本文主要是介绍大话MoE混合专家模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MoE(Mixture of Experts),专家混合,就像是人工智能界的超级团队。想象一下,每个专家都有自己的拿手好戏,比如医疗问题找医生,汽车故障找机械师,做饭找大厨。MoE也是这样,它把难题拆分成小块,交给擅长处理特定问题的专家小组。这样一来,整个团队就能更高效、更精准地搞定各种复杂任务。就像是一群各有所长的专家联手,比单打独斗的通才解决问题的能力要强得多。
让我们看看下面的图表——我们很快就会解释它。
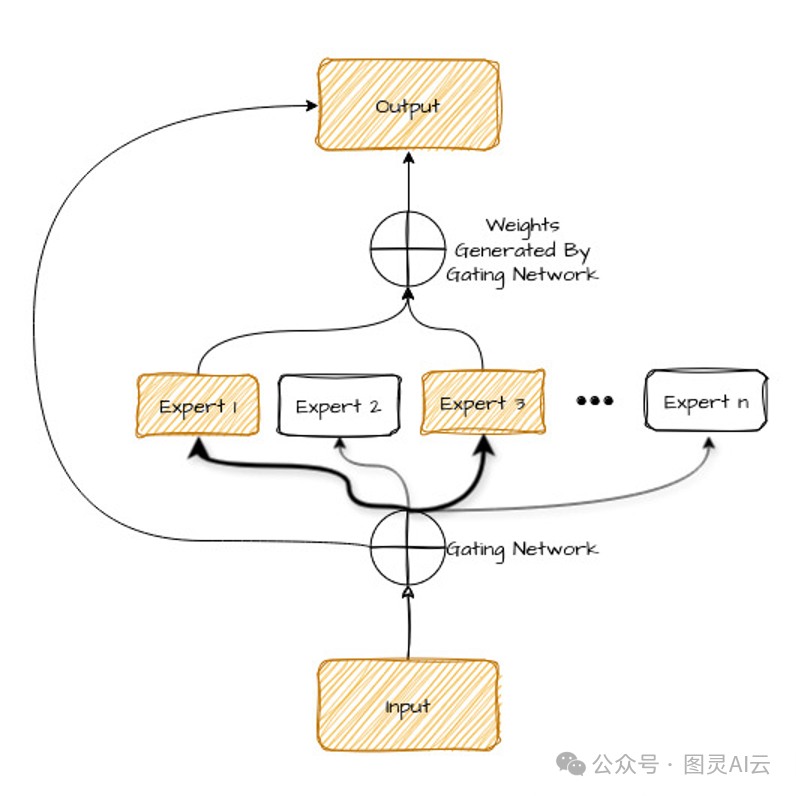
咱们来聊聊这张图里头的各个部件,就像咱们团队里分工一样:
-
输入:就是你想交给AI处理的那些问题或者数据。
-
专家:这些小家伙儿,每个都是AI模型,它们都经过特别训练,专门处理问题中的某一部分。就像你团队里不同领域的专家一样。
-
门控网络:它就像个团队经理,决定哪个专家最适合处理问题中的哪一块。它看看输入,然后决定谁该干什么。
-
输出:这就是AI模型在所有专家忙活完之后给出的答案或解决方案。
用MoE的好处嘛,有这么几个:
-
效率:只有那些擅长处理问题特定部分的专家会被用到,这样既省时间又省计算资源。
-
灵活性:你可以轻松地增加更多专家或者调整他们的专长,让系统能应对各种不同的问题。
-
更好的结果:因为每个专家都专注于自己的强项,所以整体的解决方案通常更精准,更可靠。
就像一个团队,每个人都发挥自己的长处,合作起来解决问题,效率杠杠的。
让我们通过专家网络和门控网络更详细地了解一下。
专家网络
MoE模型里的“专家网络”,咱们可以想象成一支各有所长的团队。不是让一个AI大包大揽所有活儿,而是每个专家只管自己最拿手的任务或数据。
这些专家,就好比是独立的神经网络,每个都专门训练来处理不同的数据集或任务。
它们的设计很巧妙,是稀疏的,也就是说,任何时候只有少数几个专家在忙活,这得看输入数据是什么。这样做的好处是,系统不会被海量任务压垮,还能保证最懂行的专家来解决问题。
那问题来了,模型怎么决定用哪些专家呢?这时候,门控网络就派上用场了。
门控网络
门控网络,咱们可以把它想象成一个智能的路由器,它的作用就是分析进来的数据,比如需要翻译的句子,然后决定哪些专家最适合处理这些数据。
它给每个专家打分,就像给它们分配权重一样,然后挑出得分最高的那些专家来处理数据。
门控网络选专家的方法有好几种,也就是我们说的“路由算法”,这里给你介绍几种常见的:
-
Top-k路由:这个方法最简单。门控网络就挑出亲和力最高的前'k'个专家,然后把数据发给他们处理。
-
专家选择路由:这个方法有点反过来,不是数据选专家,而是专家自己说“这个数据我最擅长处理”。这样可以让数据处理更平衡,也能让数据和专家的匹配更多样化。
-
稀疏路由:这个方法每次只激活几个专家来处理数据,形成一个稀疏的网络。相比起密集路由,每个数据点都要用到所有专家,稀疏路由就节省了不少计算资源。
在预测的时候,模型会把各个专家的结果综合起来,用的就是分配任务给专家的那个过程。有时候,一个任务可能需要不止一个专家,这得看任务有多复杂,或者问题有多多样。
这就是MoE模型的工作原理,听起来挺复杂的,但其实它就是让每个专家都发挥自己的长处,共同完成一个大任务。
MoE(专家混合)是如何工作的
MoE在两个阶段操作:
-
训练阶段
-
推理阶段
训练阶段
MoE模型的启动和大多数机器学习模型挺像的,都是从训练数据集开始。但训练的方法有点不同。MoE不是把整个模型拿来一锅炖,而是把它拆成几个小组件,然后分别对这些组件进行训练。
这样做的好处是,每个组件都能专注于学习数据集中的某一部分,就像是让每个成员都成为自己领域的专家。这样一来,当整个模型需要处理一个复杂任务时,这些训练有素的组件就能各司其职,发挥自己的专长,提高整个模型的效率和准确性。
在MoE模型里,专家训练就像是给每个队员分配特定的任务,让他们成为那个领域的高手。这个训练过程是这样的:
-
分配任务:首先,我们得给MoE框架里的每个组件指派一个特定的任务或问题领域。比如,如果我们在处理语言,一个组件可能专门研究语法,另一个可能专门研究语义。
-
提供数据:接下来,我们给每个组件提供与它任务相关的数据。这样做可以确保每个组件都能在它需要专注的领域里得到充分的练习。
-
标准训练:每个组件的训练过程都遵循标准的神经网络训练方法。这意味着,每个组件都会尝试学习如何最好地处理它得到的数据,目标是减少错误,也就是最小化损失函数。
通过这样的训练,每个组件都能成为它所负责领域的小能手,当它们集合起来,就能共同解决更广泛的问题了。
门控网络训练
门控网络,就像MoE模型里的指挥官,它的工作是学会怎么给每个进来的任务分配最合适的专家。
在训练门控网络的时候,它是和那些专家网络一起练的。门控网络会收到和专家网络一样的数据输入,然后它要学会预测一个概率分布,这个分布能告诉我们哪个专家最有可能把当前的任务做得最好。
训练门控网络的时候,我们不仅看它选专家选得准不准,还得看它选的专家干活干得怎么样。所以,我们会用一种优化方法,这个方法既考虑门控网络的准确性,也考虑它选的专家的表现。
简单来说,门控网络就像是个智能的调度员,它得学会怎么把任务分配给最擅长的专家,确保整个团队的效率和效果都达到最佳。
联合训练
到了联合训练阶段,MoE模型里的所有成员,包括那些专家模型和门控网络,都要一起上阵,共同训练。
这么做的好处是,能让门控网络和专家们像一支默契的队伍一样协同工作。在这个阶段,我们用一个特殊的损失函数,它不仅考虑了每个专家的表现,也把门控网络的准确性算进去了。这样一来,大家就能朝着一个共同的目标努力,互相配合,互相促进。
训练过程中,损失函数产生的梯度会在整个系统里流动,就像是给团队的每个成员发出信号,告诉他们怎么调整自己,以便整个系统的表现能够更上一层楼。
简单来说,联合训练就像是团队的集体训练,让每个人都能更好地了解自己的角色,同时也学会如何和队友们更有效地协作。这样,当他们一起面对挑战时,就能发挥出团队的最大潜力。
推理阶段
推理阶段,MoE模型就像是一个精打细算的策划者,它的目标是用最少的资源做出最好的决策。
-
输入路由:首先,门控网络会先对输入的数据进行分析,就像是在评估情况一样,然后决定哪些专家最适合处理这个输入。
-
专家选择:根据门控网络的评估,它会挑选出最合适的专家来处理这个任务。这就像是给任务分配最合适的人选,确保每个人都能在自己擅长的领域里发挥最大的作用。
-
输出组合:最后,MoE模型会把各个专家的输出结果综合起来,形成一个最终的输出。这个过程就像是把不同专家的意见汇总起来,得出一个全面的结论。
整个推理过程都设计得非常经济高效,确保了在解决问题时,既能够利用到每个专家的专长,又能最大限度地减少计算和资源的消耗。这样,MoE模型就能在保持高性能的同时,也保持了高效率。
输入路由
MoE模型里的输入路由,就像是个智能导航系统,它的作用就是确保每个任务都能找到最适合它的处理方式。
当一个新的输入进来,门控网络就开始工作了。它会对这个输入进行评估,然后在整个模型的专家团队里,为每个成员分配一个概率。这个概率反映了每个专家处理这个输入的适合程度。
接着,门控网络会根据这个概率分布,把输入发送给最有可能处理好它的专家。这个过程就像是把任务分配给最擅长的人,确保每个任务都能得到最专业的处理。
通过这种方式,MoE模型能够确保每个输入都能得到最合适的专家的关注,从而提高整个模型的决策质量和效率。这就像是在团队中,每个人都能发挥自己的长处,共同推动项目向前发展。
专家选择
在MoE模型里,专家选择这一步,就像是在挑选最合适的人选来完成一项任务。
-
选择过程:门控网络会根据输入的特性,给所有可能的模型分配一个概率,就像是给它们打分。然后,它会根据这个分数,挑选出得分最高的一个或几个模型来处理这个输入。
-
资源优化:只选择少数几个模型来处理每个输入,这样做的好处是可以节省计算资源。毕竟,如果每次任务都让整个团队出动,那资源就太浪费了。
-
专业利用:虽然只有少数模型被选中,但它们都是根据门控网络的评估,最适合处理当前任务的专家。这样,每个任务都能得到最专业的处理,同时还能保持整个系统的高效运行。
-
性能提升:门控网络的输出确保了每次选择的模型都是最合适的,这样不仅提高了任务处理的准确性,也提升了整个系统的性能。
总的来说,MoE模型通过精心设计的专家选择过程,既保证了每个任务都能得到专业的处理,又确保了资源的有效利用和系统性能的最大化。
输出组合
在MoE模型的推理阶段,输出组合是最后的关键步骤,确保了整个模型的智慧得以充分发挥。
-
加权平均:通常,专家们给出的结果会通过一种加权平均的方式来合并。这里的权重,就是门控网络给每个专家分配的概率。这样,那些被认为更适合处理当前任务的专家,它们的意见就会在最终决策中占更大的比重。
-
替代方法:除了加权平均,有时候也会用到投票或者更高级的学习方法来合并专家们的输出。这就像是在团队中,不仅要考虑每个人的观点,还要找到最合适的方式来整合这些观点。
-
整合优势:无论使用哪种方法,目标都是一致的:把各个专家的独特见解整合起来,形成一个既统一又准确的最终预测。这样,就能充分利用MoE架构的优势,发挥团队的整体智慧。
随着技术的发展,处理大型模型的需求越来越大,MoE模型因其快速、高效和优化的特点,正成为一种有前景的解决方案。除了这些,MoE还提供了其他一些好处:
-
性能提升:通过只激活相关专家,MoE模型能够减少不必要的计算,从而提高处理速度和效率。
-
灵活性增强:MoE模型可以根据不同的任务需求,灵活地增加或调整专家的数量和专长。
-
容错性:即使某个专家出现问题,也不会影响整个模型的运行,因为其他专家可以继续工作。
-
可扩展性:MoE模型通过分解复杂问题,使其更容易扩展和适应更大规模的数据和任务。
总的来说,MoE模型通过其独特的架构和工作方式,为处理大型和复杂的AI任务提供了一个强大而灵活的解决方案。
专家混合(MoE)的好处
MoE架构,也就是专家混合模型,它的好处可真不少:
-
性能:MoE模型能够挑出对当前任务最在行的专家来干活,这样就能避免多余的计算,不仅速度快了,还能节省资源。
-
灵活性:因为MoE模型里聚集了各种专长的专家,所以它能够适应各种各样的任务。需要什么专长,就调用哪个专家,这样的模型用起来非常灵活。
-
容错性:MoE模型采取的是“分而治之”的策略,每个任务都是分开处理的。这样一来,如果某个专家出了点问题,也不会影响到整个模型,因为其他专家还能继续工作。
-
可扩展性:MoE模型擅长把大问题拆分成小问题,然后逐个击破。这种处理方式让MoE模型能够轻松应对越来越复杂的任务。
总的来说,MoE架构就像是个多才多艺的团队,每个成员都有自己的特长,而且团队还能根据需要灵活调整,既稳定又可靠。
专家混合(MoE)的应用
专家混合(MoE)这个概念已经存在了30年,它在机器学习的不同领域里都发挥了重要作用。MoE的应用可以说是非常广泛,下面列举了一些主要的应用场景:
-
自然语言处理(NLP):MoE可以在处理语言时,让不同的专家分别学习语法、语义等不同的语言特性,从而提高语言模型的性能。
-
计算机视觉:在图像识别和处理方面,MoE可以分配不同的专家来识别图像中的不同对象或特征,提高识别的准确性。
-
推荐系统:MoE可以应用于推荐算法,通过不同的专家学习用户的不同偏好,提供更加个性化的推荐。
-
语音识别:在语音识别领域,MoE可以优化模型以更好地理解和处理不同的语音特征和口音。
-
医疗诊断:MoE可以集成多个专家系统,每个专家专注于不同的医疗领域,共同提供更准确的诊断结果。
-
金融风险评估:MoE可以应用于金融模型,通过不同的专家分析不同的风险因素,提高风险评估的精确度。
MoE之所以在这些领域受到欢迎,是因为它能够将复杂的任务分解给专家处理,同时保持模型的高效和灵活性。随着技术的发展,MoE的应用范围还在不断扩大。

这篇关于大话MoE混合专家模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









