vllm专题

vllm源码解析(一):整体架构与推理代码
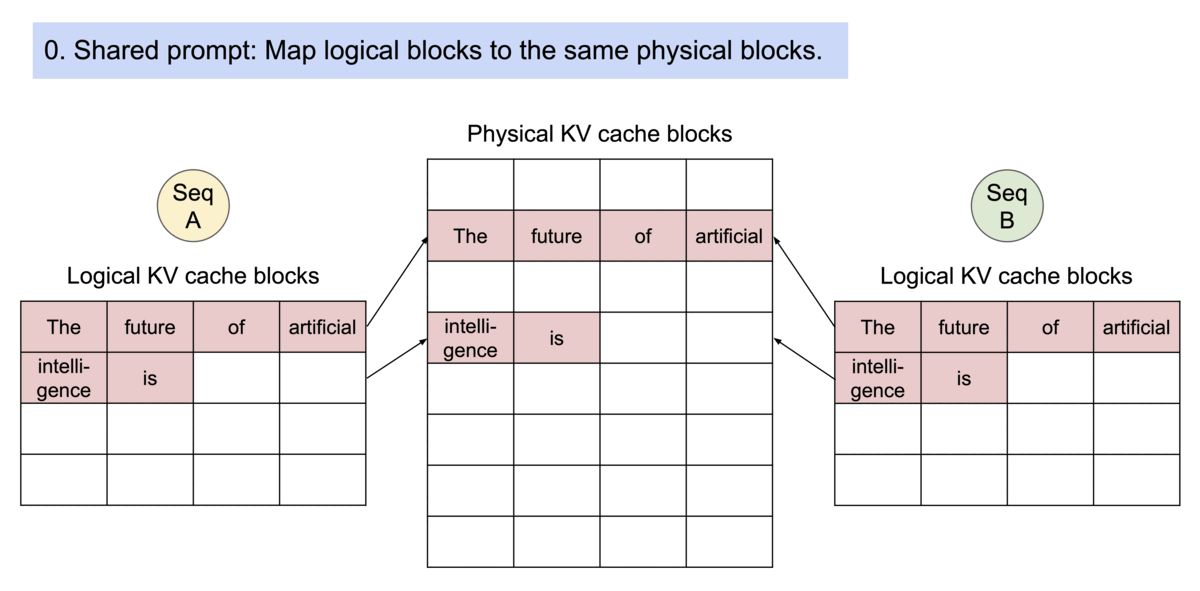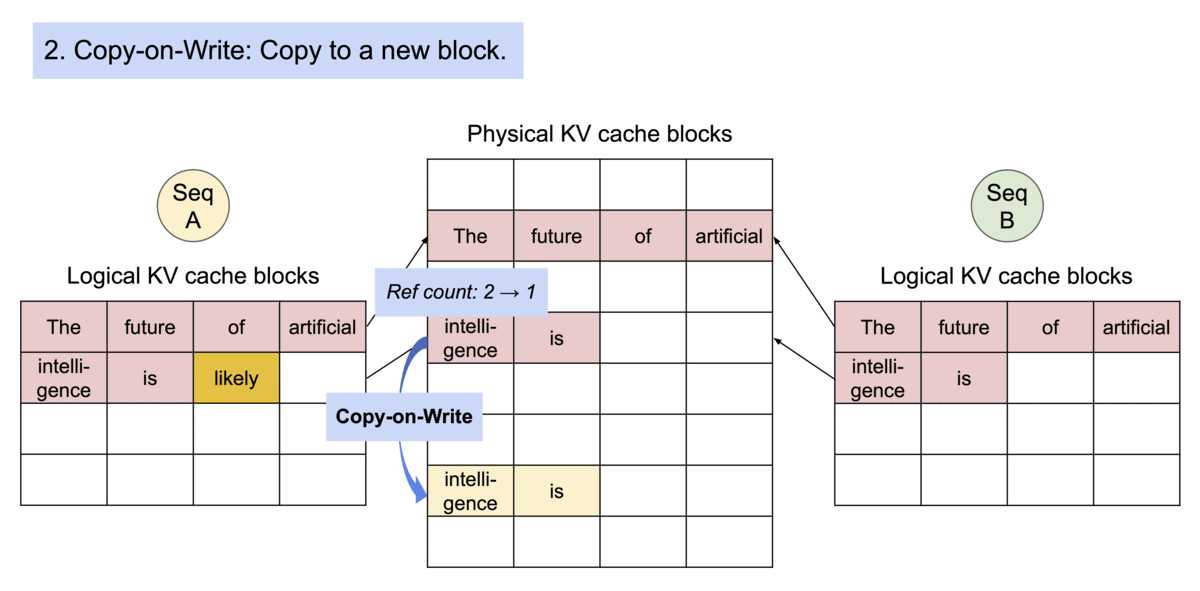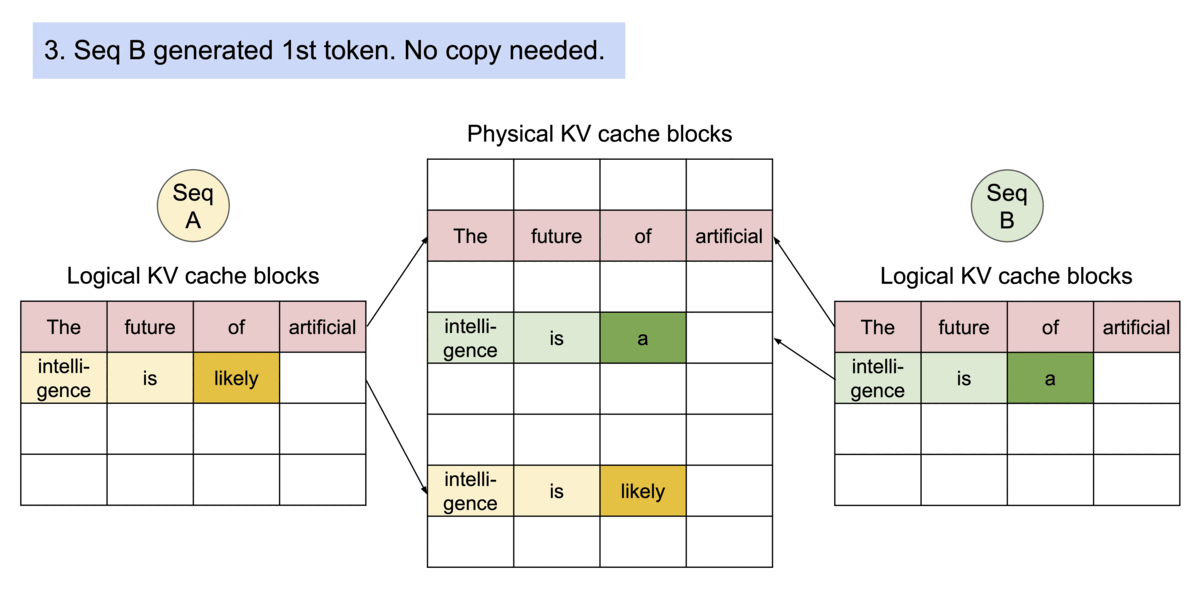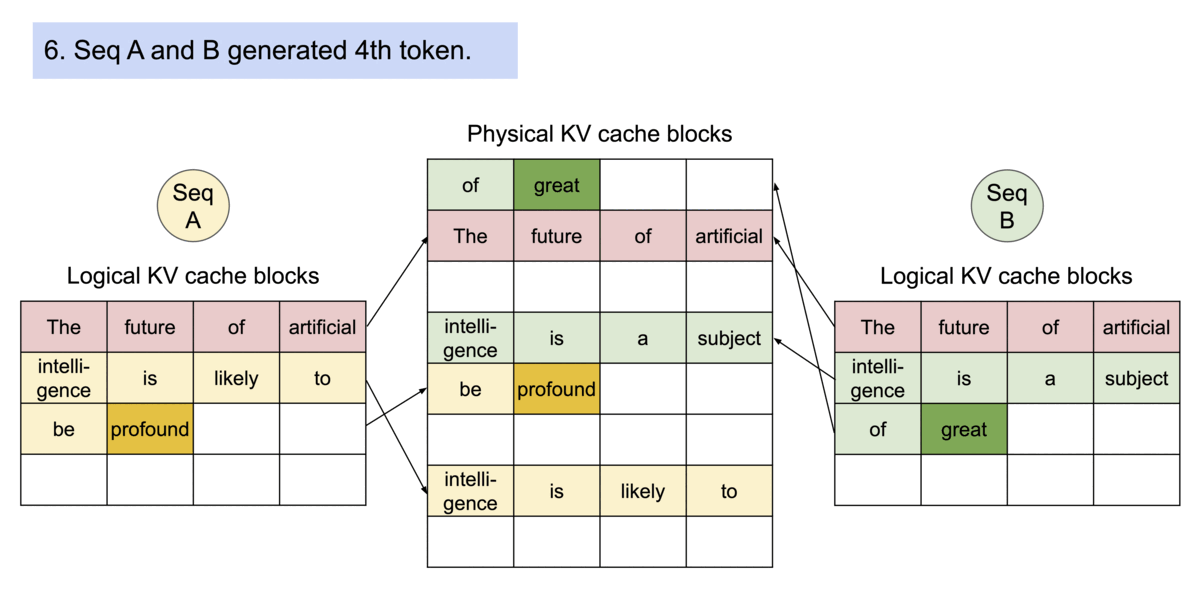
vlllm官方代码更新频发,每个版本都有极大变动, 很难说哪个版本好用. 第一次阅读vllm源码是0.4.0版本,对这版圈复杂度极高的调度代码印象深刻 0.4.1对调度逻辑进行重构,完全大变样, 读代码速度快赶不上迭代的速度了。 现在已经更新到0.5.4, 经过长时间观察,发现主要的调度逻辑基本也稳定了下来, 应该可以作为一个固话的版本去阅读。 本文解读依据vllm 0.5.4版本. 没有修改任

开源模型应用落地-LlamaIndex学习之旅-LLMs-集成vLLM(二)
一、前言 在这个充满创新与挑战的时代,人工智能正以前所未有的速度改变着我们的学习和生活方式。LlamaIndex 作为一款先进的人工智能技术,它以其卓越的性能和创新的功能,为学习者带来前所未有的机遇。我们将带你逐步探索 LlamaIndex 的强大功能,从快速整合海量知识资源,到智能生成个性化的学习路径;从精准分析复杂的文本内容,到与用户进行深度互动交流。通过丰富的实例展示和详细的操作指

vllm 部署GLM4模型进行 Zero-Shot 文本分类实验,让大模型给出分类原因,准确率可提高6%
文章目录 简介数据集实验设置数据集转换模型推理评估 简介 本文记录了使用 vllm 部署 GLM4-9B-Chat 模型进行 Zero-Shot 文本分类的实验过程与结果。通过对 AG_News 数据集的测试,研究发现大模型在直接进行分类时的准确率为 77%。然而,让模型给出分类原因描述(reason)后,准确率显著提升至 83%,提升幅度达 6%。这一结果验证了引入 reas
![[大模型]Qwen2-7B-Instruct vLLM 部署调用](https://img-blog.csdnimg.cn/direct/985ad267d2374ca98788a2ad8842f747.png#pic_center)
[大模型]Qwen2-7B-Instruct vLLM 部署调用
vLLM 简介 vLLM 框架是一个高效的大语言模型推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。易用性:vLLM 与 HuggingFace 模型无缝集成,支持多
GLM+vLLM 部署调用
GLM+vLLM 部署调用 vLLM 简介 vLLM 框架是一个高效的大型语言模型(LLM)推理和部署服务系统,具备以下特性: 高效的内存管理:通过 PagedAttention 算法,vLLM 实现了对 KV 缓存的高效管理,减少了内存浪费,优化了模型的运行效率。高吞吐量:vLLM 支持异步处理和连续批处理请求,显著提高了模型推理的吞吐量,加速了文本生成和处理速度。易用性:vLLM 与 H
GLM-4-9B VLLM 推理使用;openai接口调用、requests调用
参考: https://huggingface.co/THUDM/glm-4-9b-chat 直接运行vllm后端服务: from transformers import AutoTokenizerfrom vllm import LLM, SamplingParams# GLM-4-9B-Chat-1M# max_model_len, tp_size
vllm 使用FP8运行模型
简介 vLLM 支持使用硬件加速在 GPU 上进行 FP8(8 位浮点)计算,例如 Nvidia H100 和 AMD MI300x。目前,仅支持 Hopper 和 Ada Lovelace GPU。使用 FP8 对模型进行量化可以将模型内存需求减少 2 倍,并在对准确性影响极小的情况下将吞吐量提高最多 1.6 倍。 FP8 类型有两种不同的表示形式,每种形式在不同场景中都有用: E4M3:
开源模型应用落地-Qwen2-7B-Instruct与vllm实现推理加速的正确姿势(十)
一、前言 目前,大语言模型已升级至Qwen2版本。无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训练,并通过高质量数据进行后期微调以贴近人类偏好。在本篇学习中,将集成vllm实现模型推理加速,现在,我们赶紧跟上技术发展的脚步,去体验一下新版本模型的推理质量。 二、术语 2.1. vLLM vLLM是一个开源的大模型推理加速框架,通过PagedAtte

Qwen等大模型使用 vLLM部署详解
部署Qwen时尝试使用 vLLM。易于使用且具有最先进的服务吞吐量、高效的注意力键值内存管理(通过PagedAttention实现)、连续批处理输入请求、优化的CUDA内核等功能。 参考链接https://qwen.readthedocs.io/zh-cn/latest/deployment/vllm.html 1 vLLM离线推理代码 Qwen2代码支持的模型都被vLLM所支持。 vLLM最
视觉大模型(VLLM)学习笔记
视觉多模态大模型(VLLM) InternVL 1.5 近日,上海人工智能实验室 OpenGVLab 团队、清华大学、商汤科技合作推出了开源多模态大语言模型项目InternVL 1.5,它不仅挑战了商业模型巨头例如 GPT-4V 的霸主地位,还让我们不禁思考:开源力量能走多远? 比肩 GPT-4V ! 开源的视觉语言模型 InternVL 1.5! 开源地址: GitHu

qwen2 vllm推理部署;openai接口调用、requests调用
参考: https://qwenlm.github.io/zh/blog/qwen2/ 下载 https://huggingface.co/Qwen 下载的Qwen2-7B-Instruct使用: export HF_ENDPOINT=https://hf-mirror.comhuggingface-cli download --resume-download --local-dir-u
vllm lora、gptq、awq推理使用
1)lora推理 docker run --gpus all -v /ai/Qwen1.5-7B-Chat:/qwen-7b -v /ai/lora:/lora -p 10860:10860 --ipc
『大模型笔记』使用 vLLM 和 PagedAttention 快速提供 LLM 服务!
使用 vLLM 和 PagedAttention 快速提供 LLM 服务! 文章目录 一. 使用 vLLM 和 PagedAttention 快速提供 LLM 服务!1.1. PagedAttention 二. 参考文献 小红书中文字幕视频:https://www.xiaohongshu.com/explore/66502b60000000000500433e官网文档(推荐
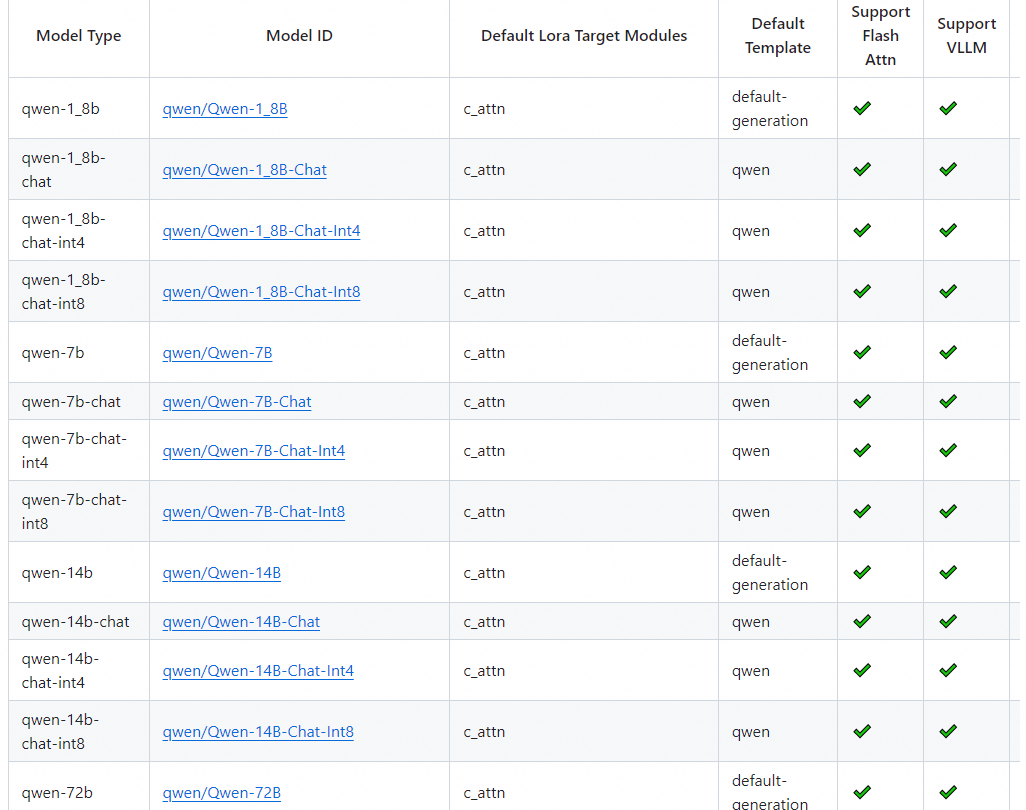
LLM 大模型学习必知必会系列(十三):基于SWIFT的VLLM推理加速与部署实战
LLM 大模型学习必知必会系列(十三):基于SWIFT的VLLM推理加速与部署实战 1.环境准备 GPU设备: A10, 3090, V100, A100均可. #设置pip全局镜像 (加速下载)pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/#安装ms-swiftpip install

AI整体架构设计6:vLLM
训练大型语言模型以及微调的教程比比皆是,但关于在生产环境中部署它们并监控其活动的资料相对稀缺。上个章节提到了未来云原生的AI是趋势,然而涉及到云原生会比较偏技术。而在此之前为了解决大模型部署量产的问题,社区也一直在探索,目前已经有不少的工具可用于这个领域。 今天挑选几个颇具特色的主流部署工具来谈谈,例如vLLM、LLAMA.cpp 和TGI等工具,它们各自都提供各自的部署模式,本文对于数据分析师
![LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]](https://img-blog.csdnimg.cn/img_convert/b10128f1222cfef40c49ec90fbdfded4.png)
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架] 训练后的模型会用于推理或者部署。推理即使用模型用输入获得输出的过程,部署是将模型发布到恒定运行的环境中推理的过程。一般来说,LLM的推理可以直接使用PyTorch代码、使用VLLM/XInference/FastChat等框架,也可以使用l
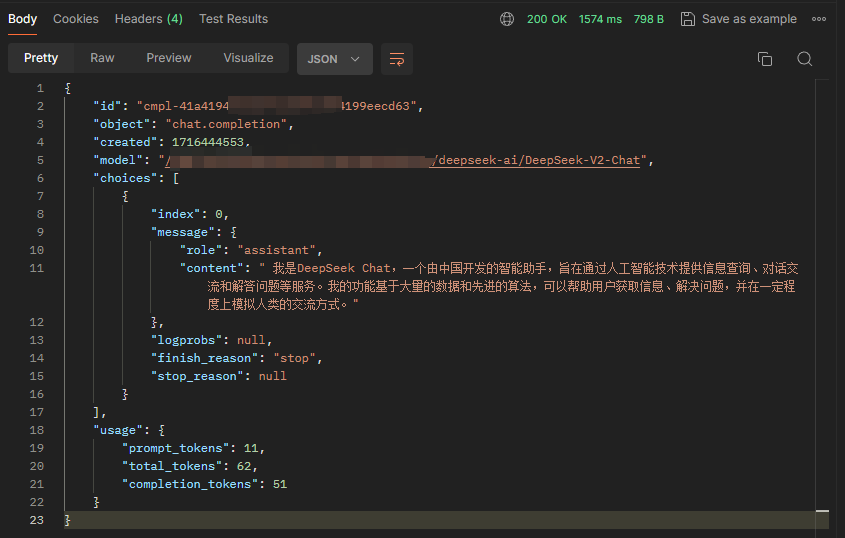
基于 vLLM 搭建 DeepSeek-V2 Chat 服务
直奔主题。 安装vLLM 官方实现的代码还没有 merge 到 vLLM 主分支,所以直接 git clone DeepSeek 的分支。 git clone https://github.com/zwd003/vllm.gitcd vllmpip install -e . 源码安装大概耗时 10 分钟。 OpenAI 接口规范启动 官方 Github 放的是单条推理代码,如果需

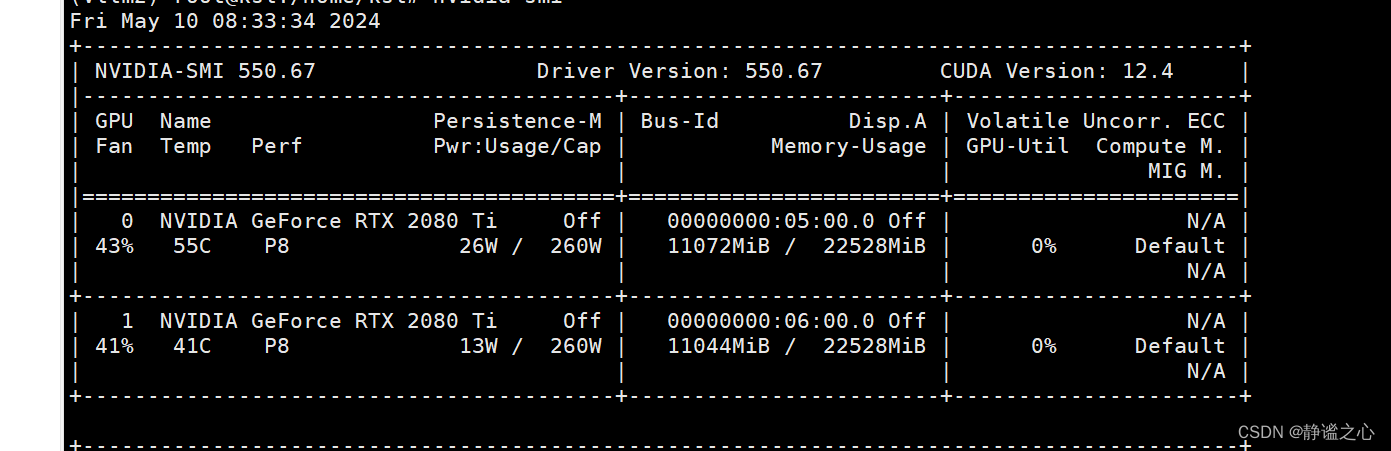
Fastchat + vllm + ray + Qwen1.5-7b 在2080ti 双卡上 实现多卡推理加速
首先先搞清各主要组件的名称与作用: FastChat FastChat框架是一个训练、部署和评估大模型的开源平台,其核心特点是: 提供SOTA模型的训练和评估代码 提供分布式多模型部署框架 + WebUI + OpenAI API Controller管理分布式模型实例 Model Worker是大模型服务实例,它在启动时向Controller注册 OpenAI API提供OpenAI兼容的A

开源模型应用落地-LangChain高阶-集成vllm-QWen1.5-OpenAI-Compatible Server(三)
一、前言 通过langchain框架调用本地模型,使得用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。vLLM可以部署为类似于OpenAI API协议的服务器,允许用户使用OpenAI API进行模型推理。 相关文章: 开源模型应用落地-LangChain试炼-CPU调用QWen1.5(一) 开源模型应用落地-LangChain高阶-GPU调用
开源模型应用落地-LangChain高阶-集成vllm-QWen1.5(一)
一、前言 通过langchain框架调用本地模型,使得用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。vLLM是一个快速且易于使用的LLM推理和服务库。通过两者的结合,可以更好地处理对话,提供更智能、更准确的响应,从而提高对话系统的性能和用户体验。 二、术语 2.1.LangChain 是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangCha
使用SFT和VLLM微调和部署Llama3-8b模型
目录 1. 环境安装2. accelerator准备3. 加载llama3和数据4. 训练参数配置5. 微调6. vllm部署7. Llama-3-8b-instruct的使用参考 1. 环境安装 pip install -q -U bitsandbytespip install -q -U git+https://github.com/huggingface/transfor
llama-factory SFT 系列教程 (四),lora sft 微调后,使用vllm加速推理
文章目录 文章列表:背景简介llama-factory vllm API 部署融合 lora 模型权重 vllm API 部署HuggingFace API 部署推理API 部署总结 vllm 不使用 API 部署,直接推理数据集 tenplatevllm 代码部署 文章列表: llama-factory SFT系列教程 (一),大模型 API 部署与使用llama-fact
使用 vllm 运行 Llama3-8b-Instruct
使用 vllm 运行 Llama3-8b-Instruct 0. 引言1. 安装 vllm2. 运行 Llama3-8b-Instruct 0. 引言 此文章主要介绍使用 vllm 运行 Llama3-8b。 1. 安装 vllm 创建虚拟环境, conda create -n myvllm python=3.11 -yconda activate myvllm 安装
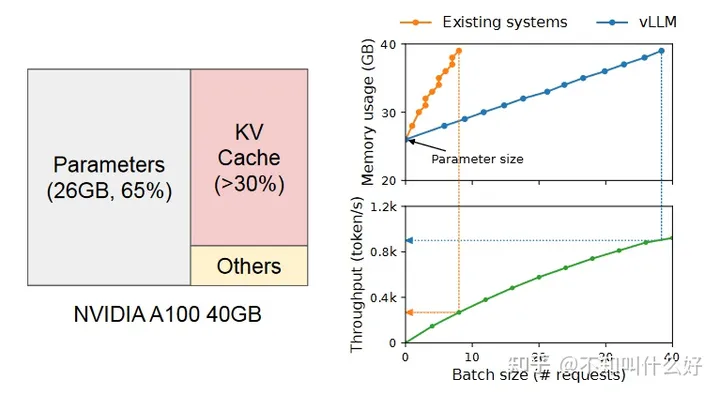
vLLM-prefix浅析(System Prompt,大模型推理加速)
原文:vLLM-prefix浅析(System Prompt,大模型推理加速) 简介 本文浅析了在大模型推理加速方面一个非常优秀的项目 vLLM 的一个新特性 Prefix。在 Prompt 中有相同前缀时可以提高吞吐量降低延迟,换句话说可以省去这部分相同前缀在自注意力阶段的重复计算。 更新 2024.1.18:Prefix 已经合并到主分支上了!如果你的 vLLM 不能使用也许是时候升级一