本文主要是介绍【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
资料链接
论文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Li_Progressive_Spatio-Temporal_Prototype_Matching_for_Text-Video_Retrieval_ICCV_2023_paper.pdf
代码链接:https://github.com/imccretrieval/prost
背景与动机

文章发表于ICCV 2023,来自中科大IMCC实验室。
文本-视频检索是近年来比较新兴的领域,随着多模态和大模型的发展,这一领域也迸发出了前所未有的潜力。目前的主流方法是学习一个joint embedding space,将视频和文本编码成特征向量,在空间中含义相近的向量的位置也是相近的,从而通过计算向量间相似度实现检索。本文梳理了近期的一些工作,主要分为以下三个方向:
细粒度匹配:单一的特征向量难以编码丰富的细节信息,需要进行更细粒度的视频文本匹配。
多模态特征:视频有着丰富的多模态信息,使用多种多模态特征可增强检索性能。
大规模预训练:近年来大规模预训练广泛应用,经过预训练的模型检索能力得到显著提升。
作者团队在这一问题上,主要着重于第一个方向的研究。

典型的解决方案是直接对齐整个视频与句子的特征,这会忽视视频内容与文本的内在关系。因此,匹配过程应当同时考虑细粒度的空间内容和各种时间语义事件。这就是细粒度的匹配。
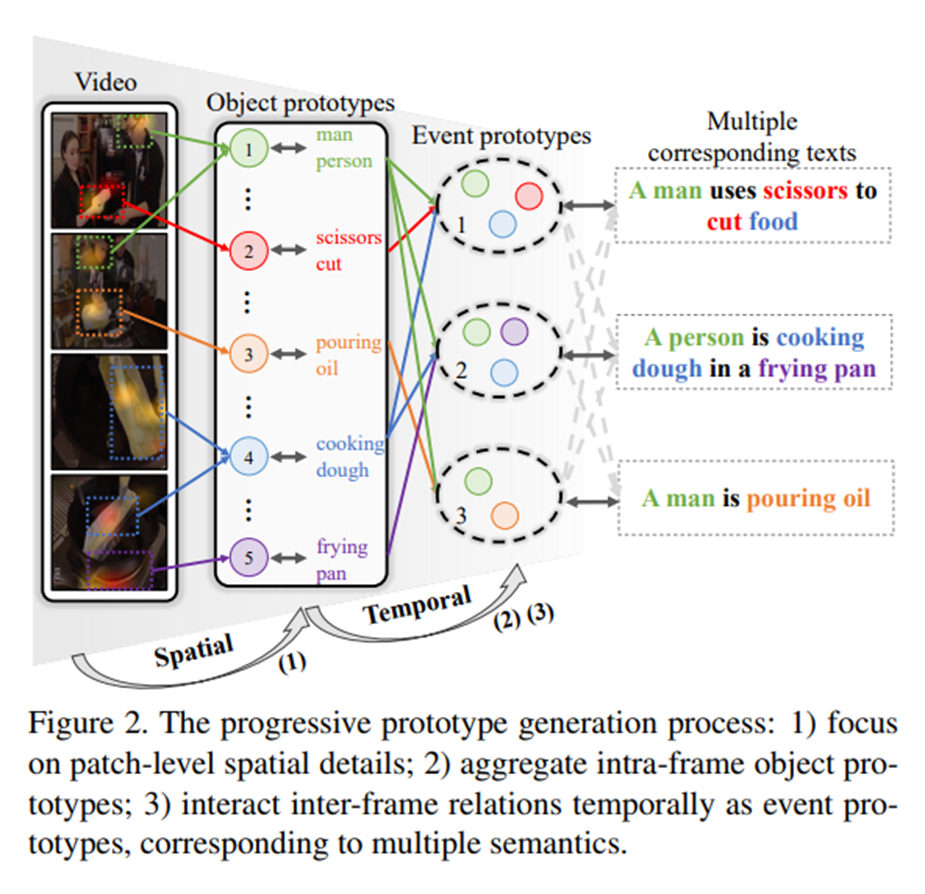
为此,作者团队提出一种具有渐进式时空原型匹配的文本-视频学习框架。它的大致框架如下:

方法
给定一个由n个视频![]() 以及它们对应的m个文本描述
以及它们对应的m个文本描述![]() 组成的数据集,文本-视频检索(TVR)旨在学习一个函数
组成的数据集,文本-视频检索(TVR)旨在学习一个函数![]() ,以有效地衡量模态之间的相似性。
,以有效地衡量模态之间的相似性。
对于文本查询![]() ,应当有:
,应当有: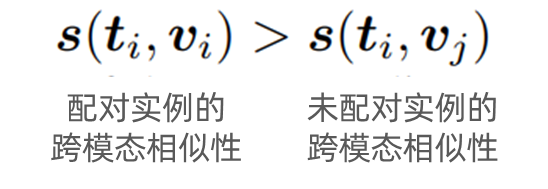
因此,需要强大的文本编码网络和视频编码网络来生成高质量的特征,从而实现有效的匹配。

采用 CLIP 作为骨干网络。给定输入视频,均匀地选择L个帧作为关键帧,提取连续特征:
![]()
其中![]() 是全局帧token特征,K是Patch数量,D是特征维数,Xi的Shape是(K+1) × D。
是全局帧token特征,K是Patch数量,D是特征维数,Xi的Shape是(K+1) × D。
给定查询文本,添加开始token和结束token,输出文本token特征可以定义为:
![]()
其中,![]() 是全局文本token特征,M和D分别是单词和特征维数,yi的Shape是(M+2) × D。
是全局文本token特征,M和D分别是单词和特征维数,yi的Shape是(M+2) × D。
方法 - 总体框架
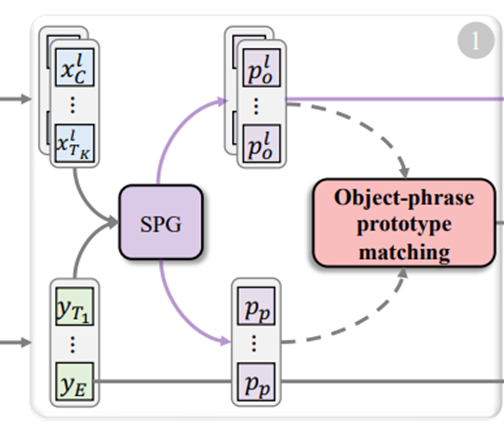
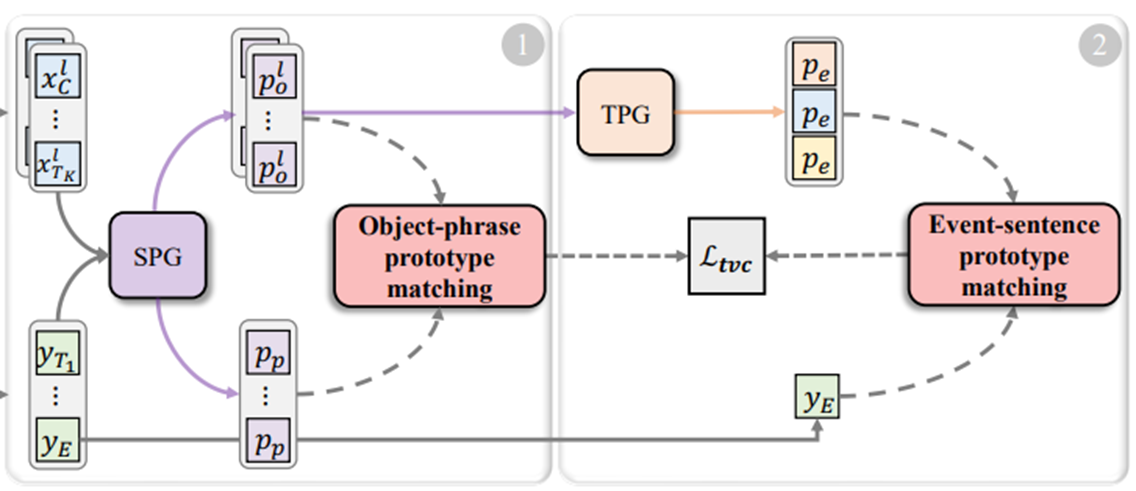
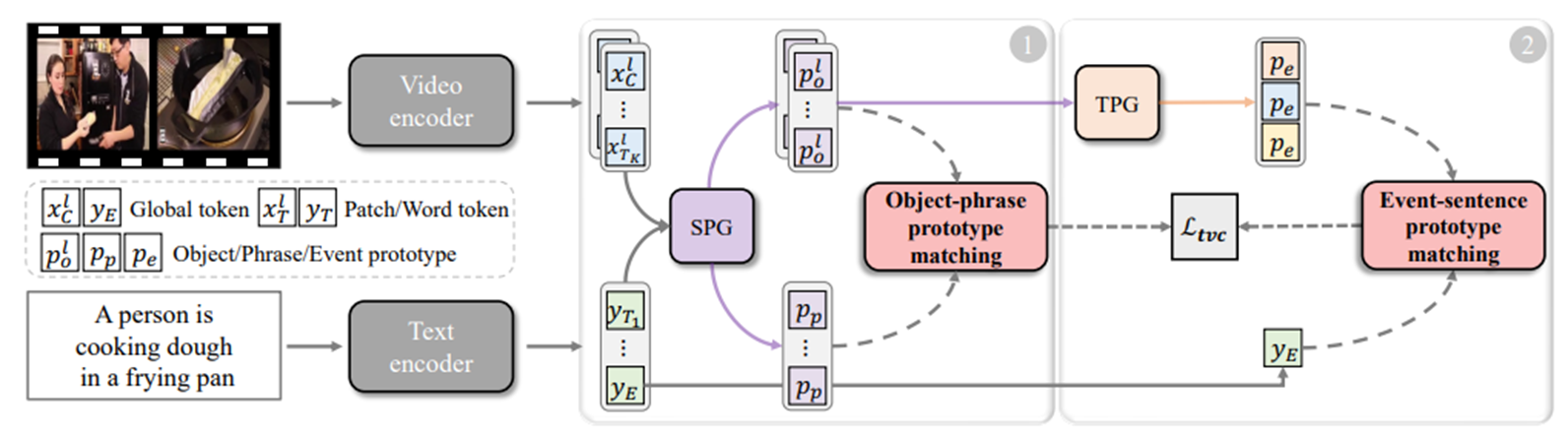
对象-短语原型匹配阶段
空间原型生成机制预测关键Patch或单词,这些Patch或单词被聚合成对象或短语原型。重要的是,优化对象-短语原型之间的局部对齐有助于模型感知空间细节。
事件-句子原型匹配阶段
设计了一个时间原型生成机制,将帧内对象与帧间时间关系相互关联。这样逐步生成的事件原型可以揭示视频中的语义多样性,用于动态匹配。
方法 - 对象短语原型匹配
相较于现有方法学习一个单一的Patch-Event投影,作者团队使用分而治之的方式解耦时空建模过程。
首先进行Patch-对象和单词-短语的空间原型聚合,来揭示关键的局部细节。
分为两个步骤:
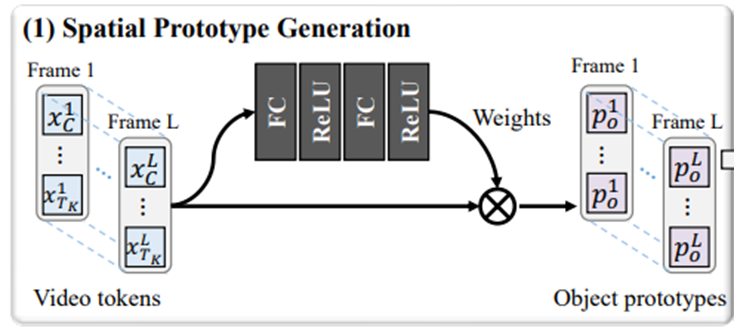
空间原型生成 Spatial Prototype Generation(SPG)
对于Patch特征,首先需要生成它们的空间对象原型:
使用两个全连接(FC)层和ReLU函数来预测稀疏权重![]() ,其中No是对象原型的数目,这样就可以避免对象原型受到冗余Patch的影响,从而使得对象原型更准确、集中。
,其中No是对象原型的数目,这样就可以避免对象原型受到冗余Patch的影响,从而使得对象原型更准确、集中。
![]() 其中,Po为对象原型, Shape为No×D。
其中,Po为对象原型, Shape为No×D。
对于文本,同样借鉴SPG机制,并设计了一个类似的网络结构来聚合单词标记,生成短语原型![]() 。
。
对象-短语匹配 Object-Phrase Matching
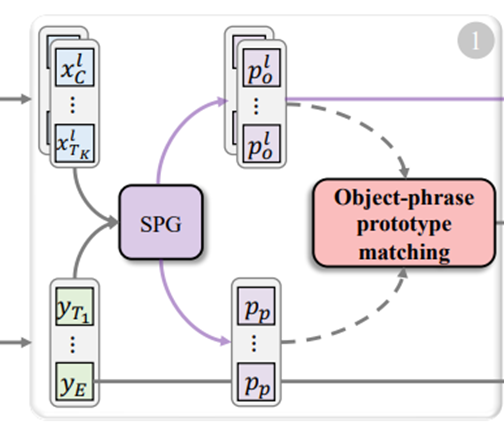
基于上一步骤生成的对象、文本原型,实现对象-短语原型匹配。
计算每个帧内的对象-短语原型的最大相似度,将最相似的短语原型和每个对象原型关联起来,反映了跨模态的细粒度分配。
然后,对于多帧对象相似度矩阵,找到跨帧序列的最大相似度分数,得到置信度更高的对象-短语匹配概率。最后将匹配得分求和,得到最终的相似性Sop:
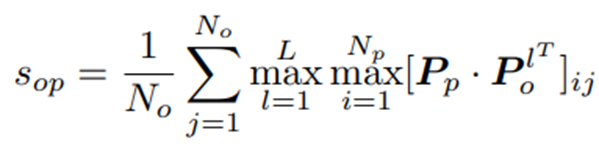
其中,No是对象原型的数量、Np是短语原型的数量、L是帧的数量。
这一部分的矩阵处理细节如下所示:
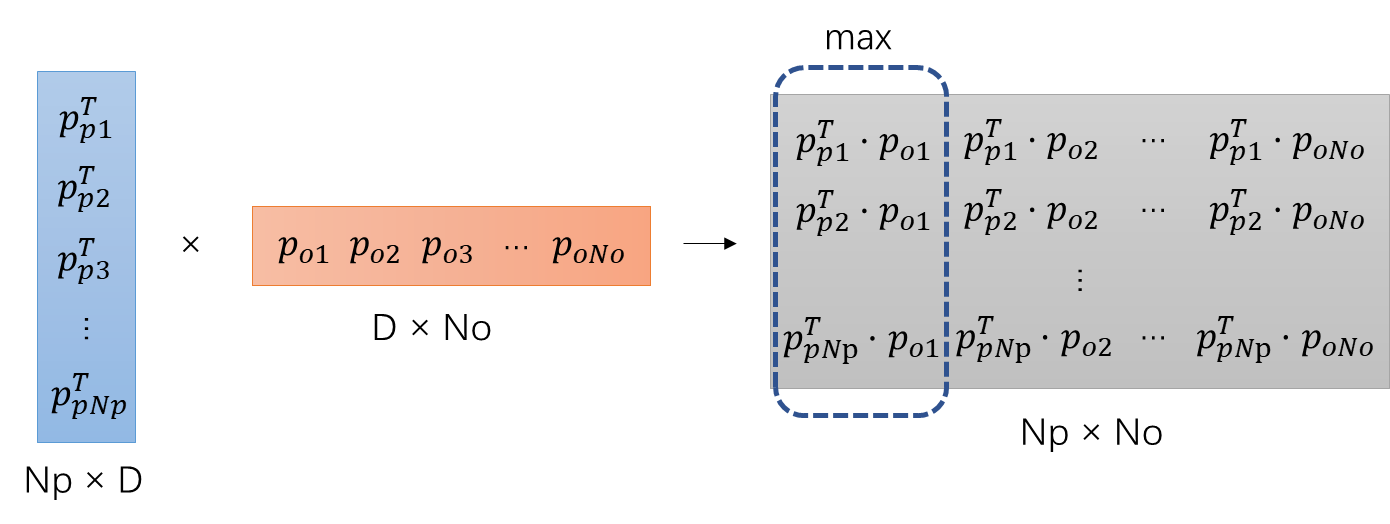
Pp与Po相乘以后,得到的矩阵首先按列取最大值,得到下面的矩阵:
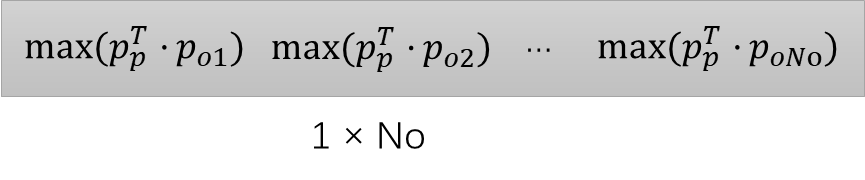
它的含义是,对于每个对象原型![]() ,其与短语原型的最大相似度。
,其与短语原型的最大相似度。
然后,对于每个关键帧都有一个上述的矩阵,在跨帧之间再取对于每个对象原型与短语原型的最大相似度,从而得到置信度更高的对象-短语匹配分数:
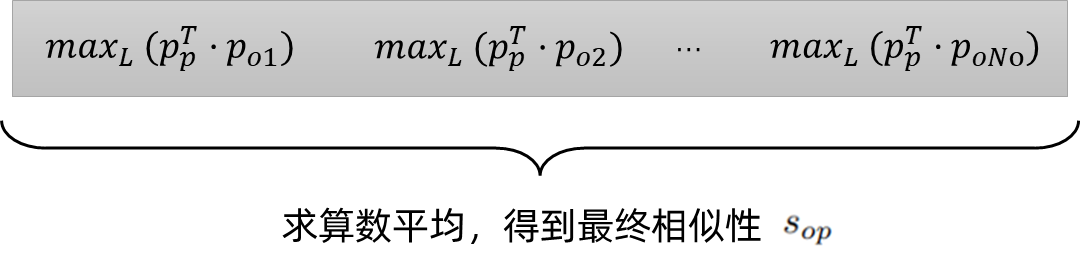
方法 – 事件句子原型匹配
接下来,到了事件句子原型匹配阶段。
时间原型生成 Temporal Prototype Generation(TPG)
直接基于全局帧特征获得视频级特征会导致模型不能感知局部细节,并且只能得到单一的视频级特征。
作者团队提出一种渐进式的方法,逐步将对象原型聚合到帧原型中,然后进行帧间交互,以生成各种事件原型。
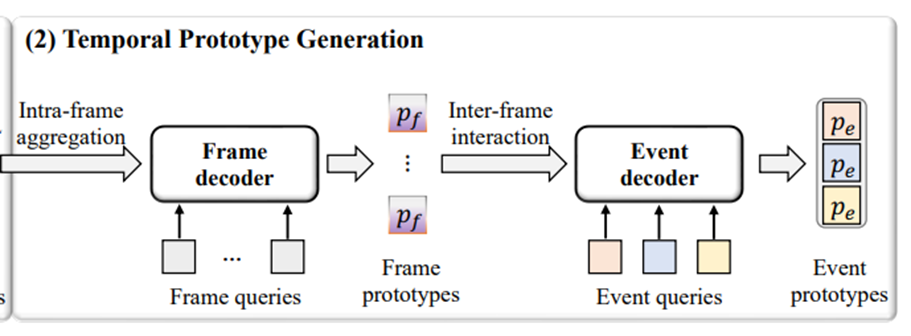
首先设计一个帧解码器,将所有对象原型![]() 聚合到帧级原型
聚合到帧级原型![]() 中:
中:
![]()
其中,![]() 是帧Query(Learnable),Ko和Vo是对象原型Po的线性变换后的特征。
是帧Query(Learnable),Ko和Vo是对象原型Po的线性变换后的特征。
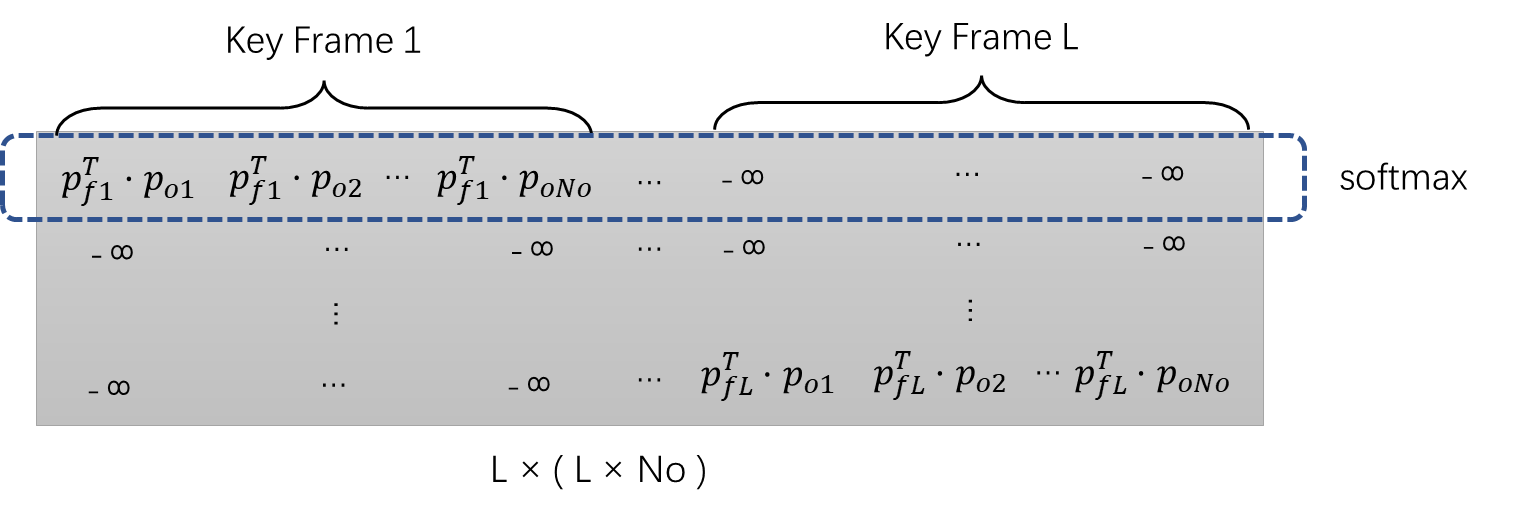
注意力掩码![]() 的定义是:
的定义是:
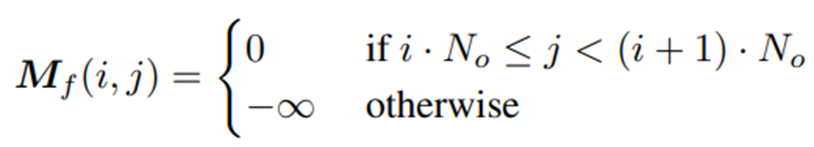
这一部分的矩阵处理细节如下所示:


注意观察Mf与![]() 的关联,可以理解它的作用是使得注意力仅存在于同一帧的对象原型之间,从而不受到其他帧的对象原型的干扰。
的关联,可以理解它的作用是使得注意力仅存在于同一帧的对象原型之间,从而不受到其他帧的对象原型的干扰。

![]()
Softmax后的权重再乘以对应帧的𝑣𝑜,从而得到帧原型矩阵Pf,形状为(L × D)
后面使用全局帧信息Qf进行一个Residual Connection。
将帧原型pf和相应帧的原始全局特征xc相加,以增强模型的稳健性:![]()
然后,使用一个动态事件解码器来学习Pf中的帧间关系,它可以获得不同的事件原型![]() 来展示视频的丰富信息。
来展示视频的丰富信息。
其中,![]() 是事件Query(Learnable),Kf和Vf是帧原型Pf的线性变换后的特征。
是事件Query(Learnable),Kf和Vf是帧原型Pf的线性变换后的特征。
在训练过程中,每个事件Query都学习如何自适应地聚焦于视频帧原型,而多个Query隐含地保证了一定的事件多样性。
事件句子匹配 Event-Sentence Matching
由于同一个视频通常对应多个文本语义描述,我们直接使用全局文本表示yE作为句子原型与事件原型Pe进行对齐,找到句子原型与事件原型的最大相似度,作为最终的相似性Ses:
![]()
方法 – 训练与推断
训练阶段
采用InfoNCE损失函数来优化batch内的原型匹配。将文本-视频对视为正样本,同时考虑batch内的其他成对组合作为负样本:
![]()
其中,Sop、Ses分别为来自 对象短语原型匹配 和 事件句子原型匹配阶段 的 对象-短语原型相似度 和 句子-事件原型相似度 。

推理阶段
直接对最终相似度匹配加权了时空匹配得分:![]()
其中![]() 是空间匹配因子。
是空间匹配因子。
实验 – 评价指标与结果
Recall@K (R@K)
这个指标衡量在前K个检索结果中正确匹配的比例。
Median Rank (MdR)
中位数排名指标表示正确匹配项在所有检索结果中的中位数排名。
Mean Rank (MnR)
平均排名指标表示所有正确匹配项在所有检索结果中的平均排名。
实验 – 消融实验
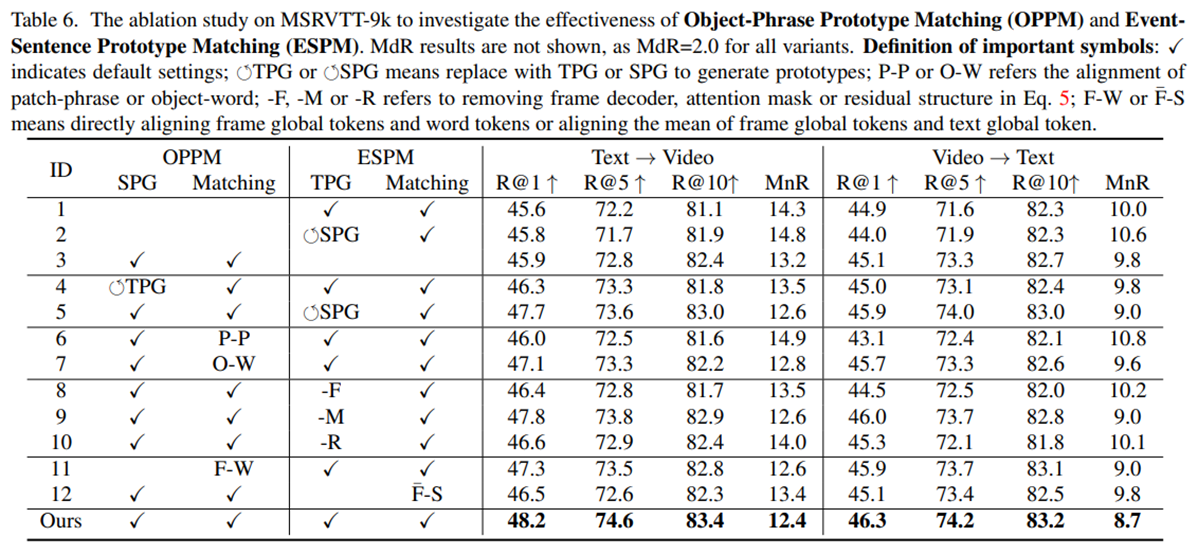
- 只使用ESPM时,R@1下降了2.6个点,证实了细粒度空间细节对于ESPM的补充作用。
- 只使用OPPM时,模型性能仍然较差,因为其缺乏对时间的理解,无法解决关系模糊性。
- 将SPG替换为TPG,性能下降说明了原始视频标记中存在冗余,SPG能够有效地过滤冗余信息。
- 将TPG替换为SPG,性能下降说明了帧间信息的交互对于生成更好得到事件原型是很重要的
- -F、-M、-R(移除帧解码器、attention mask、残差连接)的结果下降,表明帧内的局部对象关系和全局帧特征共同补充了全面的帧级空间信息。
- P-P、O-W(使用patch-phrase或object-word,而不是原型)表明使用原型匹配能减缓模态对齐问题。
- F-W、F-S(直接使用CLS或直接使用平均池化获得帧token)会影响信息的细节,从而降低性能。
- 在原型数量的设置上,也进行了实验,最后确定了最好的原型配置。表明在原型太多时会引入局部噪音,而太少时则无法表达语义。
- 同时也针对空间匹配因子β做了测试,找到了最合适的β值。表明需要同时合理地利用底层细粒度的空间信息和时间原型匹配,才能得到好的结果。
实验 – 定性分析
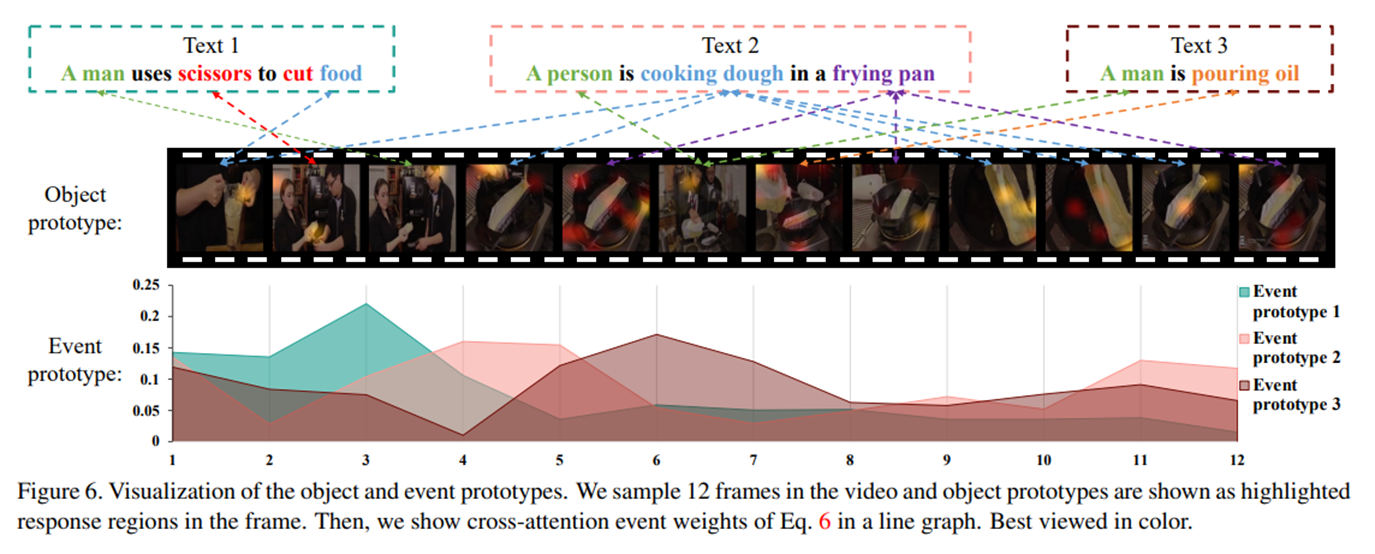
原型可视化
通过对象原型和时间原型的可视化图片,可以看见它们之间具体的匹配关系。可以看到不同的事件原型在不同帧上的权重差异很大,说明模型能够学习到时间关系。

检索结果
通过举例分析说明了对象-短语原型匹配提供了重要的细粒度空间知识,从而能够给出更好的查询结果。
总结
提出了一种新颖的文本-视频检索框架,称为ProST,将匹配过程分解为互补的对象-短语和事件-句子原型对齐。
在对象-短语原型匹配阶段,设计了空间原型生成机制,以便专注于重要的视频内容并加强精细的空间对齐。
在事件-句子原型匹配阶段,他们使用时间原型生成机制逐渐生成多样化的事件原型,并学习动态的一对多关系。
希望通过这篇论文不仅能够提供有关互补的时空匹配的重要性的见解,还能够促进未来的研究,通过解决设计缺陷而不是主要是尝试和错误来推动文本-视频检索领域的进展。
个人感受
读完这篇文章,唯一的感觉就是太花了,实在是太花了。学习之路任重而道远!
这篇关于【论文阅读】Progressive Spatio-Temporal Prototype Matching for Text-Video Retrieval的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








