本文主要是介绍【Unity】GPU骨骼 GPU Spine动画 2D/3D渲染性能开挂 合批渲染 支持武器挂载 动画事件 动画融合 实时获取骨骼位置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GPU 3D骨骼动画和 GPU 2D Spine动画插件均包含在【万人同屏整合方案】中,老板们可在某宝搜:[游戏开发资源商店] 以获取全套方案的所有源码插件。
万人同屏渲染避障锁敌方案实现对抗战斗demo 展示GPU动画高级功能 动画事件 动画平滑过渡 融合
插件功能:
1. 支持3D动画转GPU动画
2. 支持2D Spine动画转GPU动画
3. 支持挂点、支持挂载物、动态切换挂载物、实时获取挂点Transform信息
4. 支持实时获取gpu动画信息,如动画帧数、动画时长、动画是否循环
5. 支持动画事件
GPU骨骼动画视频介绍:
GPU顶点动画和GPU骨骼动画实现原理及优缺点对比 性能优化
2d spine动画帧数提升数十倍?spine转gpu动画 2d spine动画 10w单位

GPU动画是实现万人同屏的前置条件,在之前的文章中已介绍过GPU顶点动画的实现方法:【Unity】渲染性能开挂GPU Animation, 动画渲染合批GPU Instance_skinmeshrender合批-CSDN博客
GPU顶点动画的优缺点:
GPU顶点动画是将每一帧动画的Mesh顶点/法线存入贴图,在Shader中直接读取顶点/法线使用。
优点:由于没有过多的计算,因此性能较高;
缺点:如果一个模型有多个SkinnedMeshRenderer需要先合并Mesh; 生成的动画/法线贴图较大;不支持切换挂载武器;
GPU骨骼动画的优缺点:
GPU骨骼动画是将每一帧动画的所有骨骼的矩阵信息存入贴图,每一个顶点至多受4根骨骼影响,在Shader中用这4根骨骼的矩阵和4根骨骼对应的蒙皮权重对顶点位置和法线进行变换,得到受骨骼影响后的顶点/法线值。
优点:动画贴图很小;无需合并Mesh;支持挂载武器切换;可以实时获取到某个挂点位置
缺点:需要一定计算量,因此性能比顶点动画略低;
GPU骨骼动画实现:
一,读取骨骼数据,生成动画贴图,Mesh
1. 获取蒙皮动画的骨骼信息:
可通过SkinnedMeshRenderer的rootBone查找到根骨骼,或者直接使用bones字段,该字段为SkinnedMeshRenderer关联的所有骨骼的Transform数组;
2. 从动画曲线获取每个动画帧记录的骨骼Transform数值:
以获取动画每帧的骨骼位置为例:
private Vector3 GetBonePositionAtTime(string bonePath, AnimationClip clip, float animTime)
{var localPosXCurve = EditorCurveBinding.FloatCurve(bonePath, typeof(Transform), "m_LocalPosition.x");var localPosYCurve = EditorCurveBinding.FloatCurve(bonePath, typeof(Transform), "m_LocalPosition.y");var localPosZCurve = EditorCurveBinding.FloatCurve(bonePath, typeof(Transform), "m_LocalPosition.z");Vector3 pos = Vector3.zero;pos.x = AnimationUtility.GetEditorCurve(clip, localPosXCurve).Evaluate(animTime);pos.y = AnimationUtility.GetEditorCurve(clip, localPosYCurve).Evaluate(animTime);pos.z = AnimationUtility.GetEditorCurve(clip, localPosZCurve).Evaluate(animTime);return pos;
}3. 将骨骼矩阵写入动画贴图:
把矩阵的前3行数值,以骨骼个数为偏移量分别写入动画贴图:
for (int boneIdx = 0; boneIdx < bones.Length; boneIdx++){var bone = bones[boneIdx];bool noBone = bone.GetComponent<MeshRenderer>() != null;if (!noBone && bone.TryGetComponent<SkinnedMeshRenderer>(out var sMeshRender) && sMeshRender.rootBone == null){noBone = true;}var boneMatrix = bone.localToWorldMatrix;if (!noBone){boneMatrix *= bonesW2LMatrices[boneIdx];}animBoneTex.SetPixel(boneIdx, curFrameIndex, boneMatrix.GetRow(0));animBoneTex.SetPixel(bonesCount + boneIdx, curFrameIndex, boneMatrix.GetRow(1));animBoneTex.SetPixel(bonesCount * 2 + boneIdx, curFrameIndex, boneMatrix.GetRow(2));}4. 将每个动画的开始帧/结束帧、动画时常、动画是否循环播放的信息写入动画贴图的最后一列像素
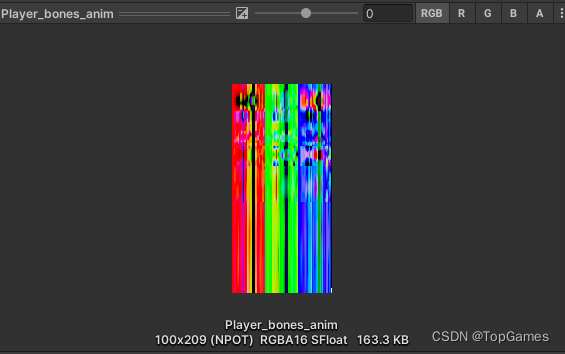
5. 生成Mesh网格:
有了骨骼信息的动画贴图,还需要知道每个顶点受哪些骨骼影响,才能在Shader中取到对应的骨骼信息对顶点和法线进行变换;
为了节省资源和读取方便,我们可以直接把顶点关联的4根骨骼以及每根骨骼的权重分别塞到Mesh的UV2和UV3两个通道。
二、GPU骨骼动画Shader实现:
1. 从动画贴图中解析当前动画的起始/结束帧,根据是否Loop来计算出当前动画帧:

2. 以当前帧为动画贴图采样的V坐标,采样获取所有骨骼矩阵每行数值,构建骨骼矩阵并计算顶点/法线:

3. 通过自定义函数得到转换后的顶点坐标和法线并应用到GPU骨骼动画shader:
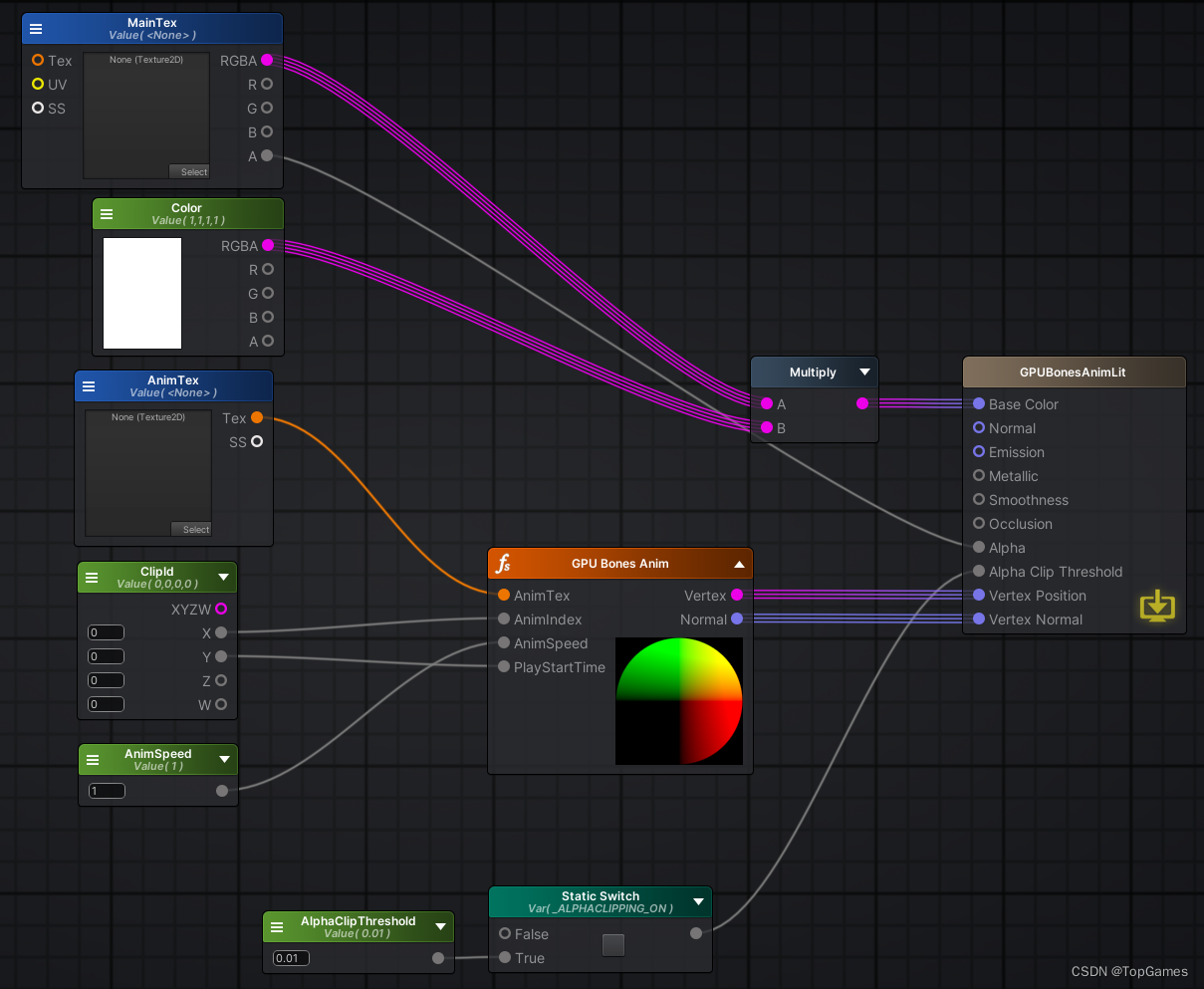
这样就完成了GPU骨骼动画功能,切换动画时传入动画Index和当前时间Time.time,动画片段将自动从起始帧开始播放,并且完美支持动画是否循环。对于在骨骼上挂载的武器,无论是MeshRenderer还是SkinnedMeshRenderer都完美支持,因为挂载武器的节点Transform本身也作为骨骼写入到了动画贴图,Shader中会自动通过骨骼的Local2WorldMatrix对顶点进行变换,自然而然武器就会跟着骨骼动。
三,获取挂点位置
例如GPU动画人物手里拿着一把枪,发射子弹时就需要在枪口的位置创建并发射子弹,由于GPU动画已经没有了骨骼Transform,枪口的位置怎么获取呢?
GPU动画因为是纯Shader实现,所以切换动画只需要修改材质的ClipId属性即可,其中x作为动画索引,y作为动画播放的开始时间,即Time.time。
有了动画索引和播放的开始时间,我们就可以得到当前动画已经播放了多久,根据已经播放时长就可以算出动画播到了第几帧,通过第几帧就可以从动画贴图读出任意骨骼的矩阵,这样就实现了随用随取的高性能获取挂载点位置、旋转、缩放。
四,GPU动画帧事件:
GPU动画转换工具会自动把Animation Clip中包含的事件数据保存到文件里,无需手动处理。并且支持随意增删事件。
GPU动画事件同时支持 Mesh Renderer渲染和BRG渲染。
两种渲染模式触发逻辑不同:
1. 使用MeshRenderer渲染只需挂载一个事件脚本,然后就像为Button添加/移除监听事件一样简单。
2. 使用BRG渲染, BRG提供了获取触发事件的接口,接口使用Jobs检测当前帧触发的事件,并将事件列表返回,由用户在主线程自行调用触发。大大提升了海量GPU动画单位事件触发性能。
同时GPU动画事件处理时会进行插帧计算,不会因为卡顿问题导致跳过动画事件的触发。
例如:一个弓箭手射箭动画,动画前大部分是搭箭、拉弓,动画最后一帧才松手,为了显示效果同步,就需要在最后一帧弓箭手松手时让箭发射出去,而不是在搭箭/拉弓的时候就发射箭。通过使用帧事件就能完美卡点解决这个问题。
五,GPU动画过渡/融合:
目前市面上的GPU动画插件要么是没有动画融合,要么就是使用脚本计算融合,会导致性能大打折扣。为了保证性能优先、兼容性高,最佳方案还是纯shader处理。
如何用最小的代价实现GPU动画平滑过渡呢?GPU动画切换动画时需要修改material上的shader参数clipId(Vector4),其中x为动画clip的索引,y为动画切换时间,zw是预留属性,暂未用到。
已知clip索引和切换动画的时间就可以轻易计算出动画已经播了多久,进而计算出播到第几帧,然后通过帧数就可以从动画贴图中读取到当前帧所有骨骼的Transform信息,然后所有骨骼从当前的Transform数值平滑过渡到下一动画clip索引的第一帧骨骼Transform不就能实现骨骼平滑过渡了吗?我们还需要指导上一个动画索引和上一个动画开始播放的时间,正好存入预留的zw中。
GPU 2d Spine动画实现:
有多个网友反馈有2D GPU动画的需求,不过我们通常会认为2D很难存在渲染瓶颈,然而并非如此。经过实际测试同屏显示相同的动画人物,1W个Spine动画 vs 1W个Animator动画。测试结果令人大跌眼镜!Spine动画和Animator动画性能接近,1W单位下都只有8帧左右。要知道,我们之前测试的五百多顶点的3D人物,同数量级下能达到近9帧左右。Spine动画性能竟然如此之差!
看来对于数量级超过百、千单位的项目,非常有必要使用GPU Spine动画。
2d spine动画帧数提升30倍 spine转gpu动画 2d spine动画 10w单位
实现原理其实就是把Spine动画转换为Animator动画,由于2D动画都是有面片Mesh组成,z轴全为0. 因此必须解决渲染层级的问题,这一转换过程需对Mesh进行修改以使得渲染层级正确。转换为Animator动画后就可以使用我们的GPU动画转换工具直接进行转换,同样支持顶点动画/骨骼动画两种模式。
同屏1W个单位测试环境下,Spine动画转换为GPU 2D动画后帧数直接提升10倍以上,使用万人同屏方案合批渲染功能后,相比Spine动画提升接近恐怖的40倍,对于2D割草游戏绝对是最佳方案。
这篇关于【Unity】GPU骨骼 GPU Spine动画 2D/3D渲染性能开挂 合批渲染 支持武器挂载 动画事件 动画融合 实时获取骨骼位置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




