spatio专题

KDD 2024 时空数据(Spatio-temporal) ADS论文总结
2024 KDD( ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 知识发现和数据挖掘会议)在2024年8月25日-29日在西班牙巴塞罗那举行。 本文总结了KDD2024有关时空数据(Spatial-temporal) 的相关论文,如有疏漏,欢迎大家补充。 时空数据Topic:时空(交通)预测, 生成,拥堵预测,定价预
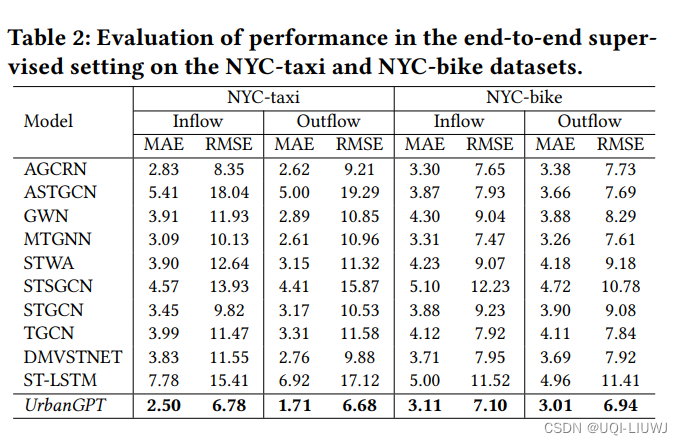
论文笔记:UrbanGPT: Spatio-Temporal Large Language Models
1 intro 时空预测的目标是预测并洞察城市环境随时间和空间不断变化的动态。其目的是预见城市生活多个方面的未来模式、趋势和事件,包括交通、人口流动和犯罪率。虽然已有许多努力致力于开发神经网络技术,以准确预测时空数据,但重要的是要注意,许多这些方法严重依赖于拥有足够的标记数据来生成精确的时空表示。 不幸的是,数据稀缺问题在实际的城市感知场景中普遍存在。在某些情况下,从下游场景收集任何标记数据变

Spatio-Temporal Pivotal Graph Neural Networks for Traffie Flow Forecasting
摘要:交通流量预测是一个经典的时空数据挖掘问题,具有许多实际应用。,最近,针对该问题提出了各种基于图神经网络(GNN)的方法,并取得了令人印象深刻的预测性能。然而,我们认为大多数现有方法忽视了某些节点(称为关键节点)的重要性,这些节点自然地与多个其他节点表现出广泛的联系。由于与其他节点相比,关键节点具有复杂的时空依赖性,因此对关键节点进行预测提出了挑战。在本文中,我们提出了一种基于 GNN 的
Flow Prediction in Spatio-Temporal Networks Based on Multitask Deep Learning
这是一篇郑宇团队2019年发表在 **IEEE Transactions on Knowledge and Data Engineering** 杂志上的一篇论文。 从题目来看文章提出的模型是一个多任务模型,在阅读文论之后发现是为了解决两个问题: ①流量预测;(同论文 [上一篇博文介绍的论文一样](https://blog.csdn.net/The_lastest/article/detai

Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction
本博文是对郑宇老师团队所提出的STResNet网络的一个略微扩充说明。本人自己在看完这篇论文的时候,感觉就一个字‘懵’。你说不懂吧,好像又明白点,你说懂吧又感觉有好多细节还是不清楚。好在该论文开放了源代码。经过对源代码的一番剖析,总算是弄懂之前不明白的一些细节。不过该源码是基于Keras实现的,由于本人之前一直使用Tensorflow,所以又对其利用tf进行了重构,代码整体上看起也来更加简洁,
2020-ASRM: A Semantic and Attention Spatio-temporal Recurrent Model for Next Location Prediction
[1] Zhang X, Li B, Song C, et al. SASRM: A Semantic and Attention Spatio-temporal Recurrent Model for Next Location Prediction[C]//2020 International Joint Conference on Neural Networks (IJCNN). IEEE
Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback简记
Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback简记 文章目录 Spatio-Temporal Representation With Deep Neural Recurrent Network in MIMO CSI Feedback简记参考简记LSTM结构深度可分

行人轨迹论文:STUGCN:A Social Spatio-Temporal Unifying Graph Convolutional Network for Trajectory Predictio
STUGCN:A Social Spatio-Temporal Unifying Graph Convolutional Network for Trajectory Prediction用于轨迹预测的社会时空统一图卷积网络 Abstract-动态场景中交互代理的轨迹预测,也称为轨迹预测,是许多应用的关键问题,包括机器人系统和自动驾驶。由于行人之间的复杂交互,该问题提出了重大挑战。为了预测未来的
交通流量预测HSTGCNT:Hierarchical Spatio–Temporal Graph Convolutional
Hierarchical Spatio–Temporal Graph Convolutional Networks and Transformer Network for Traffic Flow Forecasting 交通流预测的层次时空图卷积网络和Transformer网络 Abstract 图卷积网络(GCN)具有图形化描述道路网络不规则拓扑结构的能力,已被应用于交通流预测任务中
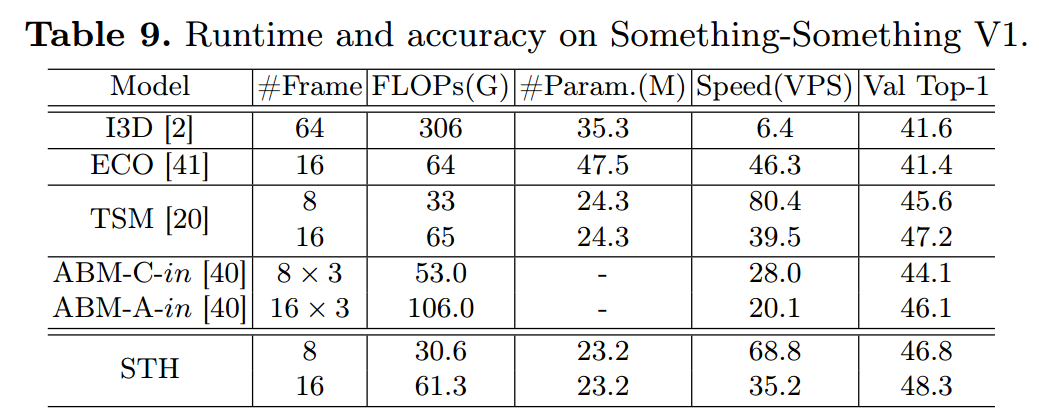
行为识别 - STH: Spatio-Temporal Hybrid Convolution for Efficient Action Recognition
文章目录 0. 前言1. 要解决什么问题2. 用了什么方法3. 效果如何4. 还存在什么问题 0. 前言 相关资料: arxivgithub:可能等不到开源啦论文解读 论文基本信息 领域:行为识别作者单位:西安交大&腾讯发表时间:2020.3 一句话总结:提出同时提取时空特征的结构,根据channel分组、分别进行时间卷积(3x1x1)和空间卷积(1x3x3)、合并结果。 1

EMNLP 2020 BiST: Bi-directional Spatio-Temporal Reasoning for Video-Grounded Dialogues
动机 基于视频的对话是非常具有挑战性的,这是因为(i)包含空间和时间变化的视频的复杂性,以及(ii)用户在视频或者多个对话轮中查询不同片段和/或不同目标的话语的复杂性。然而,现有的基于视频的对话方法往往关注于表面的时间级视觉线索,而不是从视频中获取更细粒度的空间信号。作者的方法旨在通过双向推理框架从视频中检索细粒度信息来挑战基于视频的对话来解决这一问题。与视频对话相关的任务是视频问答和视频c

Fast Visual Tracking via Dense Spatio-Temporal Context Lear
原文再续,书接一上回。话说上一次我们讲到了Correlation Filter类 tracker的老祖宗MOSSE,那么接下来就让我们看看如何对其进一步地优化改良。这次要谈的论文是我们国内Zhang Kaihua团队在ECCV 2014上发表的STC tracker:Fast Visual Tracking via Dense Spatio-Temporal Context Learning。相

Video anomaly detection with spatio-temporal dissociation 论文阅读
Video anomaly detection with spatio-temporal dissociation 摘要1.介绍2.相关工作3. Methods3.1. Overview3.2. Spatial autoencoder3.3. Motion autoencoder3.4. Variance attention module3.5. Clustering3.6. The tra
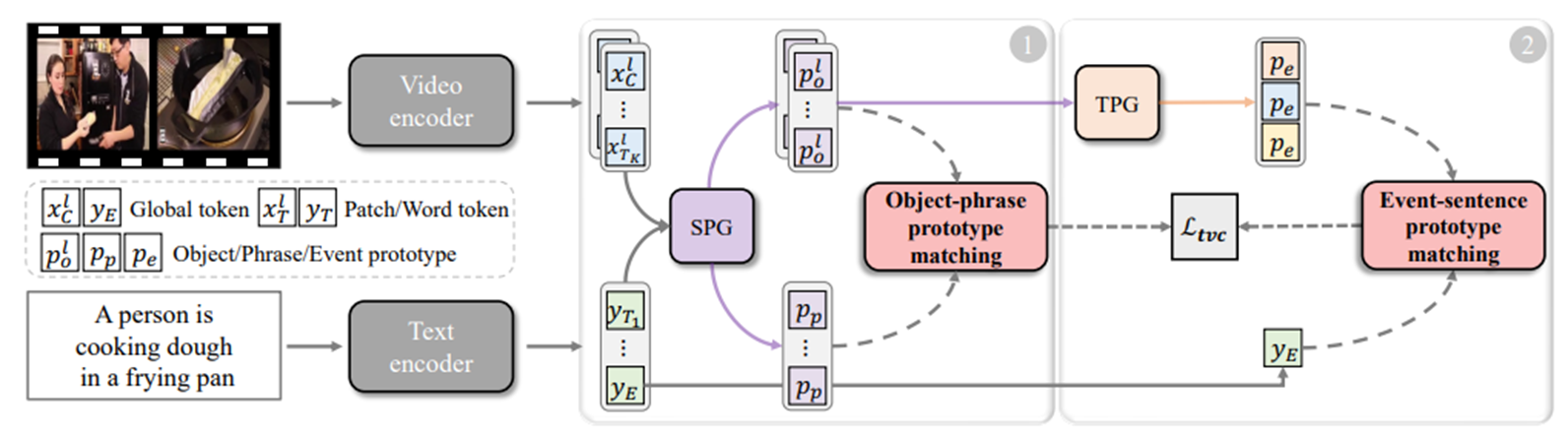
【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval
资料链接 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Progressive_Spatio-Temporal_Prototype_Matching_for_Text-Video_Retrieval_ICCV_2023_paper.pdf 代码链接:https://github.com/imccretrieval/pr
【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval
资料链接 论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Progressive_Spatio-Temporal_Prototype_Matching_for_Text-Video_Retrieval_ICCV_2023_paper.pdf 代码链接:https://github.com/imccretrieval/pr
ST-GRAT: A Novel Spatio-temporal Graph Attention Networks for Accurately Forecasting Dynamically Cha
研究问题 基于动态空间依赖的交通流预测问题 背景动机 传统方法不论是外部输入图结构还是自己学出图结构都假定道路之间的空间依赖关系是固定的,因此它们只计算一次空间依赖关系,并一直使用计算出的依赖关系,而不考虑动态变化的交通条件。通过注意力机制来建模动态空间依赖的模型往往忽略了图上固有的结构信息RNN有不能直接访问长输入序列中的过去的特征的限制,不如attention好 模型思想 空间注意力

Remote Photoplethysmograph Signal Measurement from Facial Videos Using Spatio-Temporal Networks
前言 前期方法的缺陷 早期rPPG研究多数为“提取—分析”的两阶段方法,首先检测或跟踪人脸以提取rPPG信号,然后分析并估计相应的平均HR。缺点:1)基于纯经验知识自定义的面部区域,不一定是最有效的区域,这些区域应该随数据而变化。2)有些方法中使用了手动制作的特征或过滤器,可能使重要的心跳信息丢失。 前期使用的深度学习方法也可能有一下缺点:1)HR估计任务被视

精读论文:Predicting Citywide Crowd Flows Using Deep Spatio-Temporal Residual Networks
Predicting Citywide Crowd Flows Using Deep Spatio-Temporal Residual Networks AAAI 2017 郑宇组的论文 文章首先介绍该问题的基本概念 ,接着描述系统的框架(本文跳过),然后介绍基于DNN的预测模型,最后进行实验验证模型结构与参数和与基线模型进行对比。 OUTLINE 人流量数据(crowd flows)
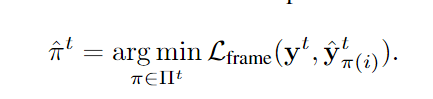
【论文阅读】End-to-End Spatio-Temporal Action Localisation with Video Transformers
文章目录 摘要和结论引言模型框架Vision EncoderTubelet Decoder(factorise Queries CA MHSA)Training objectiveMatching 摘要和结论 e2e,纯基于Transformer的模型,输入视频输出tubelets。无论是 对单个帧的稀疏边界框监督 还是 完整的小管注释。在这两种情况下,它都会预测连贯的tube

R语言实现 spatio-temporal exploratory models
鱼弦:CSDN内容合伙人、CSDN新星导师、51CTO(Top红人+专家博主) 、github开源爱好者(go-zero源码二次开发、游戏后端架构 https://github.com/Peakchen) R语言提供了丰富的功能和包,可以用于实现时空探索性模型(spatio-temporal exploratory models)。以下是该模型的原理详细解释: 数据准备:收集
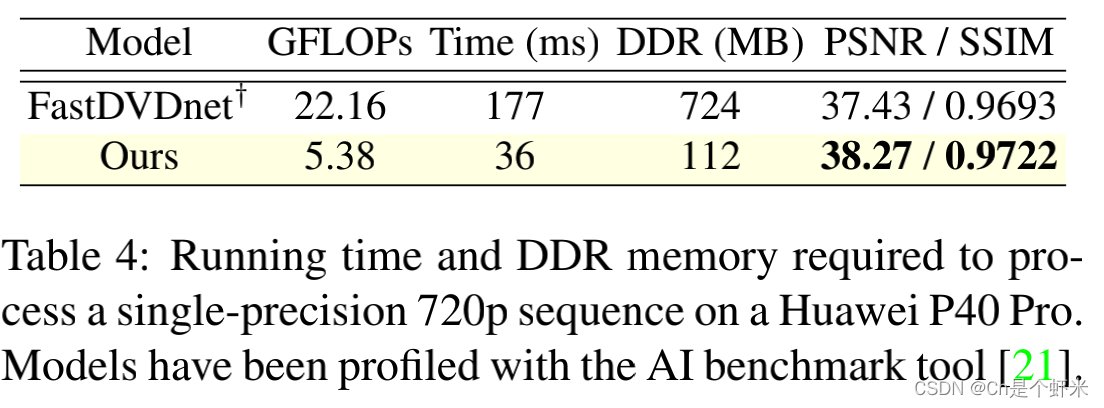
视频去噪EMVD:Efficient Multi-Stage Video Denoising with Recurrent Spatio-Temporal Fusion 全文翻译
摘要 近年来,基于深度学习的去噪方法以巨大的计算复杂度为代价,取得了无可比拟的性能。在这项工作中,我们提出了一种有效的多阶段视频去噪算法,称为EMVD,以大幅降低复杂性,同时保持甚至提高性能。首先,融合阶段通过递归组合视频中所有过去帧来减少噪声。然后,去噪阶段去除融合帧中的噪声。最后,细化阶段恢复在去噪帧中丢失的高频在去噪帧中恢复。所有阶段都在可学习和可逆线性算子获得的变换域表示上进行操作,
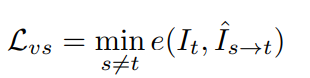
【MOTS】Learning a Spatio-Temporal embedding for video instance segmentation
Purpose 把特征映射到高维做聚类,加上自监督的训练得到的图片的Depth信息结合来做VIS Pipline 用ResNet18作为Encoder,得到每一帧的feature x_t;然后用3D卷积,把前后两者特征再滤波得到z_t;z_t通过Decoder(2个分支,每个分支7层卷积,3个upsample,Embedding分支的output通道数为p,Depth通道数为1)