本文主要是介绍ST-GRAT: A Novel Spatio-temporal Graph Attention Networks for Accurately Forecasting Dynamically Cha,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
研究问题
基于动态空间依赖的交通流预测问题
背景动机
- 传统方法不论是外部输入图结构还是自己学出图结构都假定道路之间的空间依赖关系是固定的,因此它们只计算一次空间依赖关系,并一直使用计算出的依赖关系,而不考虑动态变化的交通条件。
- 通过注意力机制来建模动态空间依赖的模型往往忽略了图上固有的结构信息
- RNN有不能直接访问长输入序列中的过去的特征的限制,不如attention好
模型思想
- 空间注意力模块:使用了作者提出的扩散先验、有向头和基于距离的嵌入,以通过捕捉道路速度变化和图形结构信息来建模空间依赖性
- 时间注意力模块:使用注意力直接访问输入序列遥远的相关特征,有效地捕捉突然波动的时间动态
- 空间哨兵模块:在哨兵向量的指导下,动态决定使用其他道路的新信息或关注现有的编码特征,避免使用对预测没有帮助的不相关道路
符号定义
- 输入图的表示: G = ( V , E , A ) \mathcal{G}=(\mathcal{V}, \mathcal{E}, \mathcal{A}) G=(V,E,A)
- 输入特征的表示: X ( t ) ∈ R N × 2 X^{(t)} \in \mathbb{R}^{N \times 2} X(t)∈RN×2,2个特征分别是车速和时间戳
- 目标:以图 G \mathcal{G} G和 X = [ X ( t − T + 1 ) , ⋯ , X ( t ) ] X=\left[X^{(t-T+1)}, \cdots, X^{(t)}\right] X=[X(t−T+1),⋯,X(t)]为输入,预测 Y = [ X : , 0 ( t + 1 ) , ⋯ , X : , 0 ( t + T ) ] Y = \left[X_{:, 0}^{(t+1)}, \cdots, X_{:, 0}^{(t+T)}\right] Y=[X:,0(t+1),⋯,X:,0(t+T)]
模型结构
- 整体框架为下图所示的encoder-decoder架构,其中左半深色部分为编码器,右半深色部分为解码器
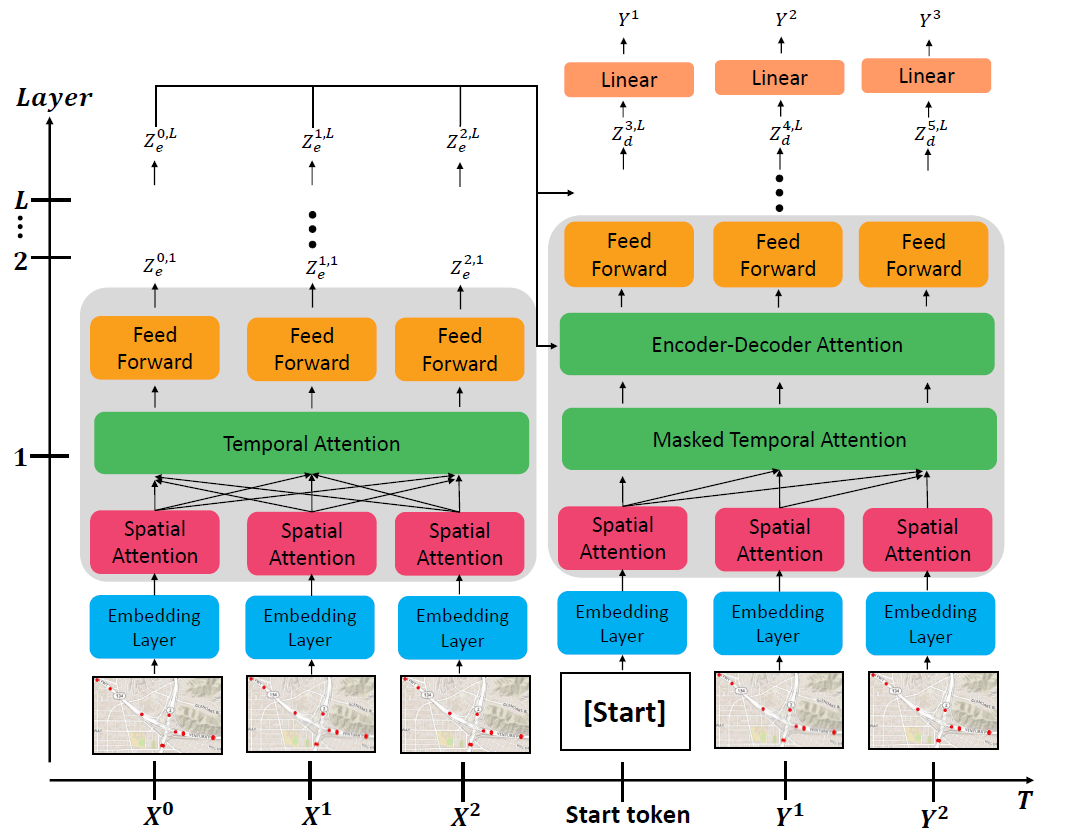
- 编码器结构
- 单个编码器层由三个子层顺序构成:空间注意层、时间注意层和前馈神经网络。空间注意层在每个时间步长关注与中心节点在空间上相关的邻居节点;时间注意层关注单个节点及给定输入序列的不同时间步长;前馈神经网络融合两层的信息获取高阶特征
- 编码器采取了skip connection、layer normalization、dropout来增强泛化性能
- 嵌入层
- 为了考虑节点距离信息,使用预训练好的Line模型计算节点嵌入特征
- 使用Transformer的方法计算节点的位置编码向量
- 将这两部分结果与节点的原始特征拼接起来
- 空间注意力模块
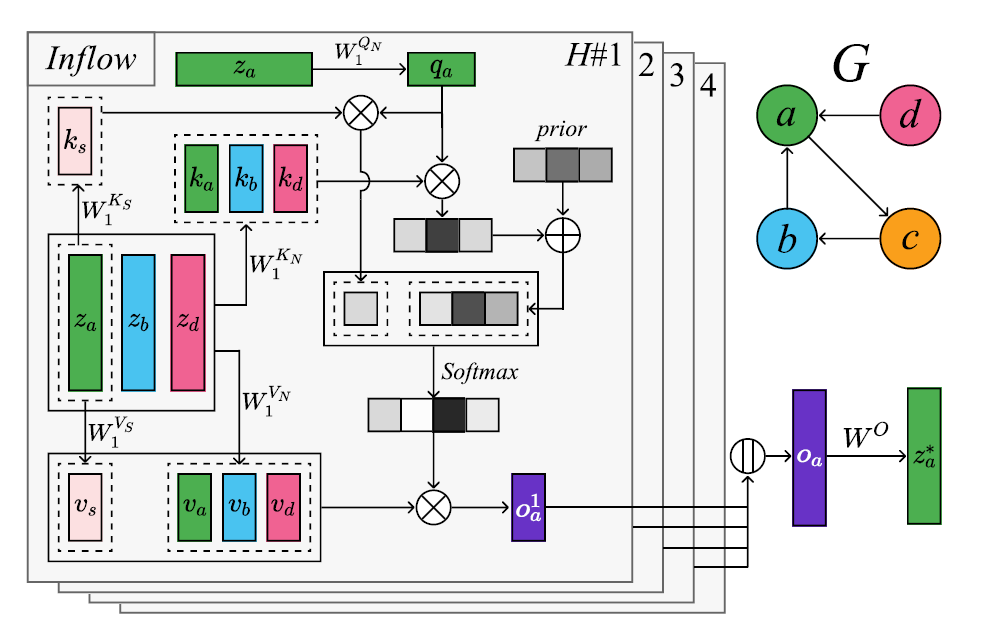
- 分别对流入和流出节点应用注意力机制,从而对方向进行建模
- 结构上采取了类似transformer的多头注意力机制
- 使用哨兵向量来过滤无关节点
- 时间注意力模块
没有详细解释,也是采用了和空间注意力模块一样的多头注意力机制,去除了哨兵向量
- 解码器结构
和编码器结构相似,不同是利用masked attention layer限制注意现在和过去的信息;encoder-decoder attention layer同时从编码器输出和masked attention laye的输出中提取信息
实验部分
- 对比实验
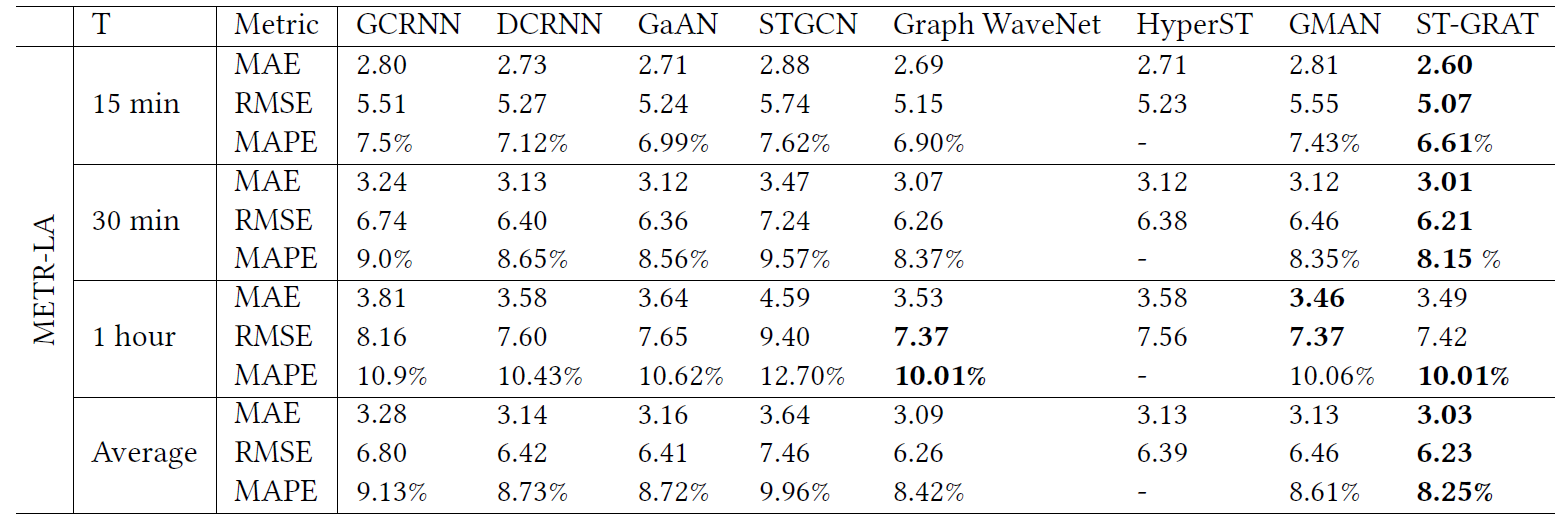
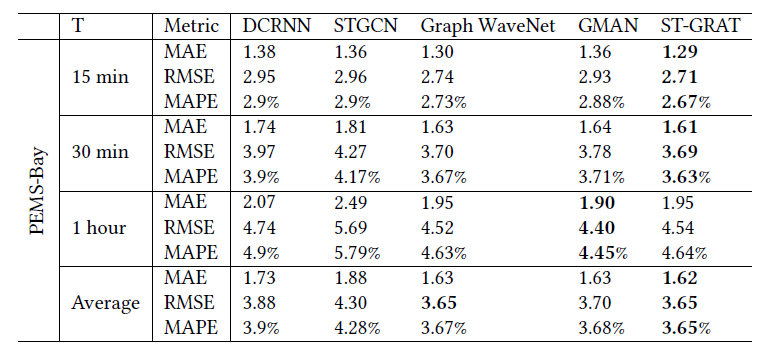
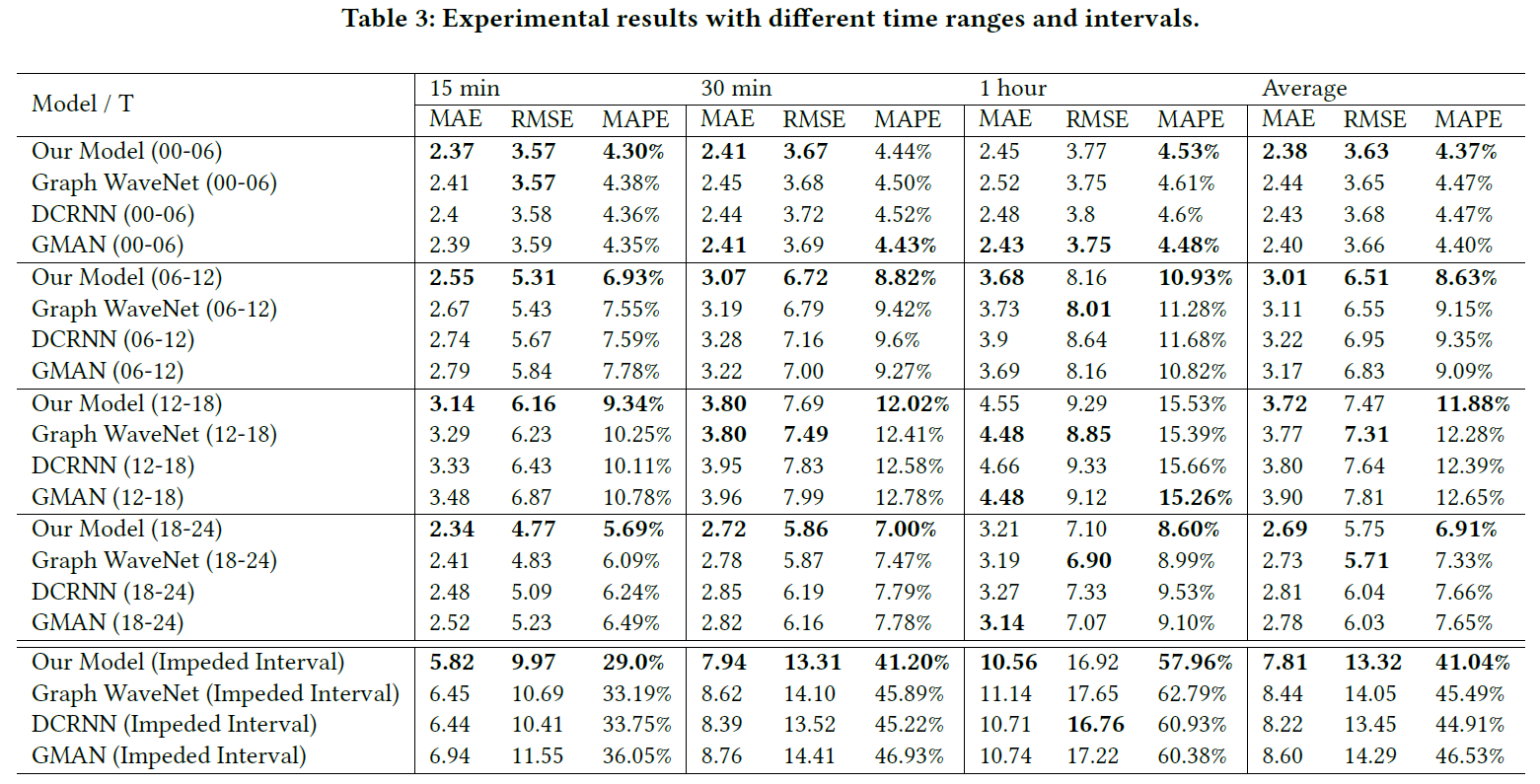
在总体的对比实验之后,还在不同时间段以及速度快速变化的时间段比较了模型的预测效果
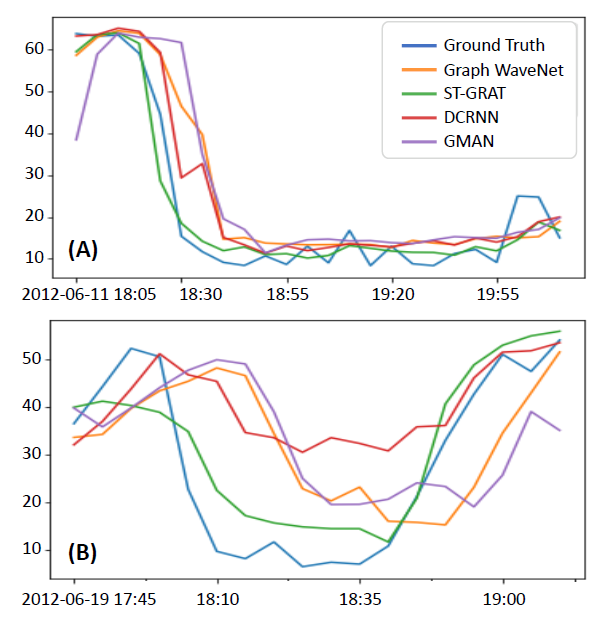
- 消融实验
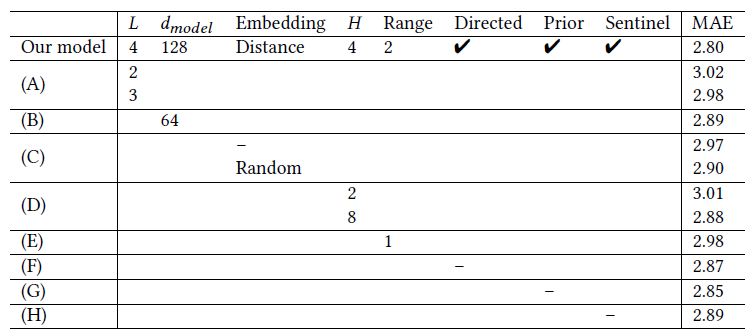
结果表明网络层数越多、隐藏向量维数越高、注意力头数越多、邻居节点的范围越大、使用哨兵向量都有助于提高模型性能。同时,通过比较不同的嵌入设置,可以观察到邻近信息几乎不影响模型的性能
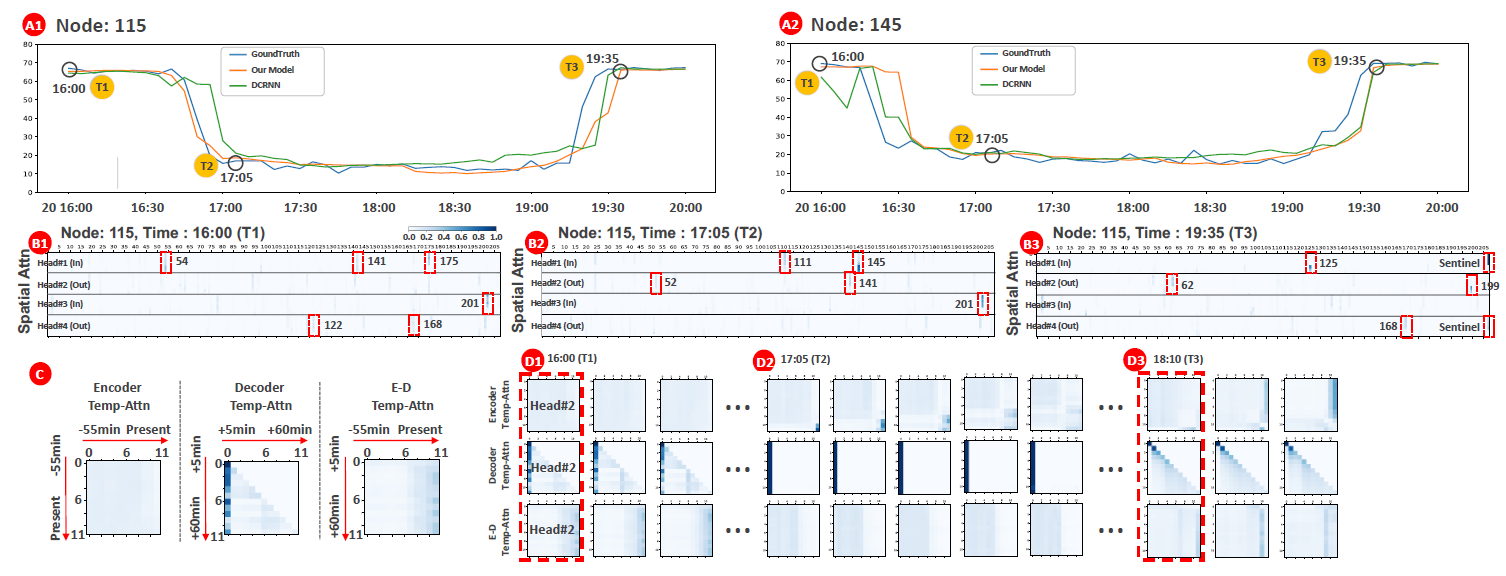
- 可解释性
主要是对着注意力热图一阵分析
评价
感觉这篇论文最主要的出发点就是把transformer应用到交通流预测上去,动态空间依赖的建模方式依然是使用attention,只不过输入里面加入了包含空间结构信息的嵌入。
这篇关于ST-GRAT: A Novel Spatio-temporal Graph Attention Networks for Accurately Forecasting Dynamically Cha的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






