本文主要是介绍微软Phi-3,3.8亿参数能与Mixtral 8x7B和GPT-3.5相媲美,量化后还可直接在IPhone中运行,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Phi-3系列
Phi-3是一系列先进的语言模型,专注于在保持足够紧凑以便在移动设备上部署的同时,实现高性能。Phi-3系列包括不同大小的模型:
- Phi-3-mini(38亿参数) - 该模型在3.3万亿个令牌上进行训练,设计得足够小,可以在现代智能手机上运行。尽管体积紧凑,它的性能却可与更大的模型如Mixtral 8x7B和GPT-3.5相媲美,例如在MMLU基准测试中达到69%,在MT-bench上得分为8.38。
- Phi-3-small(70亿参数)和Phi-3-medium(140亿参数) - 这些是Phi-3系列中较大的版本,在相同类型的数据上训练,但令牌数更多(4.8万亿),表现更佳。例如,Phi-3-small和Phi-3-medium在相同基准测试中的得分高于Phi-3-mini。
Phi-3模型的开发涉及使用经过严格过滤的网络数据和合成数据训练模型,使它们能够执行通常预期的大型模型任务。这种策略使Phi-3系列能够利用更小、更高效的模型,而不牺牲功能,使其能够直接在智能手机上运行。
Phi-3模型的重要性在于它们能够将强大的AI能力带到移动设备上,允许运行完全本地的强大AI应用,无需持续的互联网连接。这种进步可能导致广泛的设备上应用,增强用户隐私并减少AI驱动任务的延迟。

Phi-3训练方法
Phi-3模型的训练方法,尤其是Phi-3-mini,详细记录在技术报告中,包括几个旨在优化性能同时保持适合移动设备部署的紧凑模型大小的策略步骤。以下是Phi-3训练方法的关键元素:
- 数据选择和策展:Phi-3模型使用精心策划的数据集,包括经过严格过滤的网络数据和由大型语言模型(LLMs)生成的合成数据。这个数据集是Phi-2使用的数据的扩展版本,注重质量和相关性,以提高小型模型的学习效率。
- 数据最优化方案:与可能优先考虑计算最优或过度训练的传统方法不同,Phi-3训练强调“数据最优”方案。这里的重点是训练数据的质量和校准,以确保它与模型的规模相匹配。选择的数据旨在增强模型的推理能力,而不仅仅是增加信息量。
- 模型架构:Phi-3-mini采用了优化的变压器解码器架构,适用于默认(4K上下文长度)和扩展上下文(通过Phi-3-mini-128K中的LongRope机制将上下文长度扩展到128K)。这种灵活性使模型能够处理从简单查询到需要更深上下文的复杂对话的各种任务。
- 训练效率:模型使用bfloat16浮点格式进行训练,平衡了计算效率和数值精度。这种方法有助于有效管理计算资源,尤其是对于计划在处理能力有限的设备上运行的模型,如手机。
- 阶段训练:Phi-3的训练涉及两个连续阶段,第一阶段主要包括从网络来源中获得的一般知识和语言理解,第二阶段结合更严格过滤的网络数据和合成数据,教授模型高级推理和细分技能。
- 训练后增强:在初步训练后,Phi-3模型进行了包括监督指导微调和偏好调整在内的后训练调整。这些步骤对于改进模型在聊天功能、安全性和稳健性方面的能力至关重要。
这些训练策略共同使Phi-3模型在较少的参数下实现了高性能,使其适合本地化的设备上应用,如智能手机上。这种方法代表了向创建更高效但功能强大的AI工具迈进的重大转变,这些工具利用了先进的数据策展和训练技术。
Phi-3性能基准
Phi-3系列,特别是Phi-3-mini,在各种基准测试中展示了与更大模型如GPT-3.5和Mixtral 8x7B相竞争的性能。在MMLU基准测试中,Phi-3-mini得分为68.8%,紧随GPT-3.5的71.4%之后,超过了Mixtral 8x7B的68.4%。在HellaSwag测试中,Phi-3-mini达到76.7%,几乎与GPT-3.5的78.8%持平,并超过了得分为70.4%的Mixtral 8x7B。在ANLI测试中,Phi-3-mini记录了52.8%,略低于GPT-3.5的58.1%和Mixtral 8x7B的55.2%。Phi-3-small和Phi-3-medium展示了更进一步的改进;例如,Phi-3-small在MMLU中达到了75.3%,超过了GPT-3.5和Mixtral 8x7B。同样,在HellaSwag中,Phi-3-medium的得分为83.0%,显著地超过了其他模型。这些基准测试强调了Phi-3模型能够提供的强大性能,与或超过了许多更大的模型,突显了它们的训练方法和使用策划数据集的有效性。这种能力使得Phi-3能够在移动设备上提供强大的AI功能,与行业领先的模型紧密对齐,同时保持更小、更高效的足迹。

在iPhone上运行
Phi-3-mini模型特别设计为足够紧凑和高效,可以在现代智能手机上运行,包括配备A16仿生芯片的iPhone 14。此模型针对移动设备的限制进行了优化,同时仍提供强大的AI能力。它能够以4位量化版本运行,大约占用1.8GB的内存,这有助于其在不显著影响设备存储容量的情况下在智能手机上部署。
考虑到新型iPhone模型通常配备更先进的处理器和更大的内存容量,可以合理预期Phi-3-mini在iPhone 15上的表现将同样好或更佳。这将可能利用任何CPU和GPU能力的提升,以及可能进一步优化AI应用性能的能源效率改进。
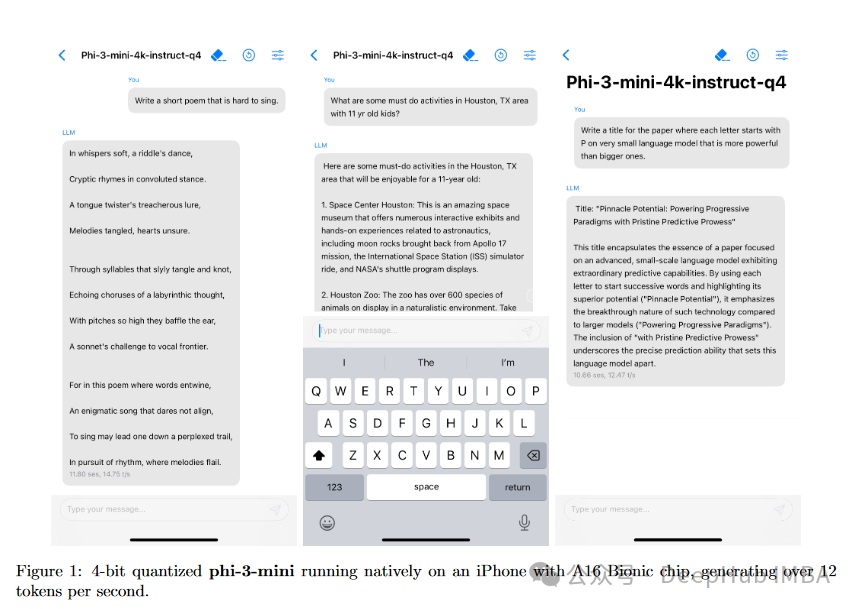
总结
Phi-3系列,尤其是Phi-3-mini模型,代表了语言模型领域的一大进步,证明了高级AI能力可以在移动设备上有效实施。这一系列模型,包括Phi-3-mini、Phi-3-small和Phi-3-medium,在一系列基准测试中展示了令人印象深刻的性能,与甚至有时超越了GPT-3.5和Mixtral 8x7B等较大的模型。其性能的关键在于使用经过精心策划的训练数据集的创新使用,该数据集结合了经过严格过滤的网络数据和合成数据,使这些较小的模型能够实现高效率和高效能。
Phi-3-mini在智能手机上的部署,例如iPhone 14,使用仅需约1.8GB内存的量化版本,展示了强大AI在高度便携格式中的实际应用。这种能力为设备上的AI应用开辟了新的可能性,增强了用户隐私和功能性,无需持续的互联网连接。总的来说,微软的Phi-3计划推动了移动设备上AI可能性的界限,使其成为AI技术普及的一个关键发展,确保了更广泛的访问和实用性。
目前,微软只发布了Phi-3的技术报告,尚未开放源代码和权重下载。源代码和权重将很快提供下载。
https://avoid.overfit.cn/post/993fe58451424742928c50999461ddf9
这篇关于微软Phi-3,3.8亿参数能与Mixtral 8x7B和GPT-3.5相媲美,量化后还可直接在IPhone中运行的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


