本文主要是介绍AI整体架构设计6:vLLM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
训练大型语言模型以及微调的教程比比皆是,但关于在生产环境中部署它们并监控其活动的资料相对稀缺。上个章节提到了未来云原生的AI是趋势,然而涉及到云原生会比较偏技术。而在此之前为了解决大模型部署量产的问题,社区也一直在探索,目前已经有不少的工具可用于这个领域。
今天挑选几个颇具特色的主流部署工具来谈谈,例如vLLM、LLAMA.cpp 和TGI等工具,它们各自都提供各自的部署模式,本文对于数据分析师乃至数据科学家,还是刚接触AI部署的新兵,相信可以为读者打开一扇窗户进行快速的了解。

vLLM
LLM具有大量参数来执行预测,可能从3B参数量开始,然后增加到 300B,因此部署该模型需要大量资源和大量的优化工作以便于提高整体的负载,当然不是使用传统方法部署机器学习模型。
该项目来自加州大学伯克利分校的研究团队,它们对优化LLM的服务性能有着浓厚的兴趣,重点研究如何高效简洁的解决大模型的部署问题。vLLM采用了一种新的方法来解决这个问题,即巧妙的利用操作系统的虚拟内存,这种设计与传统方法相比,这可以将LLM的服务性能提高约24倍,同时仅使用GPU内存的一半。
至于如何集成,vLLM提供了一个简单的接口,让工程师可以便捷的使用Python进行开发,而无需花哨的依赖包即可将其集成。
vLLM的几项关键技术:
-
PagedAttention:核心创新,这是一种新颖的注意力机制,通过分块处理注意力键和值而不是一次性处理,当然可以配合FlashAttention协同工作。
使用 PagedAttention 将输入文本分页,生成多个较小的“页”。在每一页内,应用 FlashAttention 进行高效的注意力计算。PagedAttention 处理跨页的信息传递和聚合,减少了 KV 缓存的碎片化,确保模型能够理解跨页的全局上下文信息。FlashAttention 的高效计算方法则确保了在每一页内的计算过程快速且内存使用高效。
-
张量并行支持:vLLM支持张量并行,将模型拆分到多个GPU上进行训练和推理的技术。
-
易用且能立即投产:vLLM使模型部署变得非常容易,并且涵盖了实际生产中的大多数用例。计算指标以跟踪性能也很容易。
-
广泛的模型支持:虽然添加一种的新模型可能会相当困难,但目前支持许多架构。
-
量化和Lora支持:vLLM支持各种量化技术,如GPTQ、AWQ和 SqueezeLLM,这些技术可以非常轻松地推出,并大大优化速度和内存占用。
-
连续批处理:批处理的大小可以动态设定,因此可应付各种负载场景。

注意力机制的计算瓶颈
目前的大模型都是基于注意力机制,它的运算则成为计算瓶颈,需要耗费大量的计算资源和计算内存。之前曾经完整的介绍了FlashAttentionv1和FlashAttentionv2也是在于如何优化注意力机制的运算效率。

而在推理侧,解码器领域还有围绕着注意力机制的KV Cache优化,由于解码器是因果(即某个Token的注意力仅取决于其前面的Token),因此在每个生成步骤中都在重新计算相同的先前标记的注意力,而实际上只需要计算新标记的注意力即可。
这里就是KV Cache发挥作用的地方,通过缓存以前的Keys和Values就可以专注于计算新token的注意力。下图为一个例子,当第三个Token进来的时候可以利用缓存中的数据(紫色的数据块)。

值得注意的是这种机制需要更多的GPU HBM(若不使用GPU,则需要 CPU RAM)来缓存Key和Value的状态。

然而每个请求的KV Cache(KV缓存)内存占用巨大,且会动态增长和缩减。若管理不当,这些内存会因碎片化和冗余重复而被大量浪费,从而限制批处理的大小。

PagedAttention
vLLM研发了一种名为PagedAttention的新注意力算法,该算法的灵感来自悠久的操作系统虚拟内存和分页技术。在此算法的基础上,vLLM实现了(1)KV缓存内存几乎零浪费,(2)在大模型量产过程中的服务请求之间实现灵活的KV缓存共享,从而达到节省内存的开销。

通过以后的实验进行评估,与最先进的系统(如FasterTransformer和Orca)相比,vLLM在相同延迟水平下,将流行LLM的吞吐量提高了2-4倍。对于更长序列、更大模型和更复杂的解码算法,改进更加显著。
PagedAttention是vLLM性能提升的核心,通过将KV缓存划分为块,允许在内存中不连续地存储键和值,解决了LLM 服务中内存管理的关键问题。这种方法不仅可以优化内存使用,减少高达96%的浪费,还可以实现高效的内存共享,大大降低复杂采样算法的内存开销。
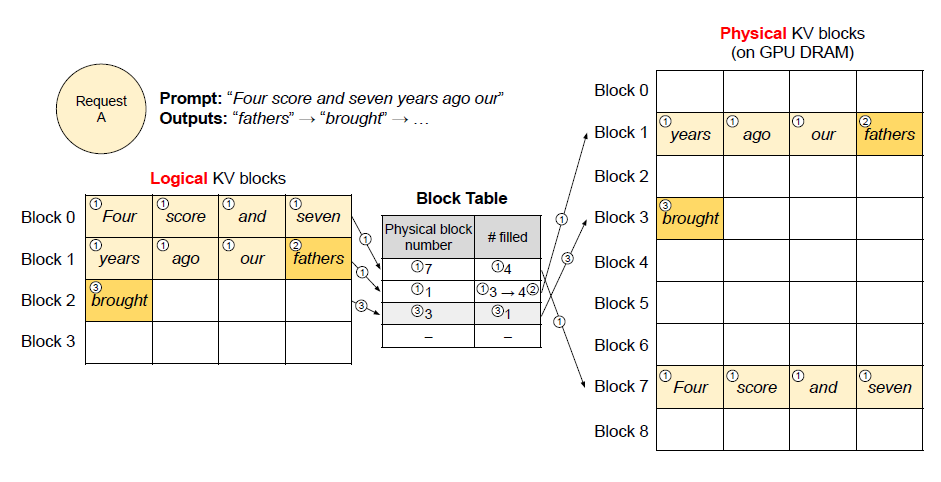
计算中使用到的虚拟块会被映射到实际的物理块

多个请求同时进行,每个请求都会拥有自己的物理块

若在一次的请求中需要多次抽样,那么只需要简单的复制物理块即可。

vLLM架构
vLLM的架构如下图所示,它利用集中调度器采用分布式的方法协调GPU集群的工作执行。KV缓存管理器通过PagedAttention以分页方式有效地管理KV缓存。具体来说,KV缓存管理器通过集中调度器发送的指令来管理GPU Worker的物理KV缓存。

换句大白话,vllm通过合理且高效的内存管理实现了大模型在推理侧的性能提升。

性能对比
下面有研究人员演示通过vLLM提供LLM服务,GPU卡为A100 40g,用于使用Llama-2–13b-hf-chat进行测试。为了测试vLLM和Hugging Face之间的内存使用情况, 此示例将测试一个示例请求,然后监视GPU 使用情况。这表明 GPU 内存即将耗尽,因此Hugging Face比vLLM使用的CPU内存更多,这导致由于预留而导致GPU内存泄漏。

上图为vLLM,下图为HuaggingFace

这篇关于AI整体架构设计6:vLLM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








