mots专题
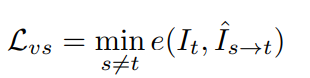
【MOTS】Learning a Spatio-Temporal embedding for video instance segmentation
Purpose 把特征映射到高维做聚类,加上自监督的训练得到的图片的Depth信息结合来做VIS Pipline 用ResNet18作为Encoder,得到每一帧的feature x_t;然后用3D卷积,把前后两者特征再滤波得到z_t;z_t通过Decoder(2个分支,每个分支7层卷积,3个upsample,Embedding分支的output通道数为p,Depth通道数为1)