本文主要是介绍行人轨迹论文:STUGCN:A Social Spatio-Temporal Unifying Graph Convolutional Network for Trajectory Predictio,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
STUGCN:A Social Spatio-Temporal Unifying Graph Convolutional Network for Trajectory Prediction用于轨迹预测的社会时空统一图卷积网络
Abstract-动态场景中交互代理的轨迹预测,也称为轨迹预测,是许多应用的关键问题,包括机器人系统和自动驾驶。由于行人之间的复杂交互,该问题提出了重大挑战。为了预测未来的行人轨迹,我们提出了一种基于时空图卷积网络架构的时空统一图卷积网络(STUGCN)。在每个时间步,跨时空跳跃连接捕获的时空交互。最后,在聚合特征的时间维度上,使用时间外推器卷积神经网络 (TXP-CNN) 来预测行人的未来轨迹。与最先进的方法相比,我们的模型在两个公开可用的人群数据集(ETH 和 UCY)上优于它们,并实现了最先进的性能
1. Introduction
预测行人路径对于包括自动驾驶汽车和监控系统在内的各种应用至关重要。只有准确预测行人轨迹,自动驾驶汽车才能做出有效的避碰决策,并为下游轨迹规划模块提供关键信息[1]。
由于行人运动的随机性,很难准确预测行人的轨迹。在人行道和十字路口,行人随时可能改变行进方向,他们的移动必须考虑到与其他行人的互动。例如,同向行走的行人可能会向同一个方向移动,行人必须与相邻行人保持安全距离。
虽然已经观察到许多社会模式,但很难将它们完全考虑在内。已经进行了一些实验来系统化交互建模。社会力模型使用手工参数描述人类交互,但手工规则难以在复杂的交互场景中推广。某些作品利用社交池来预测行人人群的轨迹。
|2-5|除了社交池层外,还可以使用生成对抗网络。这些方法采用循环架构。
作为模型社会交互变化的图形表示与 [2, 3] 相比,是进一步的研究方向。我们的方法属于这一组,但与现有方法相比显着提高了我们的效率。
SocialSTGCNN [3] 通过使用图神经网络 (GNN) 来估计轨迹。但为了随时去除空间关系,STGCNN 使用图表卷积,然后用 TCN 对时间动态进行建模。尽管这种分解提供了有效的长期建模,但它阻碍了信息随时间的直接流动以捕获复杂的区域空间时间依赖性。
**为了解决上述问题,我们提出了一种新颖的 STUGCN 架构(Spatio-Temporal Unifying Graph Convolutional Network)。我们引入了统一的 G3D 图卷积模块,该模块能够显式地建模时空依赖关系。
G3D 通过在“3D”时空域中包含图形边缘区域作为不受阻碍的信息流的跳跃连接来实现这一点,这显着简化了学习复杂区域时空依赖关系的过程。时间外推器卷积神经网络 (TXP-CNN) 使用组合 GNN 的特征作为数据时间维度的预测解码器。**在两个数据集上进行了广泛的实验,以确定所提出模型的优越性 ETH [4] 和 UCY [5] ,我们的模型在两个数据集上都达到了最佳性能。
2. Related Works
Human trajectory prediction using deep models.
在预测人类轨迹方面已经进行了数十年的研究。为了捕捉交互,Social-LSTM [6] 构建了一个包含附近行人隐藏状态的社交池。但它赋予一定半径内的行人相同的权重,在不同的场景下使用相同的池化层半径。 SR-LSTM 模型使用来自社交的信息来增强场景,并且在传递消息时,模型会调整附近行人的权重。 SceneLSTM[7] 充分利用了场景信息。 CIDDN [8] 使用多层感知器将每个行人的位置映射到高维特征空间,从中为其他行人分配不同的权重。 PIF [9] 和 Sophie [10] 从场景中提取视觉特征并将它们组合到 LSTM 中以进行场景感知轨迹预测。
STGAT 方法使用 LSTM 和图注意力网络来构建编码器。 Social-BiGAT [2] 是一种利用图注意力网络的行人社交互动模型。 Social-BiGAT 将 LSTM 输出馈送到图中。为了替换聚合层,Social-STGCNN 从一开始就将行人轨迹建模为时空图,并使用基于欧几里德距离的核函数定义空间图。然后,使用 Graph GCN 和 TCN,Social-STGCNN 操作时空图。
Recent Advances in Convolutional Graph CNNs 卷积图 CNN 的最新进展
图卷积网络 (GCN) 最初用于节点分类和动作识别。最近,GCN 已经在各种应用中成功实现[11-17]。 GCN 将卷积从图片推广到图。使用基于距离的采样函数构建图卷积层,然后将其作为基本模块构建最终的时空图卷积网络[3]。 STGCN [18] 是一项开创性的工作,使用时空图卷积网络进行动作识别。2s-AGCN [19] 在提取空间特征时引入了注意力机制,并利用二阶信息来提高性能。 **MS-G3D [20] 提出了跨时空跳跃连接来捕获动态时空联合关系,并且模型使用解耦聚合方案来消除图的冗余依赖关系。我们修改它以适应我们的情况。**第 3 节包含附加信息。
3. THE STUGCN MODEL
该模型主要由三部分组成:(1)行人预测的图表示,(2)空间图神经网络,以及(3)时间外推器卷积神经网络模型。所提出的 STUGCN 方案的设计如图1所示 。

A. Graph Representation of Pedestrian Prediction
我们构建了一组空间图 Gt,表示每个时间步长 t,行人在场景中的相对位置。
Gt被定义为 G t = { V t , E t } G_{t}=\left\{V_{t}, E_{t}\right\} Gt={Vt,Et},
其中, V t = { v t i ∣ ∀ i ∈ { 1 , … , N } } V_{t}=\left\{v_{t}^{i} \mid \forall_{i} \in\{1, \ldots, N\}\right\} Vt={vti∣∀i∈{1,…,N}}是场景中行人的节点集。第i个行人在时间步长t处的坐标包含在节点 v t i v_{t}^{i} vti的特征向量中.
{ E t = e t i j ∣ ∀ i , j ∈ { 1 , … , N } } \left\{E_{t}=e_{t}^{i j} \mid \forall i, j \in\{1, \ldots, N\}\right\} {Et=etij∣∀i,j∈{1,…,N}}是图Gt的边集。 e t i j e_{t}^{i j} etij是 v t i v_{t}^{i} vti和 v t j v_{t}^{j} vtj中间的边。
为了模拟两个节点相互影响的程度,使用加权邻接矩阵代替标准邻接矩阵。我们使用方程中定义的 L2 范数的倒数来允许正确的特征提取:
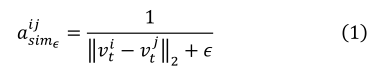
此外,对于每个时间步长 t,我们对邻接矩阵 A A A进行归一化,如前所述 [3][15],以促进特征提取:
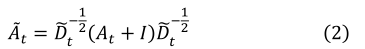
B. Spatial Graph Neural Networks model 空间图神经网络模型
以前的工作将时间和空间信息分成两个步骤,而不是同时提取它们。为了捕捉每个节点对其属于当前和相邻时间步长的邻居的影响,我们引入了 G3D:统一时空建模。通过将所有节点在前一个时刻和下一个时刻连接起来,G3D 得到一个时空子图。根据子图,可以直接捕获每个节点与其时空邻居之间的相关性。
Cross-Spacetime Skip Connections 为了结合来自相邻帧的信息,我们首先创建一个包含来自相邻帧的数据的新图。 G ( τ ) = ( V ( τ ) , E ( τ ) ) \mathrm{G}_{(\tau)}=\left(\mathrm{V}_{(\tau)}, \mathrm{E}_{(\tau)}\right) G(τ)=(V(τ),E(τ)),其中 V ( τ ) = V 1 … ⋃ V τ \mathrm{V}_{(\tau)} = V1 … ⋃Vτ V(τ)=V1…⋃Vτ 是窗口中跨 τ \tau τ 帧的所有节点集的并集。
‘图 2’ 表明与 MS-G3D[19] 中的 Ã 不同,初始边集 E ( τ ) E(τ) E(τ) 是通过将三个连续空间图中的 A ~ Ã A~平铺成块邻接矩阵 A ~ ( τ ) Ã(τ) A~(τ) 来定义的,其中
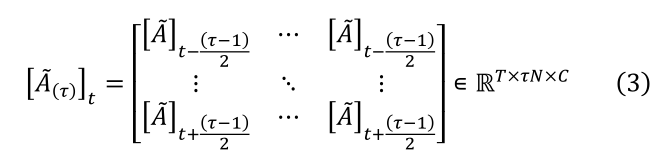
通过提取具有 ( τ − 1 ) / 2 (τ−1) /2 (τ−1)/2 个零填充的滑动局部块,我们可以很容易地获得 X ( τ ) ∈ R T × τ N × C X(τ) ∈ R ^{T×τN×C} X(τ)∈RT×τN×C。
融合输入数据 X ( τ ) ( l ) X_{(τ)}^{(l)} X(τ)(l)和邻接矩阵 [ A ( τ ) ] t [A_{(τ)}]_t [A(τ)]t,滑动窗口的图卷积运算表示为:
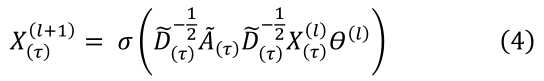

图 2 跨时空跳跃连接示例(左)和 G3D 模型的邻接矩阵。
C. Time-Extrapolator Convolution Neural Network model
TXP-CNN 旨在通过 GCN 的结果生成未来轨迹。结果包括行人运动特征和与其他交通代理的社交互动。我们直接对 v s t v_{st} vst进行卷积运算,再次得到带有残差架构的预测轨迹,即:
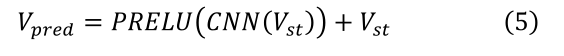
值得注意的是,在第一个TXP-CNN层,我们需要扩大一维 v s t v_{st} vst从 T o b s t o T p r e d T_{obs}toT_{pred} TobstoTpred生成要求的数据帧。
IV. EXPERIMENT
A. Dataset and Metrics
使用两个著名的数据集 ETH [4] 和 UCY [5] 在该部分中测试了所提出的方法。两个数据集都包含每 0.4 秒采集的样本,持续 8 秒。为了便于与其他方法进行比较,所提出的方法的实验配置与 Social-LSTM[6] 和 Graves [25] 的配置相同。在整个准备和评估过程中,采样频率为 0.4s,前 8 帧代表观察到的历史轨迹,而后 12 帧代表用于预测的真实轨迹。使用了两个常用的测量指标:平均位移误差 (ADE) [26] 和最终位移误差 (FDE) [6]。 ADE 沿轨迹平均评估预测精度,而 FDE 仅考虑端点的预测精度
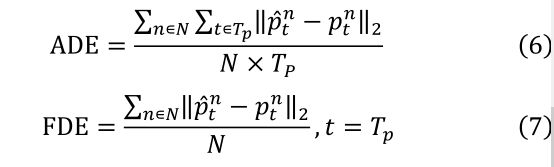
B. Implementation Details
为了实现所提出的网络,使用了 PyTorch 的深度学习框架。 Social-STGCNN 是由 ST-GCNN 和 TXP-CNN 分层构建的。 PRELU [27] 在我们的模型中用作激活函数。我们的消融研究表明,使用的最佳模型由一个编码器层和五个 TXP-CNN 层组成。为了优化模型,我们使用了 128 个 epoch 的训练批量大小,并使用随机梯度下降法以 0.001 的初始学习率对其进行了 250 个 epoch 的训练。
C. Ablation study
我们在编码器为一层、两层和三层时测试了ADE/FDE。 'Table 2’显示STGCN和G3D都是1层时效果最好。这可能与图卷积网络中层数增加时出现的过度平滑现象有关。

. STUGCN 的消融分析。第一列表示编码器层的总数。最佳配置是为 ST-GCNN 和 G3D 使用单层
D. Comparison with the State-of-the-art Methods
a) 推理速度和模型大小:Socail-STGCNN 的参数量为 7.6K。在我们的案例中,模型参数的数量略高。这是因为我们增加了跨时间连接。除了 stgcnn 之外,最小的参数量是 s-gan。它的参数量为 46.3k,而我们的参数量,如“表 3”所示,是它的四分之一。
在推理速度方面,我们的模型与 Social-STGCNN 相当,达到了先进水平。

b) STUGCN 的 ADE/FDE:如“表 1”所示,提出的方法与 ETH 和 UCY 数据集上的 ADE/FDE 指标的其他最先进方法进行了比较。从提出的 STUGCN 过程中可以看出,获得了最新的效率,并且 FDE 度量优于所有当前最先进的方法。这归因于包含跨时空跳过链接。在 FDE 指标方面,所提出的方法实现了 0.72 的误差,比最近的模型减少了 23%。在 ADE 指标方面,该方法的误差比 SR-LSTM-2 略大 4%。但这也是更好的表现之一。更值得注意的是,它外包了使用图像信息的过程,例如不使用场景图像信息的 PIF、SR-LSTM 和 Sophie。

V. CONCLUSION
在本文中,提出了一种新的 STUGCN 行人轨迹预测方法。它学习具有代表性、鲁棒性和判别性的图嵌入。在所提出的方法中,跨时空跳跃连接用于同时直接捕获局部时空相关性。在 ETH 和 UCY 数据集上的实验结果表明,所提出的方法在预测行人轨迹方面优于其他方法。未来的工作将侧重于将 STUGCN 扩展到其他交通代理,例如汽车、骑自行车的人、卡车等。此外,将更加努力地提出三种故障模式的解决方案。
这篇关于行人轨迹论文:STUGCN:A Social Spatio-Temporal Unifying Graph Convolutional Network for Trajectory Predictio的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
