本文主要是介绍【MOTS】Learning a Spatio-Temporal embedding for video instance segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Purpose
把特征映射到高维做聚类,加上自监督的训练得到的图片的Depth信息结合来做VIS
Pipline
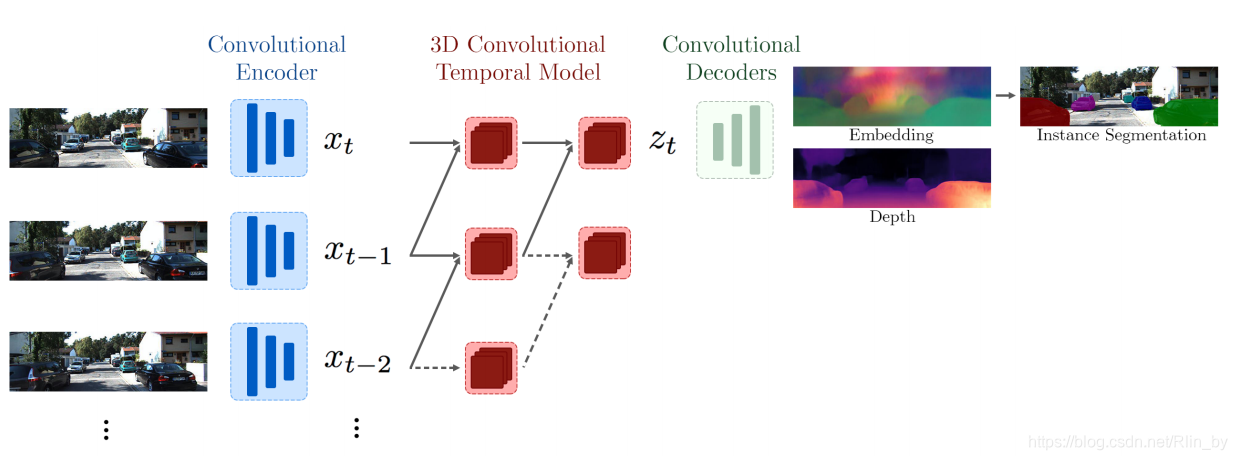
用ResNet18作为Encoder,得到每一帧的feature x_t;然后用3D卷积,把前后两者特征再滤波得到z_t;z_t通过Decoder(2个分支,每个分支7层卷积,3个upsample,Embedding分支的output通道数为p,Depth通道数为1)
训练时计算作者设计的loss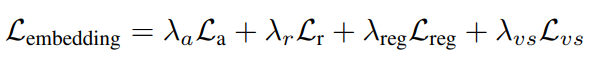
inference等会再说
Loss
首先看前面三项,是针对Embedding的分支。具体如下:
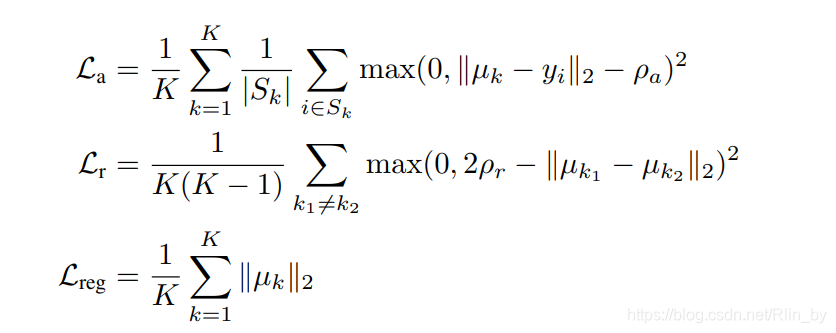
La是让每个pixel i 的embendding y_i更接近其类别中心μ_k;
Lr是让不同类的中心离得更远,也即不同instance更分离;
Lreg是一个正则项。
在看Depth分支,具体计算参考https://blog.csdn.net/weixin_41024483/article/details/87992248
主旨就是通过把当前帧重建到源帧(比如前一帧),再用重建的源和源做对比进行优化,进而间接的优化Depth。
这个loss如下:
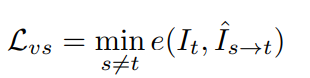
最后把两个分支loss相加得到最终loss
Inference
对于每一个新的帧,我们首先使用mask network生成背景mask,然后使用mean shift对前景embedding进行聚类,发现每个簇对应一个实例的密集区域。跟踪实例只需要比较新分割实例与以前分割实例的mean embedding。小于ρr的距离表示匹配。
这篇关于【MOTS】Learning a Spatio-Temporal embedding for video instance segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







