本文主要是介绍行为识别 - STH: Spatio-Temporal Hybrid Convolution for Efficient Action Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 前言
- 1. 要解决什么问题
- 2. 用了什么方法
- 3. 效果如何
- 4. 还存在什么问题
0. 前言
- 相关资料:
- arxiv
- github:可能等不到开源啦
- 论文解读
- 论文基本信息
- 领域:行为识别
- 作者单位:西安交大&腾讯
- 发表时间:2020.3
- 一句话总结:提出同时提取时空特征的结构,根据channel分组、分别进行时间卷积(3x1x1)和空间卷积(1x3x3)、合并结果。
1. 要解决什么问题
- 行为识别模型要解决的就是对空间信息建模(temporal modeling)的问题……
- 还是那些老问题:
- 双流法耗时、占用硬盘。
- 3D卷积计算量太大,2D卷积不能很好的对temporal建模。
- 现在主要都是在模型准确率与模型大小之间做权衡。
2. 用了什么方法
- 提出了Spatio-Temporal Hybrid(STH)block,用于提到普通的卷积操作。
- STH Conv可以同时提取时间与空间信息。
- 2D/3D/(2+1)D/STH 的结构比较
- 这图比较抽象,感觉作者是抽象派画家。
- 毕竟是抽象画,所以可能理解不对,我猜这图的意思是介绍2D-Conv Block/3D-Conv Block/(2+1)D-Conv Block/STH Block 的基本结构。
- 2D-Conv Block:先
1*1*1卷积,再1*3*3卷积,最后1*1*1卷积。 - 3D-Conv Block:先
1*1*1卷积,再3*3*3卷积,最后1*1*1卷积。 - (2+1)D-Conv Block:先
1*1*1卷积,再1*3*3卷积,接着3*1*1卷积,最后1*1*1卷积。 - STH Block:先
1*1*1卷积,再同时进行1*3*3/3*1*1卷积,最后1*1*1卷积。
- 2D-Conv Block:先

- 所谓的 Temporal Convolution、Spatial Convolution 在本图中有说明。
- 输入特征图尺寸一般为
N, T, C, H, W - 所谓Temporal Convolution就是在
T通道上进行特征融合(T通道卷积核尺寸为3,H, W通道卷积核尺寸为1) - 所谓Spatial Convolution就是对
H, W通道进行特征融合(H, W通道卷积核尺寸为3,T通道卷积核尺寸为1)
- 输入特征图尺寸一般为
- STH结构介绍
- 图中 H, W 合并为一个维度。
- Spatio-Temporal Hybrid Convolution,翻译成中文应该是 时空混合卷积。
- 也就是说,在一个STH block中,会将一个普通的卷积转换为若干个Temporal/Spatial Convolution,如下图中,一次普通卷积按照
C通道分为4部分,分别进行Temporal/Spatial卷积操作。 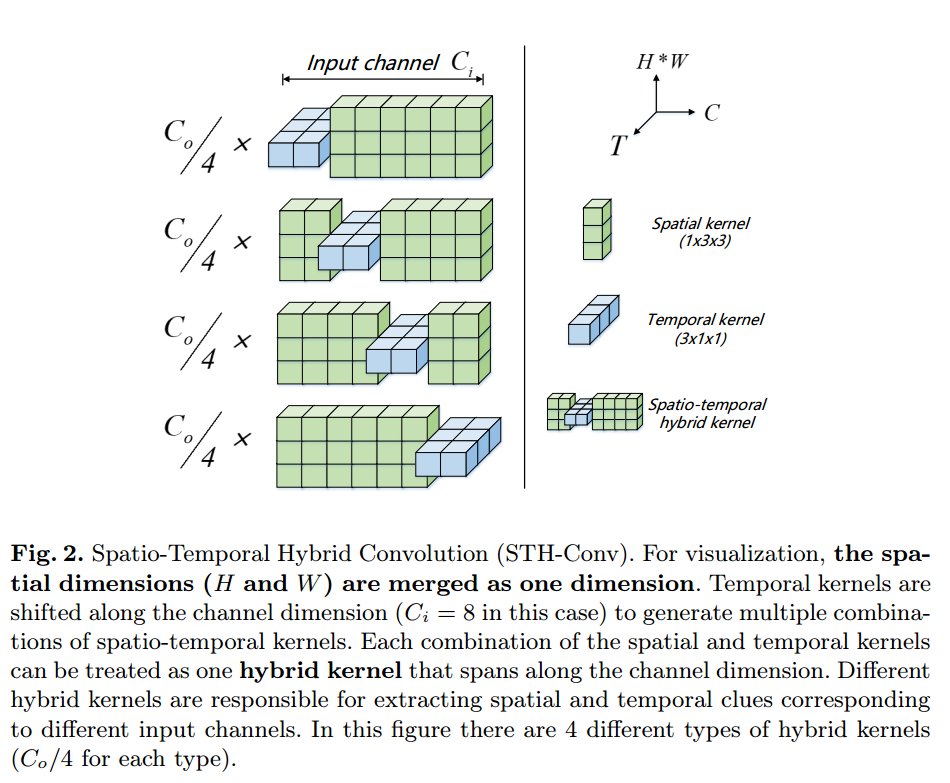
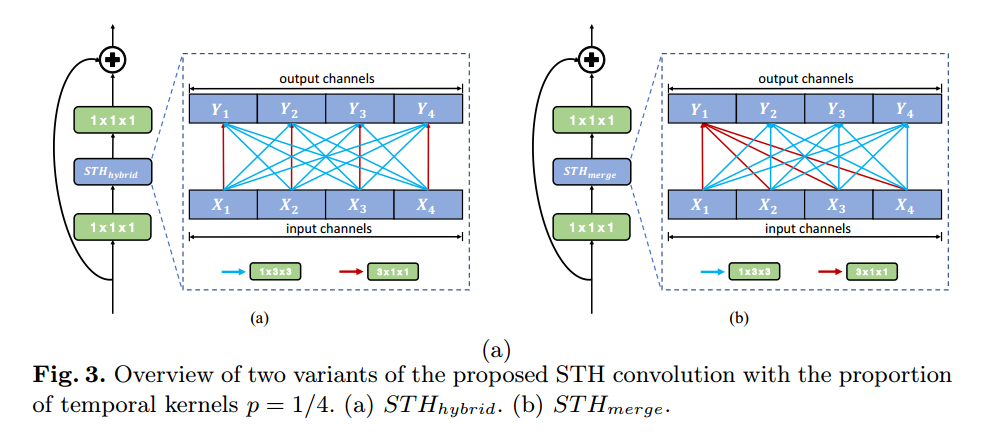
- STH的实现细节
- 上图中给出的STH结构,就是下图的(a)结构。
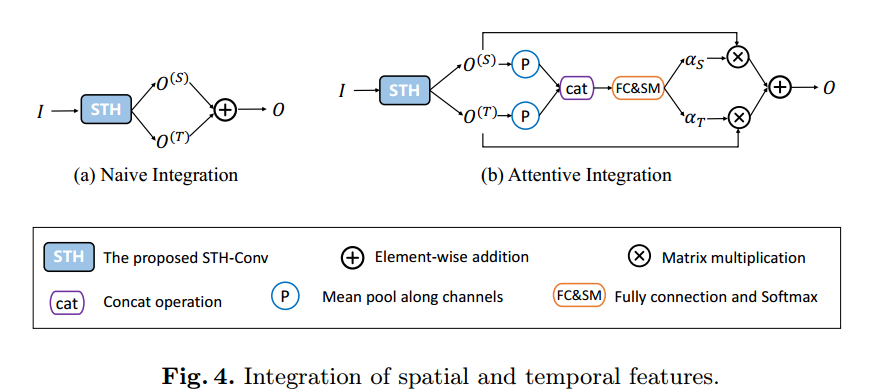
- 如何融合时间、空间特征:
- 普通直接按位加,也可以搞个注意力网络啥的。
- STH的计算效率
- 从FLOPs上看,STH比普通的Spatial Convolution要少一些。

- STH网络
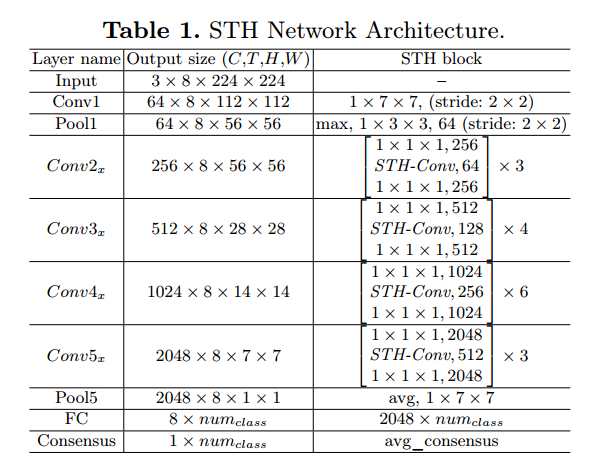
3. 效果如何
- 从模型准确率看,STH与其他SOTA模型差距不大。
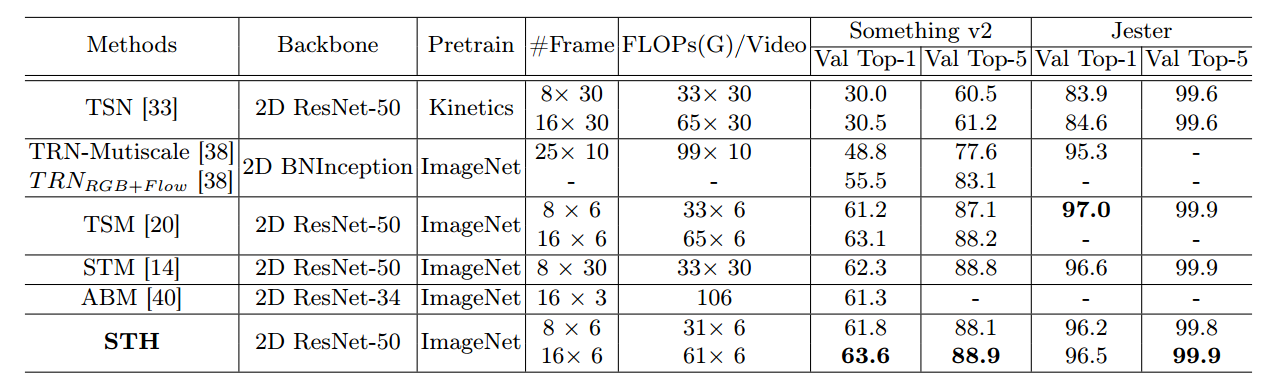
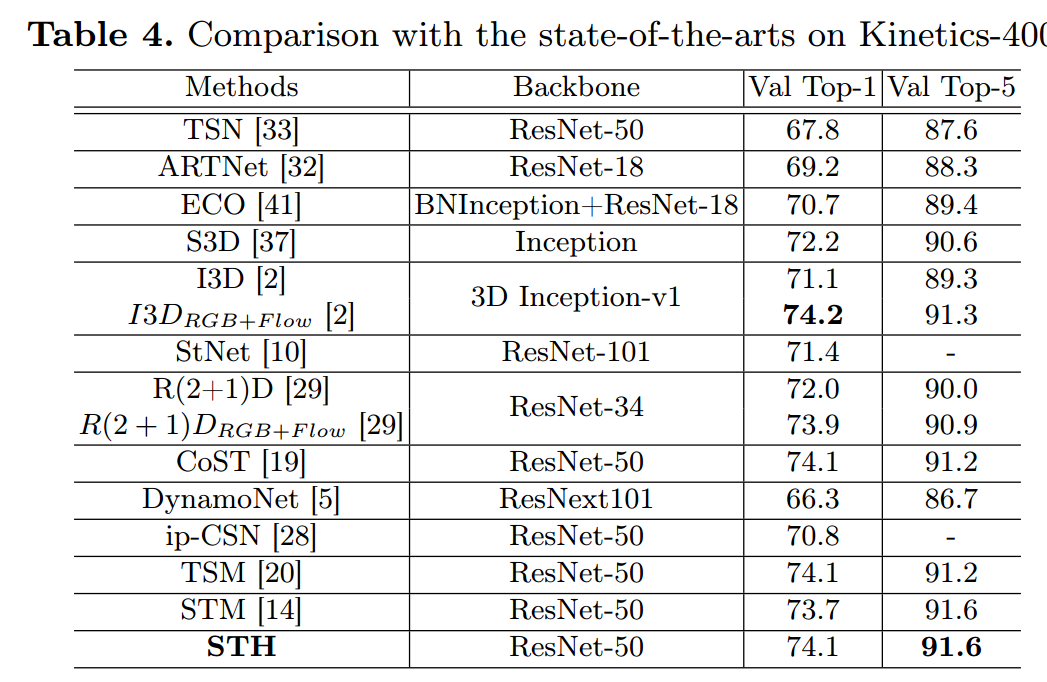
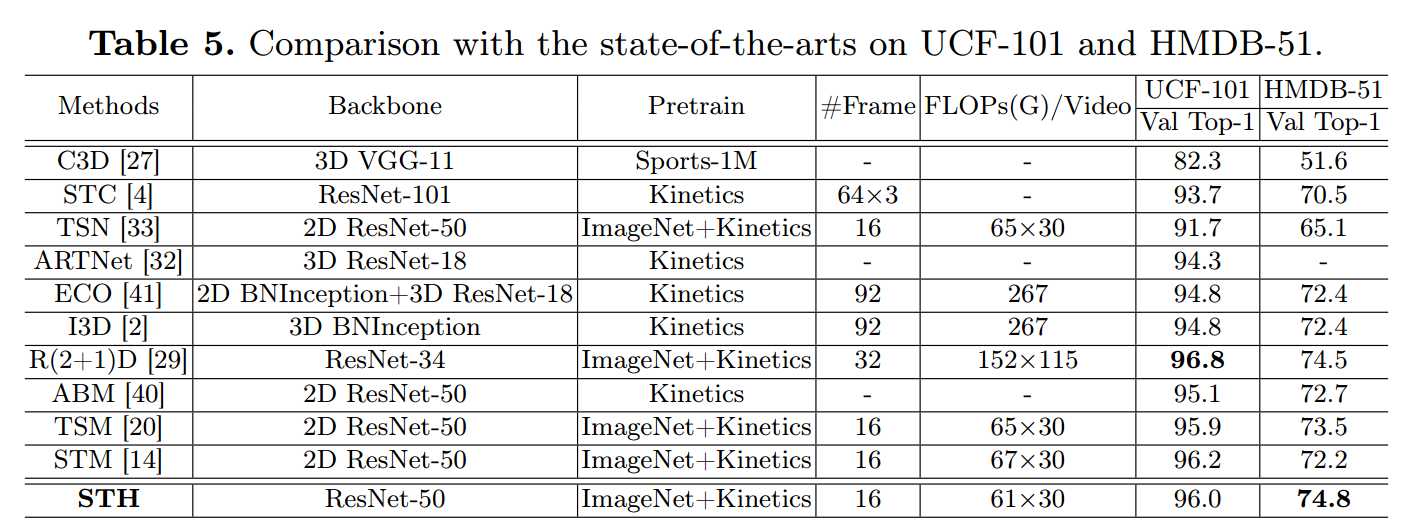
- 这里比较了几个模型在1080ti上的执行效率,感觉对比TSM也没有太大优势。
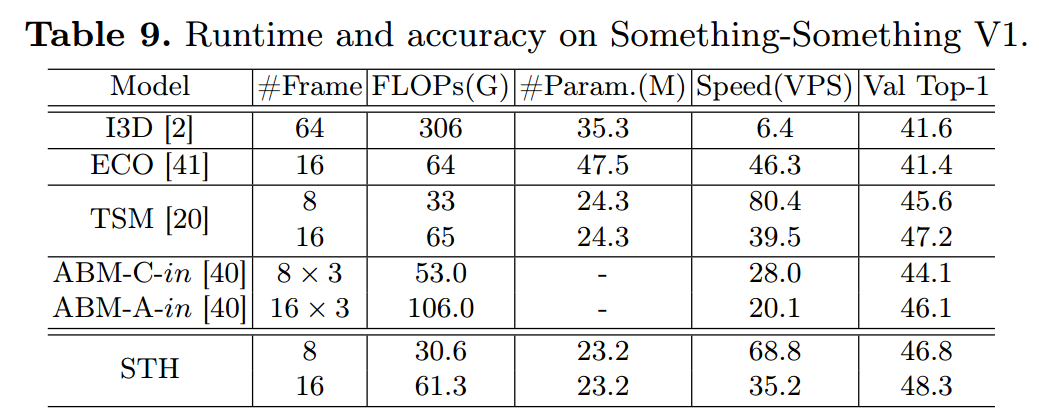
4. 还存在什么问题
- 论文本身的idea挺有意思,但感觉效果好像并没有什么特别之处。
这篇关于行为识别 - STH: Spatio-Temporal Hybrid Convolution for Efficient Action Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






