本文主要是介绍vllm引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
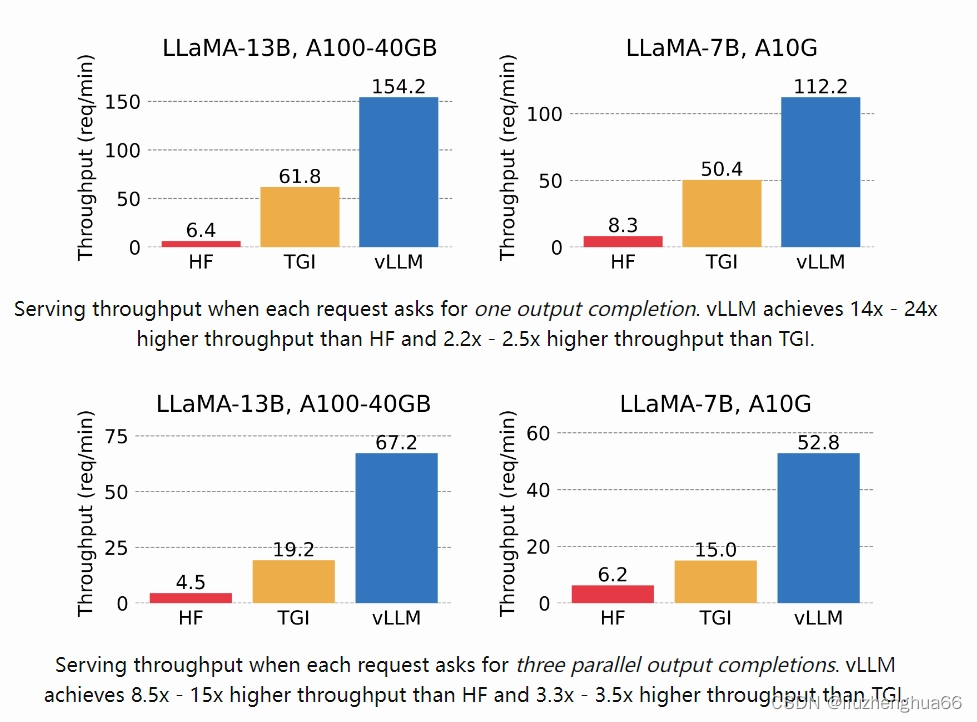
LLM有望从根本上改变我们在所有行业使用人工智能的方式。然而,部署这些模型具有挑战性,即使在昂贵的硬件上,速度也可能出奇地慢。 vLLM`是一个用于快速 LLM 推理和服务的开源库。 vLLM 利用PagedAttention,一个新的注意力算法,可以有效管理注意力键和值。配备 PagedAttention 的 vLLM 重新定义了 LLM 服务的最新技术水平:它的吞吐量比 HuggingFace Transformers 高出 24 倍,且无需更改任何模型架构。
PagedAttention
LLM服务性能的瓶颈点主要在GPU显存上,在自回归解码过程中,LLM中所有的输入token都会生成代表他们注意力key和value张量,这些张量一直存储在GPU显存中用来生成下一个token,这些被缓存的key和value通常被称为KV Cache,巨有以下特性:
- 占用空间大:LLaMA-13B中单个序列最大占用的显存为1.7GB
- 动态分配空间:序列大小是动态创建的,由于序列长度变化很大切不可预测,实际创建过程中由于系统碎片和预留等原因浪费了60%-80%的显存。
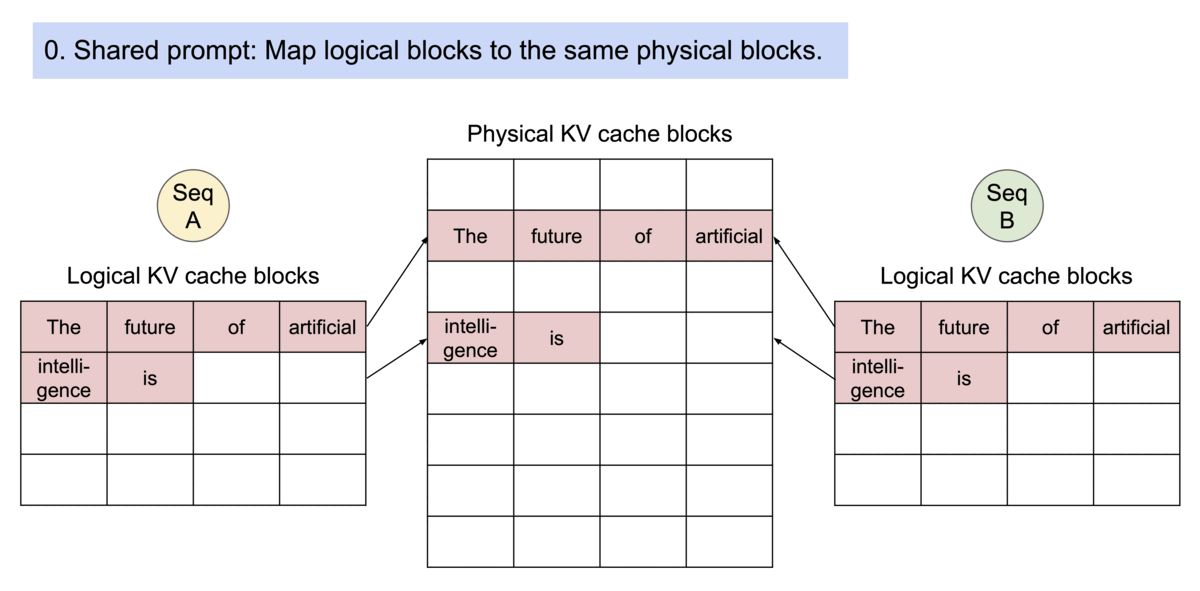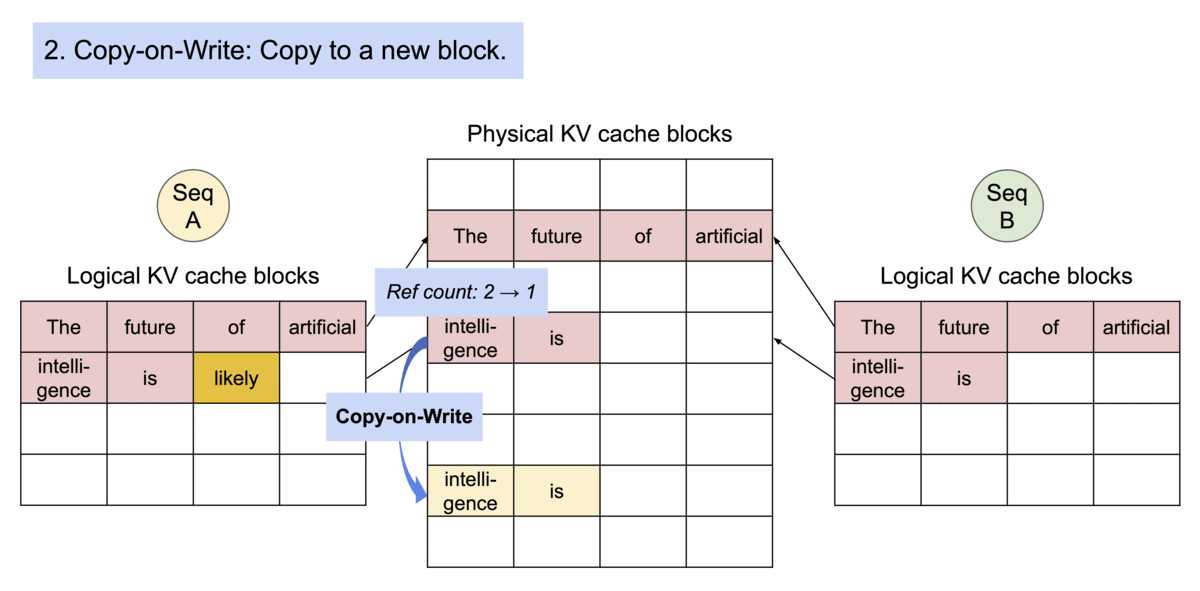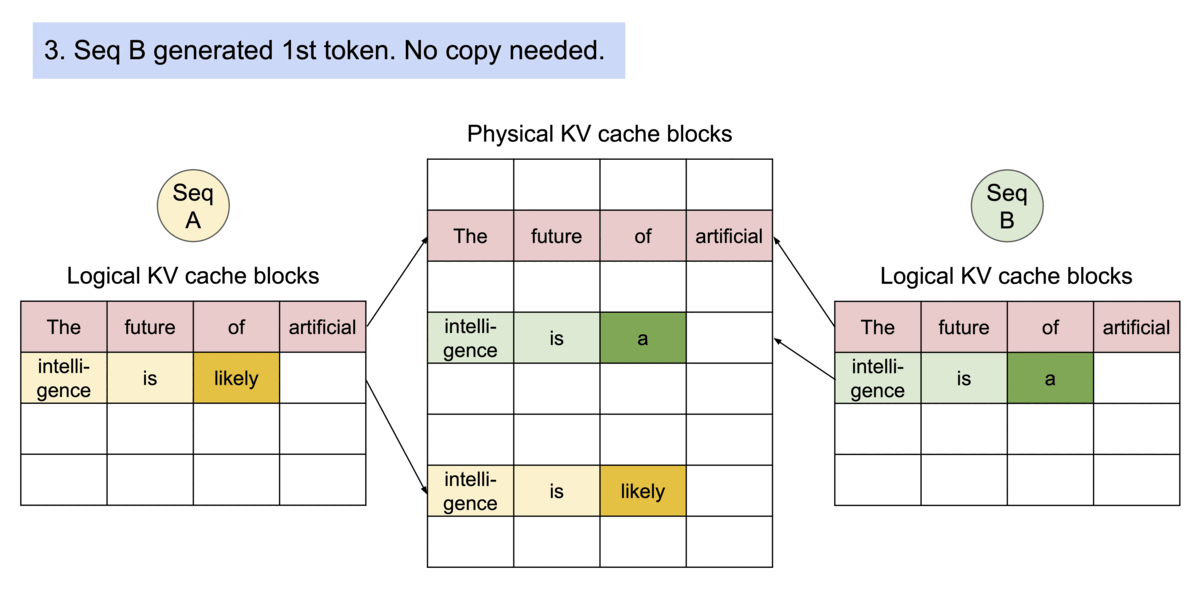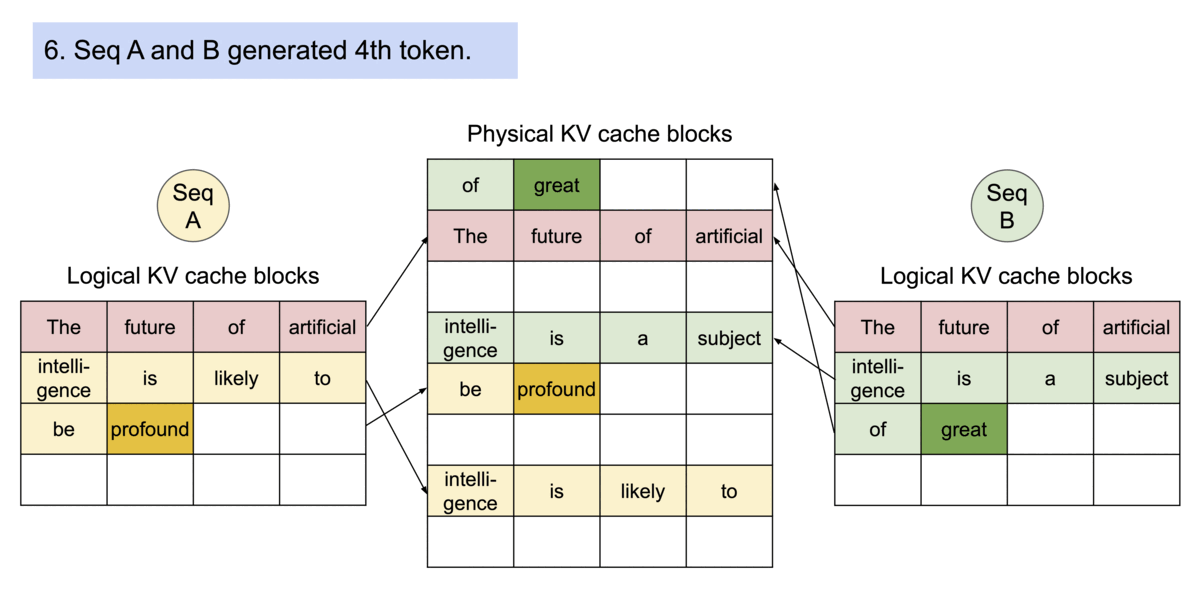
PagedAttention是一种受操作系统中虚拟内存和分页的经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在不连续的内存空间中存储连续的键和值。它将KV Cache划分成块,每个块包含固定数量的tokens对应的key和value张量,在注意力计算过程中,PagedAttention内核可以高效地识别并获取到这些块。可以将块看作为操作系统虚拟内存的page,tokens看作为字节,sequences看作为进程。逻辑层面上连续的序列通过block table映射到非连续的物理块中。物理块在新token被创建的时候按需被创建。
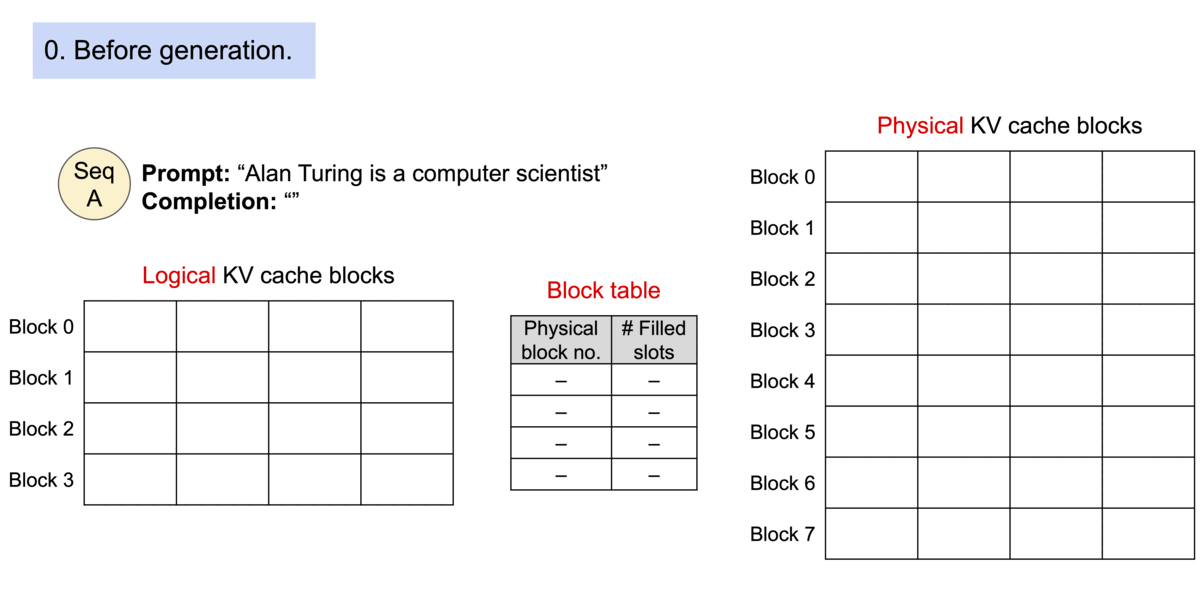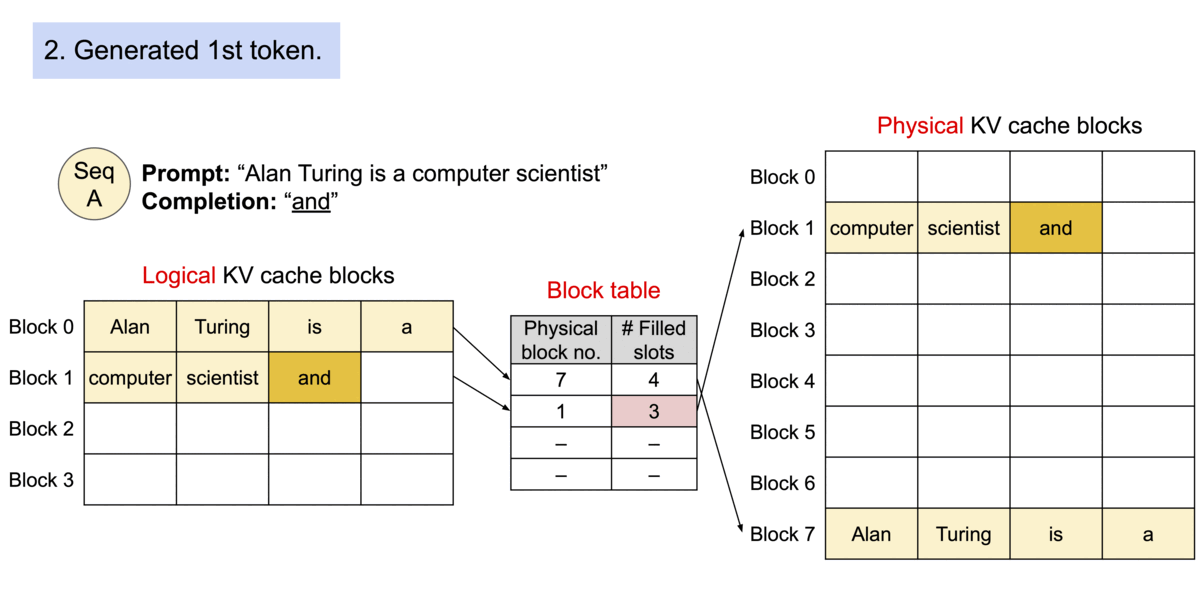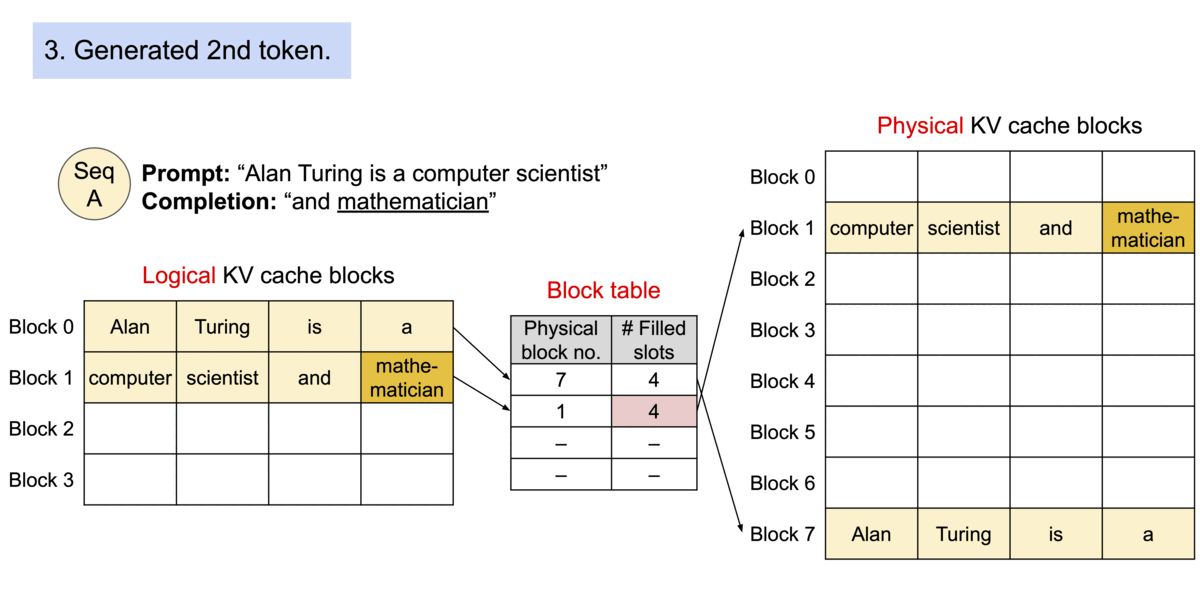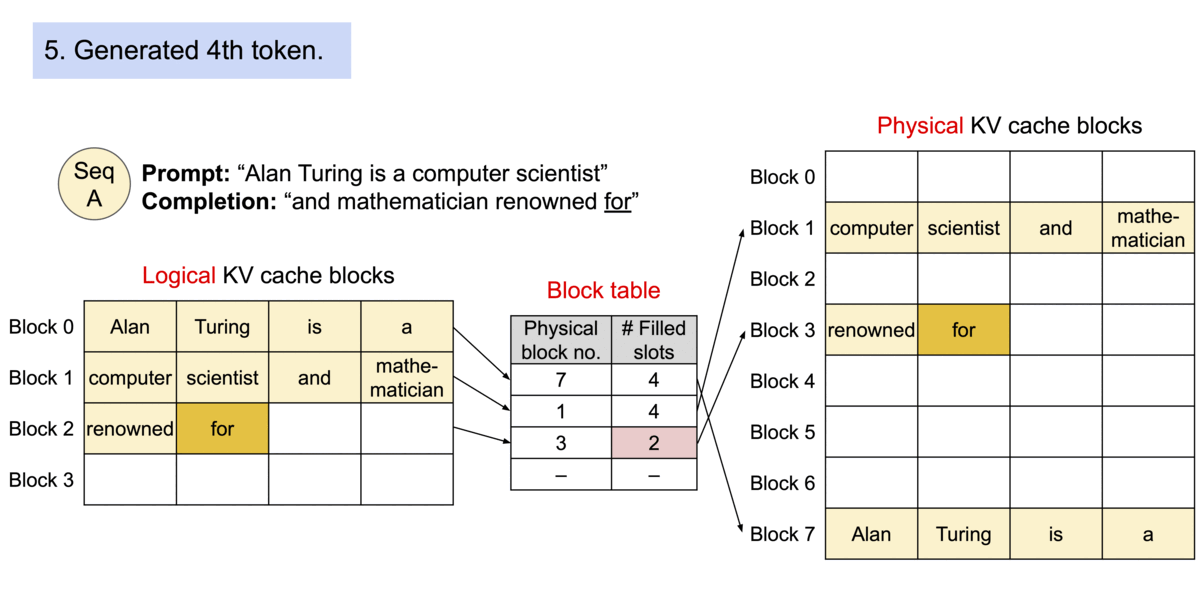
PagedAttention算法显存利用率特别高,它只是浪费了序列使用的最后一个block。内存利用率的提高允许系统可以同时处理更多的序列,提升了GPU利用率和吞吐量。
PagedAttention会在block table进行共享,多个sequence中用到的相同的块部分会被共享,并维持一个引用计数。需要修改块内容的时候,则会对refCount > 1的块进行CopyOnWrite的策略。
安装与使用
安装
pip install vllm
配置
# 默认使用Hugging face下载模型
export VLLM_USE_MODELSCOPE=True
# 开启API鉴权
export VLLM_API_KEY=xx
启动
离线推理
from vllm import LLM, SamplingParams# 定义输入的prompt和采样参数
prompts = ["Hello, my name is","The president of the United States is","The capital of France is","The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)# 初始化模型
llm = LLM(model="facebook/opt-125m")# 推理
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
兼容OpenAI接口的http服务
https://docs.vllm.ai/en/latest/models/engine_args.html#
https://vllm.readthedocs.io/_/downloads/en/stable/pdf/
# --api-key x 开启API鉴权服务
# --model <model_name_or_path>
# --max-model-len <length>
# --gpu-memory-utilization <fraction> 默认只0.9 GPU利用率
# --revision <revision>
# --host 监听的地址
# --port 监听的端口 默认8000
python -m vllm.entrypoints.openai.api_server \
--model facebook/opt-125m# 几张卡--tensor-parallel-size就指定几,目前qwen14b awq模式不支持多卡部署
export VLLM_USE_MODELSCOPE=True
python -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 8000 --model qwen/Qwen1.5-14B-Chat-GPTQ-Int4 --quantization gptq --block-size 16 --swap-space 4 --gpu-memory-utilization 0.9 --tensor-parallel-size 1 --max-model-len 8192 --enforce-eager调用
models
curl http://localhost:8000/v1/models
Completion
curl
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "facebook/opt-125m",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
python
from openai import OpenAI# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)
completion = client.completions.create(model="facebook/opt-125m",prompt="San Francisco is a")
print("Completion result:", completion)
ChatCompletion
curl
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "facebook/opt-125m","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Who won the world series in 2020?"}]
}'
python
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model="facebook/opt-125m",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Tell me a joke."},]
)
print("Chat response:", chat_response)
参考文献
https://blog.vllm.ai/2023/06/20/vllm.html
这篇关于vllm引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









