本文主要是介绍在甲骨文云上用 Ray +Vllm 部署 Mixtral 8*7B 模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在甲骨文云上用 Ray +Vllm 部署 Mixtral 8*7B 模型
- 0. 背景
- 1. 甲骨文云 GPU 实例
- 2. 配置 VCN 的 Security List
- 3. 安装 Ray 和 Vllm
- 4. 启动 Ray
- 5. 启动 Vllm
0. 背景
根据好几个项目的需求,多次尝试 Mixtral-8x7B-Instruct-v0.1 这个模型,确实性能不错。
怎奈自己的个人电脑在配置上确实无法驾驭 Mixtral-8x7B-Instruct-v0.1 这个 46.7B 的模型(速度太慢),今天就尝试基于甲骨文云的 GPU 实例部署一下,来应对接下来的开发。
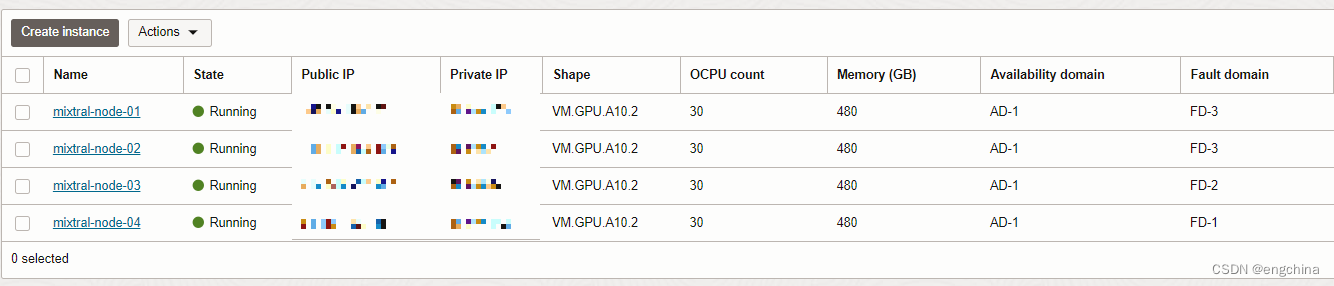
1. 甲骨文云 GPU 实例
今天部署 Mixtral-8x7B-Instruct-v0.1 这个 46.7B 的模型,使用了甲骨文云 4 个 VM.A10.2 GPU 实例,1个 VM.A10.2 有 2 个 24GB 的 A10 GPU,4个的话是 4 * 24GB * 2 = 192GB GPU。
2. 配置 VCN 的 Security List
配置私网 CIDR 10.0.0.0/24 的 All Protocols 是开放的。
注意:生产环境请仅开放必要端口
3. 安装 Ray 和 Vllm
pip install -U ray ray[client] ray[default] vllm
4. 启动 Ray
启动 head node,
ray start --disable-usage-stats --head --num-gpus 2 --include-dashboard True --dashboard-host 0.0.0.0 --dashboard-port 8265
To add another node to this Ray cluster,
ray start --disable-usage-stats --num-gpus 2 --address='<head node ip>:6379'
5. 启动 Vllm
这里使用了 8 个 GPU,所以设置 --tensor-parallel-size 的值是 8。
python -m vllm.entrypoints.openai.api_server --trust-remote-code --served-model-name gpt-4 --model mistralai/Mixtral-8x7B-Instruct-v0.1 --gpu-memory-utilization 1 --tensor-parallel-size 8 --port 8000
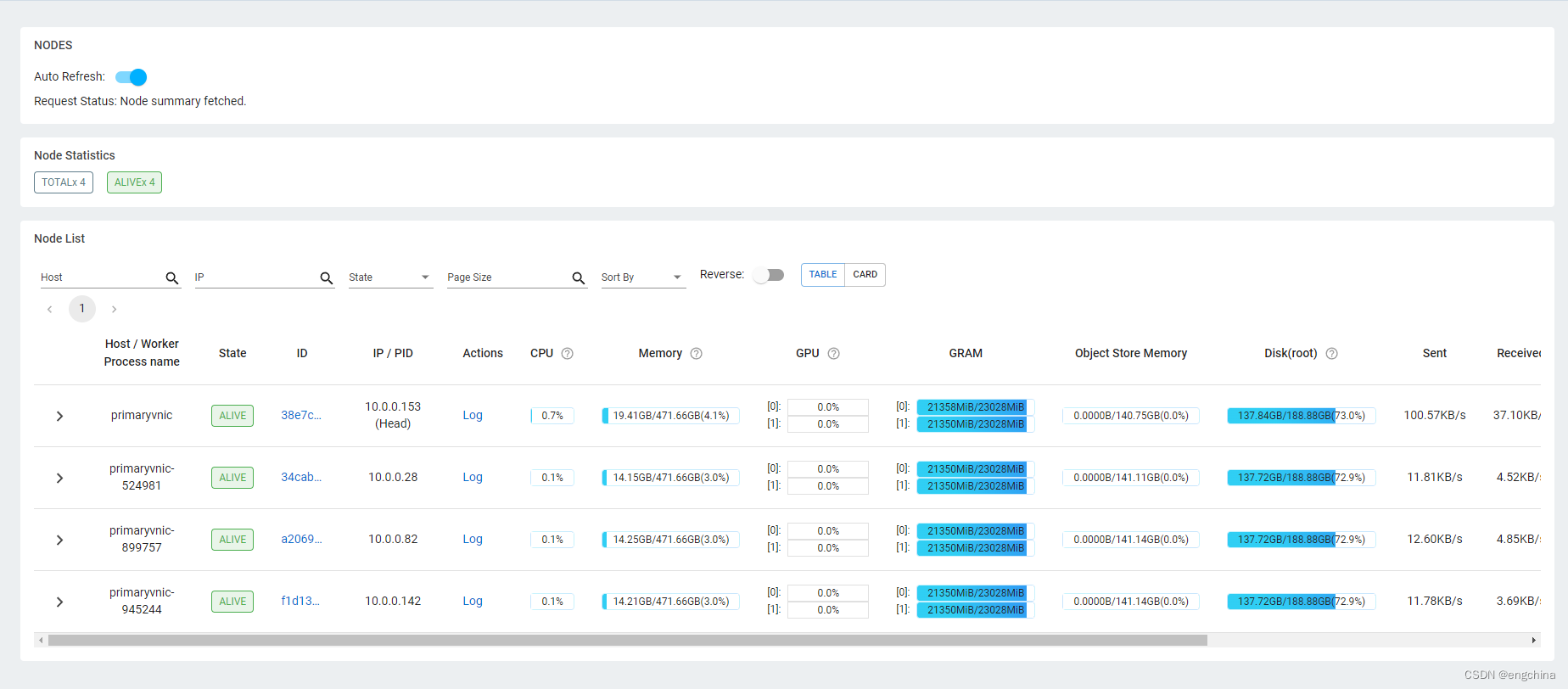
启动之后,通过 Ray Dashboard 查看 Cluster 的情况。
完结!
这篇关于在甲骨文云上用 Ray +Vllm 部署 Mixtral 8*7B 模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








