7b专题
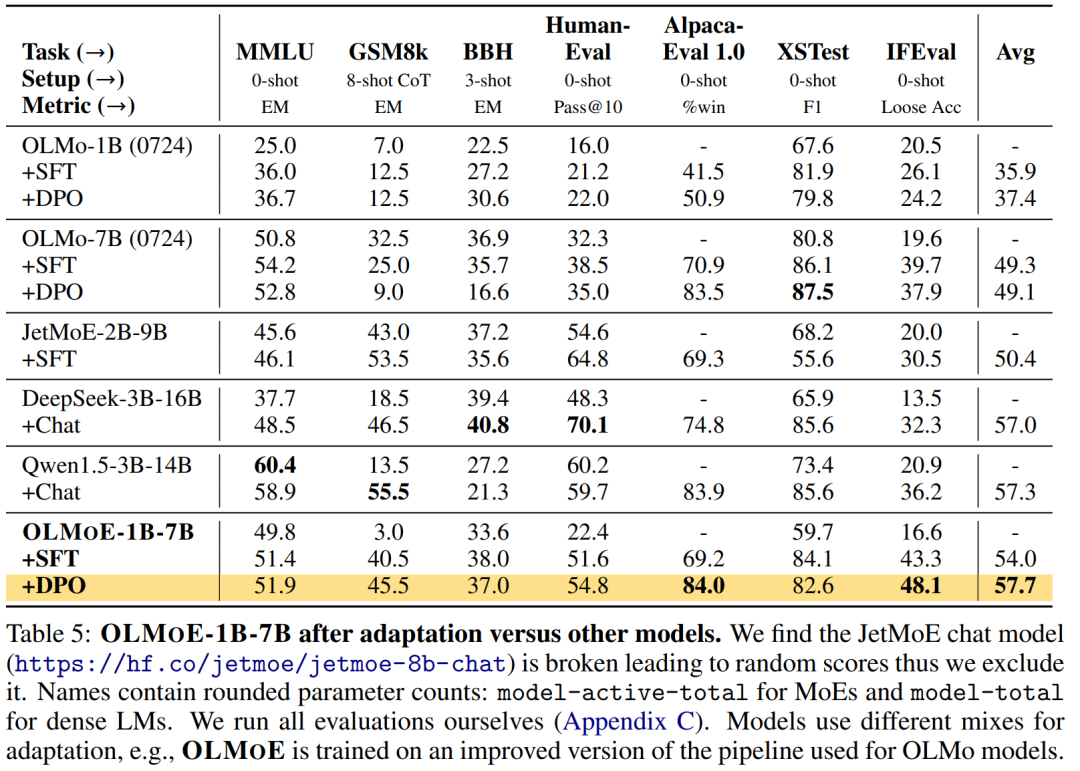
第一个100%开源的MoE大模型,7B的参数,1B的推理成本
尽管大语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。 对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建和部署成本过高。改善成本 - 性能的一种方法是使用稀疏激活混合专家 (MoE)。MoE 在每一层都有几个专家,每次只激活其中的一个子集(参见图 2)。这使得 MoE 比具有相似参数量的密集模型更有效,因为密集模型为每个

Qwen-7B-Chat大模型安装训练推理-helloworld
初始大模型之helloworld编写 开发环境:modelscope GPU版本上测试的,GPU免费36小时 ps:可以不用conda直接用环境自带的python环境使用 魔搭社区 安装conda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh 1.2 bash Minicond

使用docker部署tensorrtllm推理大模型baichuan2-7b
简介 大模型的推理框架,我之前用过vllm和mindie。近期有项目要用tensorrtllm,这里将摸索的过程记录下,特别是遇到的问题。 我的环境是Linux+rt3090 准备docker环境 本次使用docker镜像部署,需要从网上拉取: docker pull nvcr.io/nvidia/tritonserver:24.08-trtllm-python-py3 The Tri

240831-Qwen2-VL-7B/2B部署测试
A. 运行效果 B. 配置部署 如果可以执行下面就执行下面: pip install git+https://github.com/huggingface/transformers accelerate 否则分开执行 git clone https://github.com/huggingface/transformerscd transformerspip install .

开源模型应用落地-qwen2-7b-instruct-LoRA微调合并-ms-swift-单机单卡-V100(十三)
一、前言 本篇文章将使用ms-swift去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游

Docker下使用llama.cpp部署带Function calling和Json Mode功能的Mistral 7B模型
Docker下使用llama.cpp部署带Function calling和Json Mode功能的Mistral 7B模型 说明: 首次发表日期:2024-08-27参考: https://www.markhneedham.com/blog/2024/06/23/mistral-7b-function-calling-llama-cpp/https://github.com/abetlen/

基于huggingface peft进行qwen1.5-7b-chat训练/推理/服务发布
一、huggingface peft微调框架 1、定义 PEFT 是一个为大型预训练模型提供多种高效微调方法的Python库。 微调传统范式是针对每个下游任务微调模型参数。大模型参数总量庞大,这种方式变得极其昂贵和不切实际。PEFT采用的高效做法是训练少量提示参数(Prompt Tuning)或使用低秩适应(LORA)等重新参数化方法来减少微调时训练参数的数量。 二、qwen-1.5b-c
开源模型应用落地-qwen2-7b-instruct-LoRA微调模型合并-Axolotl-单机单卡-V100(十)
一、前言 本篇文章将使用Axolotl去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任

【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding)
【大模型LLMs】RAG实战:基于LlamaIndex快速构建RAG链路(Qwen2-7B-Instruct+BGE Embedding) 1. 环境准备2. 数据准备3. RAG框架构建3.1 数据读取 + 数据切块3.2 构建向量索引3.3 检索增强3.4 main函数 参考 基于LlamaIndex框架,以Qwen2-7B-Instruct作为大模型底座,bge-base-
![[大模型]XVERSE-7B-chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/6217e32fe0a64f2c9a95361ec720c3c3.png#pic_center)
[大模型]XVERSE-7B-chat WebDemo 部署
XVERSE-7B-Chat为XVERSE-7B模型对齐后的版本。 XVERSE-7B 是由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),参数规模为 70 亿,主要特点如下: 模型结构:XVERSE-7B 使用主流 Decoder-only 的标准 Transformer 网络结构,支持 8K 的上下文长度(Context Length),能满足更长
![[大模型]Qwen2-7B-Instruct 接入 LangChain 搭建知识库助手](https://img-blog.csdnimg.cn/direct/35a9895a6529488ba6e1ae90cd568f55.png#pic_center)
[大模型]Qwen2-7B-Instruct 接入 LangChain 搭建知识库助手
环境准备 在 autodl 平台中租赁一个 3090 等 24G 显存的显卡机器,如下图所示镜像选择 PyTorch–>2.1.0–>3.10(ubuntu20.04)–>12.1 接下来打开刚刚租用服务器的 JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行 demo。 pip 换源加速下载并安装依赖包 # 升级pippython -m pip install -
![[大模型]Qwen2-7B-Instruct vLLM 部署调用](https://img-blog.csdnimg.cn/direct/985ad267d2374ca98788a2ad8842f747.png#pic_center)
[大模型]Qwen2-7B-Instruct vLLM 部署调用
vLLM 简介 vLLM 框架是一个高效的大语言模型推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。易用性:vLLM 与 HuggingFace 模型无缝集成,支持多
sqlcoder:7b sqlcoder:15b sqlcoder:70b 有什么区别呢?
sqlcoder:7B, sqlcoder:15B, 和 sqlcoder:70B 是不同规模的语言模型,具有不同数量的参数(B 代表 billion,即十亿)。以下是它们的主要区别及各自的优势: 模型规模 sqlcoder:7B: 参数数量:7 亿。优点:资源消耗较少,适合在资源有限的硬件上运行,响应速度较快。缺点:生成的查询质量和复杂性可能较低,适用于简单的 SQL 转换任务。 sql
【AI基础】第六步:纯天然保姆喂饭级-安装并运行qwen2-7b
整体步骤类似于 【AI基础】第五步:纯天然保姆喂饭级-安装并运行chatglm3-6b-CSDN博客。 此系列文章列表: 【AI基础】概览 【AI基础】第一步:安装python开发环境-windows篇_下载安装ai环境python 【AI基础】第一步:安装python开发环境-conda篇_minicode怎么换虚拟环境 【AI基础】第二步:安装AI运行环境 【AI基础】第三步:纯天然保姆喂

Qwen2 阿里最强开源大模型(Qwen2-7B)本地部署、API调用和WebUI对话机器人
阿里巴巴通义千问团队发布了Qwen2系列开源模型,该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B。对比当前最优的开源模型,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的Llama3-70B等大模型。 老牛同学今天部署和体验Qwen2-
开源模型应用落地-Qwen2-7B-Instruct与vllm实现推理加速的正确姿势(十)
一、前言 目前,大语言模型已升级至Qwen2版本。无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训练,并通过高质量数据进行后期微调以贴近人类偏好。在本篇学习中,将集成vllm实现模型推理加速,现在,我们赶紧跟上技术发展的脚步,去体验一下新版本模型的推理质量。 二、术语 2.1. vLLM vLLM是一个开源的大模型推理加速框架,通过PagedAtte

基于大模型 Gemma-7B 和 llama_index,轻松实现 NL2SQL
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学. 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总合集:《大模型面试宝典》(2024版) 发布! 本文将会介绍Text to SQL相关的概念,如何使用大模型SFT实现Text to SQL,最后介绍Text to

【多模态】35、TinyLLaVA | 3.1B 的 LMM 模型就可以实现 7B LMM 模型的效果
文章目录 一、背景二、方法2.1 模型结构2.2 训练 pipeline 三、模型设置3.1 模型结构3.2 训练数据3.3 训练策略3.4 评测 benchmark 四、效果 论文:TinyLLaVA: A Framework of Small-scale Large Multimodal Models 代码:https://github.com/TinyLLaVA/Ti
![[论文笔记]Mistral 7B](https://img-blog.csdnimg.cn/img_convert/dcb696bb82e2282965055499ff7679a6.png)
[论文笔记]Mistral 7B
引言 今天带来大名鼎鼎的Mistral 7B的论文笔记。 作者推出了Mistral 7B,这是一个70亿参数的语言模型。Mistral 7B在所有评估基准中表现优于最佳的13B开源模型(Llama 2),并且在推理、数学和代码生成方面胜过最佳发布的34B模型(Llama 1)。 该模型利用了分组查询注意力(GQA)以实现更快的推理速度,结合滑动窗口注意力(Sliding Window Att
【文末附gpt升级秘笈】关于论文“7B?13B?175B?解读大模型的参数的论文
论文大纲 引言 简要介绍大模型(深度学习模型)的概念及其在各个领域的应用。阐述参数(Parameters)在大模型中的重要性,以及它们如何影响模型的性能。引出主题:探讨7B、13B、175B等参数规模的大模型。 第一部分:大模型的参数规模 定义“B”代表的意义(Billion/十亿)。解释7B、13B、175B等参数规模的具体含义和计算方法。举例说明这些参数规模的大模型(如GPT系列、BE

7B?13B?175B?解读大模型的参数
大模型也是有大有小的,它们的大小靠参数数量来度量。GPT-3就有1750亿个参数,而Grok-1更是不得了,有3140亿个参数。当然,也有像Llama这样身材苗条一点的,参数数量在70亿到700亿之间。 这里说的70B可不是指训练数据的数量,而是指模型中那些密密麻麻的参数。这些参数就像是一个个小小的“脑细胞”,越多就能让模型更聪明,更能理解数据中那些错综复杂的关系。有了这些“脑细胞”,模型在处
大模型额外篇章二:基于chalm3或Llama2-7b训练酒店助手模型
文章目录 一、代码部分讲解二、实际部署步骤(CHALM3训练步骤)1)注册AutoDL官网实名认证2)花费额度挑选GPU3)准备实验环境4)开始执行脚本5)从浏览器访问6)可以开始提问7)开始微调模型8)测试训练后的模型 三、基于Llama2-7b的训练四、额外补充1)修改参数后2)如果需要访问科学的彼岸 一、代码部分讲解 二、实际部署步骤(CHALM3训练步骤) 1)注册
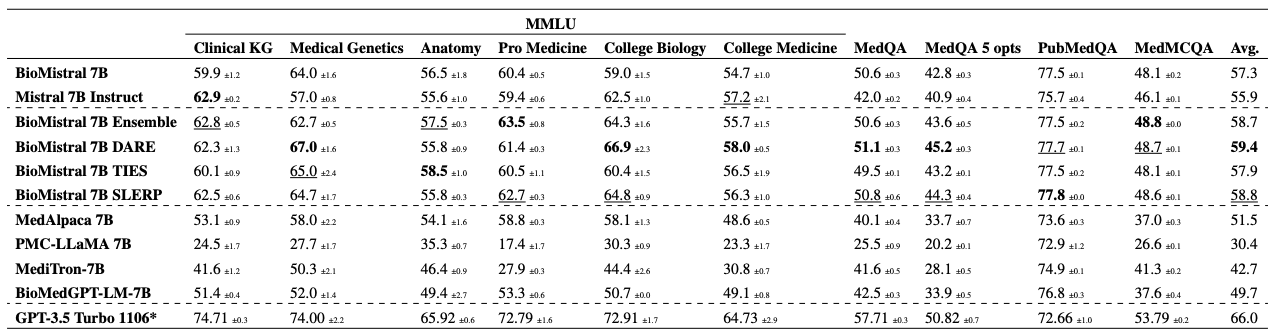
BioMistral 7B——医疗领域的新方法,专为医疗领域设计的大规模语言模型
1. 概述 自然语言处理领域正在以惊人的速度发展,ChatGPT 和 Vicuna 等大型语言模型正在从根本上改变我们与计算机交互的方式。从简单的文本理解到复杂的问题解决,这些先进的模型展示了类似人类的推理能力。 特别是,BLOOM 和 LLaMA 等开源模式在医疗保健领域日益受到关注,为该领域的创新提供了新的可能性。然而,将这些技术引入医疗保健领域也带来了独特的挑战和机遇。有许多问题需要解决
Fastchat + vllm + ray + Qwen1.5-7b 在2080ti 双卡上 实现多卡推理加速
首先先搞清各主要组件的名称与作用: FastChat FastChat框架是一个训练、部署和评估大模型的开源平台,其核心特点是: 提供SOTA模型的训练和评估代码 提供分布式多模型部署框架 + WebUI + OpenAI API Controller管理分布式模型实例 Model Worker是大模型服务实例,它在启动时向Controller注册 OpenAI API提供OpenAI兼容的A
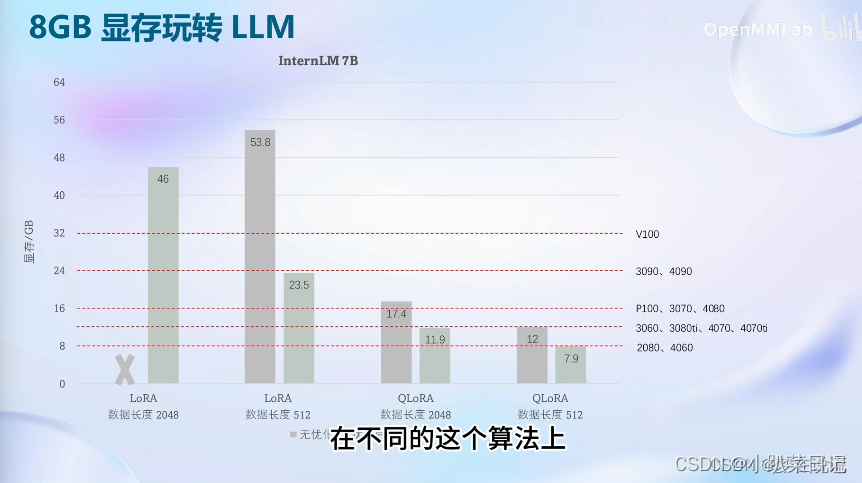
使用xtuner微调InternLM-Chat-7B
1. 安装xtuner #激活环境source activate test_llm# 安装xtunerpip install xtuner#还有一些依赖项需要安装future>=0.6.0cythonlxml>=3.1.0cssselectmmengine 2. 创建一个ft-oasst1 数据集的工作路径,进入 mkdir ft-oasst1 cd ft-oasst1

InternLM-Chat-7B部署调用-个人记录
一、环境准备 pip install modelscope==1.9.5pip install transformers==4.35.2 二、下载模型 import torchfrom modelscope import snapshot_download, AutoModel, AutoTokenizerimport osmodel_dir = snapshot_download(