3.3万亿个令牌上进行训练,设计得足够小,可以在现代智能手机上运行。尽管体积紧凑,它的性能却可与更大的模型如Mixtral 8x7B和GPT-3.5相媲美,例如在MMLU基准测试中达到69%,在MT-b

详解Mixtral-8x7B背后的MoE!
高端的模型往往只需最朴素的发布方式。 这个来自欧洲的大模型团队在12月8日以一条磁力链接的方式发布了Mixtral-8x7B,这是一种具有开放权重的**「高质量稀疏专家混合模型」**(SMoE)。 该模型在大多数基准测试中都优于Llama2-70B,相比之下推理速度快了6倍,同时在大多数标准基准测试中匹配或优于GPT-3.5。 之后,Mixtral AI将模型权重推送至Hug

Mistral AI突围:开源大模型Mixtral 8x22B颠覆行业格局
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 巴黎的小伙伴Mistral AI不甘寂寞,冲出重围,推出了全新的大型语言

阿里Qwen1.5-32B开源,评测超Mixtral MoE,挑战SOTA性价比
前言 阿里巴巴近日震撼开源其最新力作——Qwen1.5-32B大语言模型。在当前AI领域,大模型的开发与应用已成为评估技术进步的重要标尺。Qwen1.5-32B的问世,不仅再次证明了阿里在AI技术研发领域的深厚实力,更是在性能与成本之间找到了一个新的平衡点。 Qwen1.5-32B模型简介 Qwen1.5-32B继承了Qwen系列模型的卓越传统,拥有320亿参数,是在Qwen1.5系列中规模

七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b,对GPT4胜率超过80%
模型训练 Mixtral-8x7b地址:魔搭社区 GitHub: hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100+ LLMs (github.com) 环境配置 git clone https://github.com/hiyouga/LLaMA-Factory.gitconda create -n llama_fa

七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b
模型训练 Mixtral-8x7b地址:魔搭社区 GitHub: hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100+ LLMs (github.com) 环境配置 git clone https://github.com/hiyouga/LLaMA-Factory.gitconda create -n llama_fa

最强开源模型 Mixtral-8x7B-Instruct-v0.1 详细介绍:稀疏 Mixtral of experts
LLM votes 评测排行榜: https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard 模型链接: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1
linux部署Mixtral-8x7B-Instruct实践(使用vLLM/ transformer+fastapi)
前提说明: 这次实践用了两张A800(80G),每张卡消耗70G显存,总计140G step1:下载模型 从huggingface(需科学上网)和modelscope两个平台下载模型 step2:安装vLLM 之前部署大模型用transformer库+OpenAI api,会有推理速度慢,server部署起来比较复杂的缺点,vLLM是一个LLM推理和服务库,原理类似于操作系统的虚拟内存
从Mistral 7B到MoE模型Mixtral 8x7B的全面解析:从原理分析到代码解读
前言 本文先全面介绍Mistral 7B,然后再全面介绍Mixtral 8x7B 对于后者,毕竟OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。早些时候,有人爆料 GPT-4 是采用了由 8 个专家模型组成的集成系统。后来又有传闻称,ChatGPT 也只是百亿参数级的模型(大概在 200 亿左右) 传闻无从证明,但 Mixtral 8x7B 可能提供了一种「非常接近 GPT

本地运行Mixtral-8x7B,我滴AI我做猪
最初是参考了大佬的介绍自己跑了一下:https://juejin.cn/post/7319541634122907699。然后发现自己实际运行时有些小问题和可以补充的。 Mixtral-8x7B介绍 2023年12月11日Mistral 发布了一个激动人心的大语言模型: Mixtral 8x7b。Mixtral 的架构与 Mistral 7B 类似,但有一点不同: 它实际上内含了 8 个“专家

Nous Hermes 2:超越Mixtral 8x7B的MOE模型新高度
引言 随着人工智能技术的迅猛发展,开源大模型在近几年成为了AI领域的热点。最近,Nous Research公司发布了其基于Mixtral 8x7B开发的新型大模型——Nous Hermes 2,这一模型在多项基准测试中超越了Mixtral 8x7B Instruct,标志着MOE(Mixture of Experts,专家混合模型)技术的新突破。 Huggingface模型下载:https:
快速玩转 Mixtral 8x7B MOE大模型!阿里云机器学习 PAI 推出最佳实践
作者:熊兮、贺弘、临在 Mixtral 8x7B大模型是Mixtral AI推出的基于decoder-only架构的稀疏专家混合网络(Mixture-Of-Experts,MOE)开源大语言模型。这一模型具有46.7B的总参数量,对于每个token,路由器网络选择八组专家网络中的两组进行处理,并且将其输出累加组合,在增加模型参数总量的同时,优化了模型推理的成本。在大多数基准测试中,Mixtral

机器学习周刊第六期:哈佛大学机器学习课、Chatbot Ul 2.0 、LangChain v0.1.0、Mixtral 8x7B
— date: 2024/01/08 — 吴恩达和Langchain合作开发了JavaScript 生成式 AI 短期课程:《使用 LangChain.js 构建 LLM 应用程序》 大家好,欢迎收看第六期机器学习周刊 本期介绍10个内容,涉及Python、机器学习、大模型等,目录如下: 1、哈佛大学机器学习课2、第一个 JavaScript 生成式 Al 短期课程3、一个地理相关

4bit/8bit 启动 Mixtral 8*7B 大语言模型
4bit/8bit 启动 Mixtral 8*7B 大语言模型 0. 背景1. 修改代码 0. 背景 个人电脑配置实在难以以 float16 运行 Mixtral 8*7B 大语言模型,所以参数 4bit 或者 8bit 来启动。 实际测试结果,4bit 时推理速度明显变快了,8bit 时推理也非常慢。 使用的推理框架时 fastchat。 1. 修改代码 vi fast
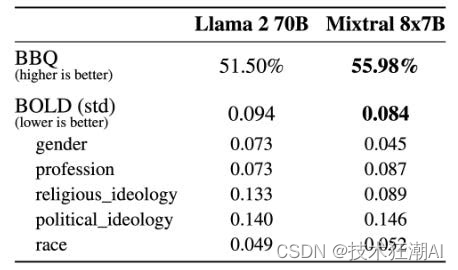
深入解析 Mistral AI 的 Mixtral 8x7B 开源MoE大模型
资源分享 1、可在公众号「技术狂潮AI」中回复「GPTs」可获得 「GPTs Top100 深度体验分析报告」PDF 版报告,由椒盐玉兔第一时间输出的一份非常详细的GPTs体验报告。 2、可在公众号「技术狂潮AI」中回复「大模型案例」可获得 「720-2023大模型落地应用案例集」PDF 版报告,主要包含大模型2023年国内落地应用案例集。 3、可在公众号「技术狂潮AI」中回复「AIGC202
Mixtral Moe代码解读
一直对稀疏专家网络好奇,有些专家没被选中,那么梯度是否为0,这一轮被选中有梯度,下一轮没被选中无梯度,模型可以训练收敛吗? 由于每个token都会选择topk个专家,所以在每一轮epoch中,所有专家都参与了前向传播,所以梯度都能得到更新即使真有专家一直没被选中,那么其梯度保持不变,没有参与更新而已 self.gate = nn.Linear(self.hidden_dim, self.num_
论文系列之-Mixtral of Experts
Q: 这篇论文试图解决什么问题? A: 这篇论文介绍了Mixtral 8x7B,这是一个稀疏混合专家(Sparse Mixture of Experts,SMoE)语言模型。它试图解决的主要问题包括: 1. 提高模型性能:通过使用稀疏混合专家结构,Mixtral在多个基准测试中超越或匹配了现有的大型模型(如Llama 2 70B和GPT-3.5),尤其是在数学、代码生成和多语言理解任务上。2.
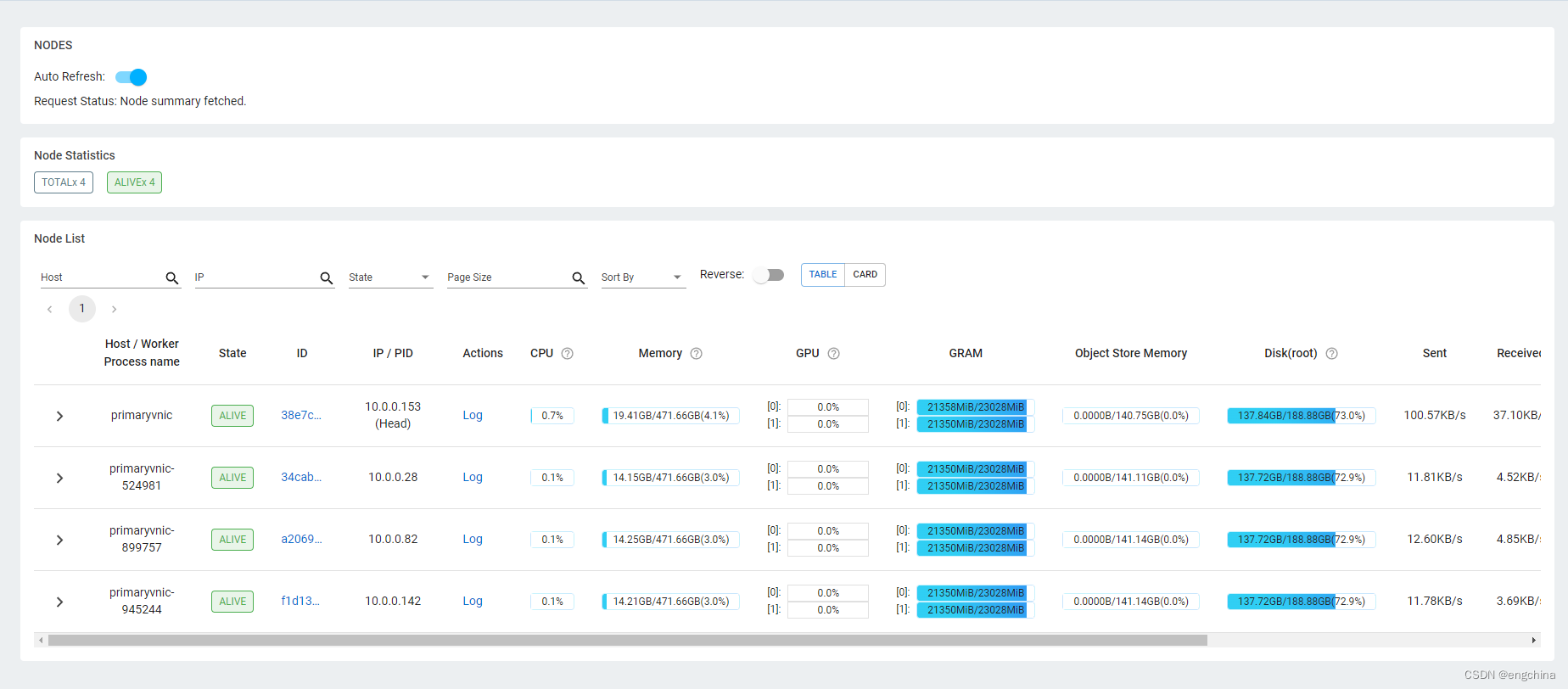
在甲骨文云上用 Ray +Vllm 部署 Mixtral 8*7B 模型
在甲骨文云上用 Ray +Vllm 部署 Mixtral 8*7B 模型 0. 背景1. 甲骨文云 GPU 实例2. 配置 VCN 的 Security List3. 安装 Ray 和 Vllm4. 启动 Ray5. 启动 Vllm 0. 背景 根据好几个项目的需求,多次尝试 Mixtral-8x7B-Instruct-v0.1 这个模型,确实性能不错。 怎奈自己的个人电脑在配
欢迎 Mixtral - 当前 Hugging Face 上最先进的 MoE 模型
最近,Mistral 发布了一个激动人心的大语言模型: Mixtral 8x7b,该模型把开放模型的性能带到了一个新高度,并在许多基准测试上表现优于 GPT-3.5。我们很高兴能够在 Hugging Face 生态系统中全面集成 Mixtral 以对其提供全方位的支持 🔥! Hugging Face 对 Mixtral 的全方位支持包括: Hub 上的模型,包括模型卡以及相应的许可证 (Apa
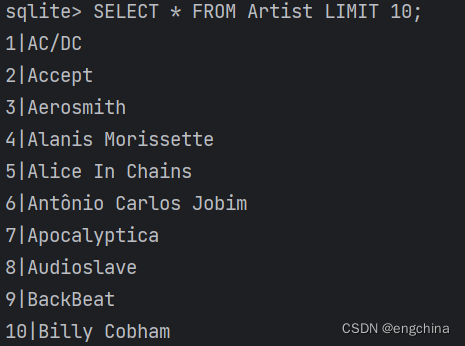
验证 Mixtral-8x7B-Instruct-v0.1 和 LangChain SQLDatabaseToolkit 的集成效果
验证 Mixtral-8x7B-Instruct-v0.1 和 LangChain SQLDatabaseToolkit 的集成效果 0. 背景1. 验证环境说明2. 验证开始2-1. 准备测试数据库2-2. 读取环境配置信息2-3. 导入依赖包2-3. 创建 SQLDatabaseToolkit 对象和 AgentExecutor 对象2-4. 第1个测试 - 描述一个表2-5. 第2个测
Mixtral: 专家云集 高质量的稀疏专家组合
Mixtral: 专家云集 高质量的稀疏专家组合 Mistral AI 继续履行其使命,为开发者社区提供最佳的开放模型。人工智能的发展需要采取新的技术转向,而不仅仅是重用众所周知的架构和训练范式。最重要的是,需要让社区从原始模型中受益,以促进新的发明和使用。 Mistral AI 团队自豪地发布了 Mixtral 8x7B,这是一个具有开放权重的高质量稀疏专家模型 (SMoE) 混合。在 Ap

谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!
文章目录 谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!!前言重磅!Mixtral MoE 8x7B!!!Mixtral是啥模型介绍模型结构长啥样?表现如何?可以白嫖吗?哪里可以获取? 谁会成为第一个MoE大模型基座呢?重磅!Mixtral MoE 8x7B!!! 话放这里,我敢说Mixtral MoE 8x7B!!! 将会是MoE技术路线上的基座