本文主要是介绍论文翻译 SGCN:Sparse Graph Convolution Network for Pedestrian Trajectory Prediction 用于行人轨迹预测的稀疏图卷积网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SGCN:Sparse Graph Convolution Network for Pedestrian Trajectory Prediction 用于行人轨迹预测的稀疏图卷积网络
行人轨迹预测是自动驾驶中的一项关键技术,但由于行人之间复杂的相互作用,该技术仍具有很大的挑战性。
然而,以往基于密集无向交互的研究存在建模冗余交互和忽略轨迹运动趋势等问题,不可避免地与实际存在较大偏差。
针对这些问题,我们提出了一种用于行人轨迹预测的稀疏图卷积网络(SGCN)。
具体来说,
- SGCN明确地使用稀疏有向空间图对稀疏有向交互进行建模,以捕获自适应交互行人。
- 同时,我们使用一个稀疏的有向时间图来建模运动趋势,从而便于基于观测方向进行预测。
- 最后,将上述两种稀疏图融合在一起,估计了用于轨迹预测的双高斯分布的参数。
我们在ETH和UCY数据集上对我们提出的方法进行了评估,实验结果表明,我们的方法在平均位移误差(ADE)和最终位移误差(FDE)上分别比目前最先进的方法高出9%和13%。值得注意的是,可视化表明,我们的方法可以捕捉行人之间的自适应互动和他们的有效运动趋势。
1. Introduction
在已知行人轨迹的情况下,行人轨迹预测的目的是预测行人未来的位置坐标序列,在自动驾驶[3,29]、视频监控[28,45]、视觉识别[9,27,16]等应用中发挥着关键作用。尽管最近的文献取得了进展,但由于行人之间复杂的相互作用,行人轨迹预测仍然是一项非常具有挑战性的任务。例如,一个行人的运动很容易受到其他行人的干扰,亲密的朋友或同事可能会集体行走,不同的行人通常会进行相似的社会行为。
为了对行人之间的相互作用进行建模,在过去的几年里进行了大量的工作[31, 2, 11, 23, 19, 32, 46] ,其中按距离加权方法[31, 2, 11, 32]和基于注意力的方法[23, 19, 46, 8, 17, 18]在行人轨迹预测方面取得了最先进的结果。
大多数基于距离加权和注意力的方法采用密集交互模型来表示行人之间的复杂交互,其中假设行人与所有其他行人交互。(问题1)
此外,距离加权法采用相对距离来建模无向交互,其中两个行人的交互是相同的。然而,我们认为密集的交互和无定向的交互都会导致行人之间的多余交互。(问题2)

如图1所示:(1)两对行人从相反的方向前进,只有红色行人的轨迹绕行,避免与绿色行人相撞;
(2)蓝色和黄色行人的轨迹不相互影响。很明显,基于密集或稀疏无向交互的方法将无法处理这种情况下的交互。
例如,如A.1所示,密集的无向交互会在黄色和蓝色的行人之间产生多余的交互,因为黄色和蓝色的行人的轨迹不会相互影响。此外,稀疏的无向交互,
如A.2所示,由于红色行人绕道以避免与绿色行人碰撞,而绿色行人则直接向前走,导致绿色行人与红色行人之间产生了多余的交互。
为了解决上述问题(多余的交互),最好设计一种稀疏有向交互(Sparse Directed Interaction),
如a .3所示,它可以在行人轨迹预测中与自适应行人交互。
此外,由于以往的工作侧重于避碰,导致预测的轨迹往往会生成绿色和红色的行人避碰的绕行轨迹,
如B.1所示,而绿色的行人偏离了地面真实。在这种情况下,我们提出运动趋势,
该运动趋势由B.2中蓝色虚线圈所包围的短期轨迹表示,绿色行人的轨迹方向为直线前进,红色行人的轨迹方向偏转以避免与绿色行人的碰撞。基于轨迹方向不会突然变化的假设,运动趋势有利于绿色行人的预测。需要注意的是,运动趋势是万能的,
如B.3所示,最后一种运动的表现要比其他的好,因为它可以共同捕捉“笔直向前”和“暂时偏离”的趋势。一旦找到有效的中间点集合,运动趋势将有助于行人轨迹预测。
在本文中,我们提出了一种新的稀疏图卷积网络(SGCN),它将稀疏有向交互和运动趋势相结合,用于行人轨迹预测。
如图1 (A+B)所示,稀疏有向交互发现有效影响特定行人轨迹的行人集合,运动趋势改善交互行人的未来轨迹。
其中,如图2所示,我们联合学习了稀疏有向空间图和稀疏有向时间图,对稀疏有向交互和轨迹运动趋势进行建模。

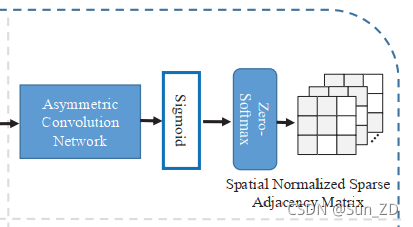
如图3所示,稀疏图学习利用自注意[40]机制来学习轨迹点之间的非对称密集和定向交互得分。
然后,将这些交互得分融合并反馈到非对称卷积网络中,获得高层交互特征。
最后,利用常数阈值和“Zero-Softmax”函数的归一化步骤对冗余交互进行修剪,得到一个稀疏有向空间和稀疏有向时间邻接矩阵。
最后得到的非对称归一化稀疏有向邻接矩阵可以表示稀疏有向图。一旦得到上述两个图,我们进一步学习由图卷积网络[22]级联的轨迹表示,并使用时间卷积网络[4]估计双高斯分布的参数,用于生成预测的轨迹。
在 eth [34]和 ucy [24]数据集上的大量实验结果表明,我们的方法优于所有最先进的比较方法。
据我们所知,这是第一个明确建立相互作用和运动倾向模型的工作。
总之,我们的贡献是三方面的:
(1)我们提出了 解析有向交互和运动的方法来改进预测的轨迹;
(2)我们设计了一种自适应的方法来模拟稀疏有向交互和运动趋势;
(3)我们提出了一个稀疏图卷积网络来学习轨迹表示,并通过实验验证了显式稀疏性的优点。
2. Related Works
Pedestrian Trajectory Prediction.
由于其强大的表征能力,深度学习在预测行人轨迹方面越来越流行。Social-LSTM[1]利用循环神经网络(rnn)[14,20,6]对每个行人的轨迹进行建模,并从集合的隐藏状态计算一定半径内行人之间的交互作用。SGAN[11]利用生成式对抗网络(GAN)预测多模态轨迹[10,48,5],并提出了一种基于行人相对距离计算交互的新的池化机制。TPHT[30]通过一个LSTM来表示每个行人,并采用软注意机制[42]来模拟行人之间的交互。此外,后续的工作利用场景特征来提高预测精度。PITF[26]考虑了人-场景交互和人-对象交互。sophie[37]通过双向注意机制提取场景特征和社会特征,并计算具有社会注意的所有代理的权重。TGFP[25]利用场景信息预测粗点和细点位置。
由于图结构可以更好地贴合场景,另一种作品轨迹使用图来模拟人与人之间的互动。Social-BiGA T[23]使用LSTM模型模拟每个行人的轨迹,并通过图注意网络(GAT)[41]模型模拟交互作用。
为了更好地表示行人之间的互动,Social-STGCNN[32]直接将轨迹建模为一个图形,其中以行人相对距离加权的边表示行人之间的互动。
RSGB[38]注意到一些远距离的行人对之间有很强的互动,因此邀请社会学家根据具体的物理规则和社会行为手动将行人划分为不同的组。
STAR[46]通过Transformer[40]框架对空间交互和时间依赖进行建模。
简而言之,之前的研究为固定物理范围内的邻里之间的互动建模,要么对所有的行人。据推测,由于多余的相互作用,这可能会导致预测的差异。
相反,我们提出了稀疏定向交互,能够找到参与交互的自适应行人,从而缓解这一问题。此外,我们的方法还捕获了有效的运动趋势,这有助于提高预测轨迹的准确性
Graph Convolution Networks.
现有的 gcn 模型可以分为两类:
1)频谱域 gcns [22,7]设计基于图傅里叶变换的卷积运算。它要求邻接矩阵是对称的,由于 Laplacian Matrix 的特征分解;
2)空间域的 gcns 直接在边上进行卷积,这适用于非对称的邻接矩阵。
例如,graphsage [12]以三种不同的方式聚合节点,并以不同的顺序融合相邻节点以提取节点特征。
Gat [41]使用注意力机制模拟节点之间的相互作用。
为了处理时空数据,stgcn [43]将空间 gcn 扩展到时空 gcn,用于基于骨架的动作识别,从局部时空域聚集节点。
我们的 sgcn 不同于以上所有的 gcn,因为它基于一个学习的稀疏邻接矩阵聚合节点,这意味着要聚合的节点集是动态确定的。
Self-Attention Mechanism.
Transformer[40]的核心思想,即自我关注,已经成功地在自然语言处理中的一系列序列建模任务中,如文本生成[44]、机器翻译[35]等,取代了rnn[20,6]。自注意将注意解耦到查询、键和值中,从而可以捕获长期依赖关系,并利用与rnn相比的并行计算优势。为了表示输入序列中每一对元素之间的关系,自我注意通过查询和键之间的矩阵乘法计算注意得分。
在我们的方法中,我们只计算一个单层的注意得分模型稀疏定向交互和运动倾向。与最近通过叠加变压器块(计算和内存开销大的[15])预测未来轨迹的[46]相比,我们的方法具有参数高效和性能更好的特点。
3. Our Method
如上所述,现有的作品受到稠密无向图的过度交互的困扰。同时,他们也忽略了可利用的运动趋势线索。为了缓解这些局限性,我们提出了一种用于轨迹预测的稀疏图卷积网络(SGCN),该网络主要涉及稀疏图学习和基于轨迹表示的双高斯分布参数估计。
该网络的总体架构如图2所示。
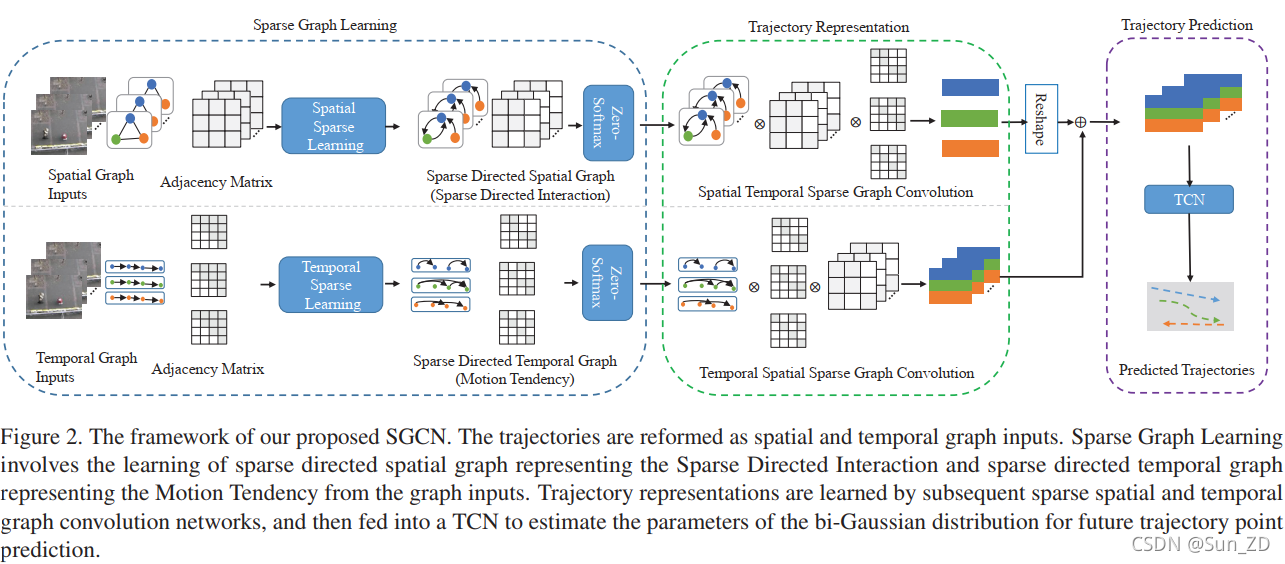
1.首先,分别利用自注意机制和非对称卷积网络从空间图和时间图输入中学习稀疏有向交互(SDI)和运动趋势(MT)。
2.然后利用稀疏时空图卷积网络从表示稀疏有向空间图(SDI)和稀疏有向时间图(MT)的非对称邻接矩阵中提取交互和趋势特征。
3.最后,将学习轨迹表示输入时间卷积网络(TCN) ,预测双高斯分布的参数,生成预测轨迹。
3.1. Sparse Graph Learning稀疏图学习
1.Graph Inputs.
给定的输入轨迹 X i n ∈ R T o b s × N × D X_{in}\in\mathbb{R} ^{T_{\mathrm{obs}} \times N \times D} Xin∈RTobs×N×D
其中D表示空间坐标的维数,N为行人数
我们构造了一个空间图和一个时间图,如图3所示,
时间步长t处的空间图 G s p a = ( V t , U t ) G_{\mathrm{spa}}=\left(V^{t}, U^{t}\right) Gspa=(Vt,Ut)表示行人的位置,而行人n处的时间图 G t m p = ( V n , U n ) G_{\mathrm{tmp}}=\left(V_{n}, U_{n}\right) Gtmp=(Vn,Un)表示相应的轨迹。
V t = { v n t ∣ n = 1 , … , N } V^{t}=\left\{v_{n}^{t} \mid n=1, \ldots, N\right\} Vt={vnt∣n=1,…,N}和
V n = { v n t ∣ n = 1 , … , T o b s } V_{n}=\left\{v_{n}^{t} \mid n=1, \ldots, T_{obs}\right\} Vn={vnt∣n=1,…,Tobs}
代表 G s p a 和 G t m p G_{spa}和G_{tmp} Gspa和Gtmp的节点
v n t v_{n}^{t} vnt的属性是第n个行人在时间步长为t时的坐标 ( x n t , y n t ) (x^t_n,y^t_ n) (xnt,ynt)。
U t 和 U n U^t和U_n Ut和Un
代表 G s p a 和 G t m p G_{spa}和G_{tmp} Gspa和Gtmp的边:
连接(表示为1)或不连接(表示为0)。
由于节点之间的连接没有先验知识,
U n U_n Un 中的元素被初始化为1,
U t U^t Ut 由于时间依赖性被初始化为由1填充的上三角矩阵,即当前状态与未来状态无关。
2.Sparse Directed Spatial Graph.(稀疏有向空间图)
为了增加空间图输入的稀疏性,即在空间图中准确识别出参与交互的行人集合,我们首先采用自注意机制[40]计算非对称注意评分矩阵,
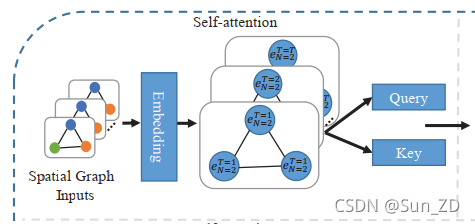
即密集空间交互 行人 R spa ∈ R N × N R_{\text {spa }} \in \mathbb{R}^{N \times N} Rspa ∈RN×N,如下所示:

其中
ϕ ( ⋅ , ⋅ ) \phi(\cdot, \cdot) ϕ(⋅,⋅)表示线性变换
E s p a E_{spa} Espa图形嵌入
Q s p a a n d K s p a Q_{spa} and K_{spa} QspaandKspa分别是自注意机制查询和密钥
W E spa ∈ R D × D E spa , W Q spa ∈ R D × D Q spa , W K spa ∈ R D × D K sa W_{E}^{\text {spa }} \in \mathbb{R}^{D \times D_{E}^{\text {spa }}},W_{Q}^{\text {spa }} \in \mathbb{R}^{D \times D_{Q}^{\text {spa }}}, W_{K}^{\text {spa }} \in \mathbb{R}^{D \times D_{K}^{\text {sa }}} WEspa ∈RD×DEspa ,WQspa ∈RD×DQspa ,WKspa ∈RD×DKsa 是线性变化的权重
d s p a = D Q s p a \sqrt{d_{\mathrm{spa}}}=\sqrt{D_{Q}^{\mathrm{spa}}} dspa=DQspa是一个比例因子[40],以确保数值的稳定性。
- 由于 R s p a R_{spa} Rspa是在每个时间步独立计算的,因此它不包含任何轨迹的时间依赖信息 因此,我们将每个时间步长的密集相互作用 R s p a R_{spa} Rspa叠加为 R s p a s − t ∈ R T o b s × N × N R^{s-t}_{spa}∈R^{Tobs×N×N} Rspas−t∈RTobs×N×N,
- 然后将这些密集相互作用沿时间通道进行1 × 1卷积融合,
- 得到时空密集相互作用 R ^ s p a s − t ∈ R T o b s × N × N \hat{R}_{\mathrm{spa}}^{\mathrm{s-t}} \in \mathbb{R}^{T_{o b s} \times N \times N} R^spas−t∈RTobs×N×N。
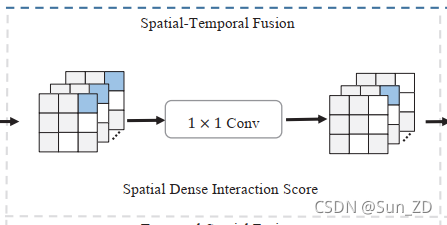
一片 R ^ s p a s − t \hat{R}_{\mathrm{spa}}^{\mathrm{s-t}} R^spas−t在每个时间步是一个不对称方阵,其 ( i , j ) − t h (i, j) -th (i,j)−th元素表示节点i对节点j的影响。然后,主动和被动的关系用矩阵的行和列分别表示可以组合获得高层互动功能。
具体来说,将一串非对称卷积核(asymmetric convolution)[39]分别应用于 R ^ s p a s − t \hat{R}_{\mathrm{spa}}^{\mathrm{s-t}} R^spas−t的行和列上,即:

其中:
F r o w ( l ) F^{(l)}_{row} Frow(l)and F c o l ( l ) F^{(l)}_{col} Fcol(l):分别表示第l层的基于行和基于列的非对称卷积特征映射, F ( l ) F^{(l)} F(l)为激活的特征映射, δ ( ⋅ ) δ(·) δ(⋅)为非线性激活函数。
K ( 1 × S ) row and K ( S × 1 ) col \mathcal{K}_{(1 \times S)}^{\text {row }} \text { and } \mathcal{K}_{(S \times 1)}^{\text {col }} K(1×S)row and K(S×1)col :分别是大小为(1×S)和(S×1)(即row和col向量)的卷积核。S=3
注意, F ( 0 ) F^{(0)} F(0)被初始化为 R ^ s p a s − t \hat{R}_{\mathrm{spa}}^{\mathrm{s-t}} R^spas−t ,并且所有的卷积操作都被填充为0,以便保持输出大小与输入大小相同。
因此,从最后一次卷积层得到的激活特征映射为高级别交互特征 F s p a ∈ T o b s × N × N F_{spa} \in T_{obs}× N × N Fspa∈Tobs×N×N。
利用超参数 ξ ∈ [ 0 , 1 ] ξ∈[0,1] ξ∈[0,1],通过 σ ( F s p a ) σ (Fspa) σ(Fspa)上的单元阈值生成稀疏交互掩模 M s p a M_{spa} Mspa。
当 F s p a [ i , j ] ≥ ξ F_{spa}[i, j]≥ξ Fspa[i,j]≥ξ时, M s p a M_{\mathrm{spa}} Mspa的 ( i , j ) − t h (i, j)-th (i,j)−th元设为1,否则为0,即
M s p a = I { σ ( F s p a ) ≥ ξ } M_{\mathrm{spa}}=\mathbb{I}\left\{\sigma\left(F_{\mathrm{spa}}\right) \geq \xi\right\} Mspa=I{σ(Fspa)≥ξ}
其中 I { . } \mathbb{I}\left\{ . \right\} I{.}是指示函数,如果对应的不等式成立,则输出1,否则输出0。
σ σ σ为Sigmoid 激活函数。
为了保证节点是自连接的,我们在交互掩码中添加一个单位矩阵 I I I,
然后通过逐个元素的乘法将其与时空密集交互 R ^ s p a s − t \hat{R}_{\mathrm{spa}}^{\mathrm{s-t}} R^spas−t融合,得到稀疏邻接矩阵 A s p a A_{spa} Aspa,即
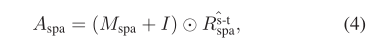
以前的一些工作(如[22])表明,邻接矩阵的标准化是GCN正常运行的必要条件。
而顶点域的相关工作直接采用Softmax函数对邻接矩阵进行归一化其副作用是,由于Softmax对零输入输出非零值,稀疏矩阵又会变回密集矩阵。在这种情况下,没有互动的行人被迫再次互动。为了避免这个问题,我们设计了一个“Zero-Softmax”函数来保持稀疏性,消融研究的实验结果表明“Zero-Softmax”可以进一步提高性能。具体来说,给定一个平坦矩阵 x = [ x 1 , x 2 , … , x D ] x = [x1,x2,…,x_D] x=[x1,x2,…,xD],
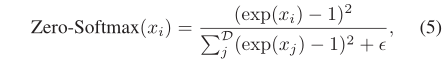
其中 ϵ \epsilon ϵ是一个可以忽略的小常数,以确保数值稳定性,
D \mathcal{D} D是输入向量的维数。
在此基础上,得到归一化稀疏邻接矩阵 A ^ s p a = Zero-Softmax ( A s p a ) \hat{A}_{s p a}=\text { Zero-Softmax }\left(A_{s p a}\right) A^spa= Zero-Softmax (Aspa)。由此,最终从空间图输入中得到一个表示稀疏有向交互的时空稀疏有向图 G ^ s p a = ( V t , A ^ s p a ) \hat{G}_{\mathrm{spa}}=\left(V^{t}, \hat{A}_{\mathrm{spa}}\right) G^spa=(Vt,A^spa)。
整个过程如图3所示。
3.Sparse Directed Temporal Graph稀疏定向时间图

按照与稀疏有向空间图相似的方法,我们也可以从时间图输入中获得有效的运动趋势,即归一化邻接矩阵 A ^ t m p \hat{A}_{tmp} A^tmp,但有两点不同。
- 首先,在 E t m p E_{tmp} Etmp中加入一个位置编码张量 E \mathcal{E} E[40],即 E tmp = ϕ ( G tmp , W E tmp ) + E E_{\text {tmp }}=\phi\left(G_{\text {tmp }}, W_{E}^{\text {tmp }}\right)+\mathcal{E} Etmp =ϕ(Gtmp ,WEtmp )+E,因为不同顺序的轨迹点表示不同的运动趋势。值得注意的是,由于时间依赖关系,密集时间交互 R t m p R_{tmp} Rtmp也是像 U t U^t Ut一样的上三角矩阵
- 第二个区别在于如图3所示的时间-空间融合步骤,我们
不能对叠加 R tmp ∈ R T obs × T obs R_{\text {tmp }} \in \mathbb{R}^{T_{\text {obs }} \times T_{\text {obs }}} Rtmp ∈RTobs ×Tobs 得到的 R t m p t s ∈ R N × T o b s × T o b s R_{\mathrm{tmp}}^{\mathrm{t} \mathrm{s}} \in \mathbb{R}^{N \times T_{o b s} \times T_{o b s}} Rtmpts∈RN×Tobs×Tobs进行卷积,因为不同场景的行人数量N是可变的。为了简化操作,我们直接将 R t m p t − s R_{\mathrm{tmp}}^{\mathrm{t} -\mathrm{s}} Rtmpt−s看作是时间-空间的密集相互作用。
 由此,我们最终从时间图输入中得到一个表示运动趋势的时空稀疏有向图 G ^ tmp = ( V n , A ^ tmp ) \hat{G}_{\text {tmp }}=\left(V_{n}, \hat{A}_{\text {tmp }}\right) G^tmp =(Vn,A^tmp )。
由此,我们最终从时间图输入中得到一个表示运动趋势的时空稀疏有向图 G ^ tmp = ( V n , A ^ tmp ) \hat{G}_{\text {tmp }}=\left(V_{n}, \hat{A}_{\text {tmp }}\right) G^tmp =(Vn,A^tmp )。
3.2. Trajectory Representation and Prediction
GCNs能够聚合表示 A ^ spa ( S D I ) and A ^ t m p ( M T ) \hat{A}_{\text {spa }}(\mathrm{SDI}) \text { and } \hat{A}_{\mathrm{tmp}}(\mathrm{MT}) A^spa (SDI) and A^tmp(MT)的稀疏图的节点,并学习其轨迹表示。如图2所示,我们使用两个GCNs来学习轨迹表示,其中一个分支 A ^ spa ( S D I ) \hat{A}_{\text {spa }}(\mathrm{SDI}) A^spa (SDI)在 A ^ t m p ( M T ) \hat{A}_{\mathrm{tmp}}(\mathrm{MT}) A^tmp(MT)之前馈送到网络.
而在另一个分支中,它们以相反的顺序馈送。
因此,第一个分支产生交互-趋势特征 H I T F H_{ITF} HITF,而另一个分支产生趋势-交互特征 H T I F H_{TIF} HTIF,即
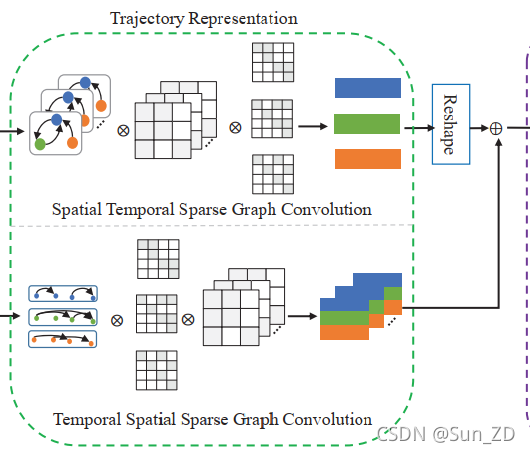
H I T F ( l ) = δ ( A ^ t m p ⋅ δ ( A ^ s p a H I T F ( l − 1 ) W s p a l ( l ) ) W t m p 1 ( l ) ) H T I F ( l ) = δ ( A ^ s p a ⋅ δ ( A ^ t m p H T I F ( l − 1 ) W t m p 2 ( l ) ) W s p a 2 ( l ) ) \begin{array}{l} H_{\mathrm{ITF}}^{(l)}=\delta\left(\hat{A}_{\mathrm{tmp}} \cdot \delta\left(\hat{A}_{\mathrm{spa}} H_{\mathrm{ITF}}^{(l-1)} \mathbf{W}_{\mathrm{spal}}^{(l)}\right) \mathbf{W}_{\mathrm{tmp1}}^{(l)}\right) \\ H_{\mathrm{TIF}}^{(l)}=\delta\left(\hat{A}_{\mathrm{spa}} \cdot \delta\left(\hat{A}_{\mathrm{tmp}} H_{\mathrm{TIF}}^{(l-1)} \mathbf{W}_{\mathrm{tmp} 2}^{(l)}\right) \mathbf{W}_{\mathrm{spa} 2}^{(l)}\right) \end{array} HITF(l)=δ(A^tmp⋅δ(A^spaHITF(l−1)Wspal(l))Wtmp1(l))HTIF(l)=δ(A^spa⋅δ(A^tmpHTIF(l−1)Wtmp2(l))Wspa2(l))
其中:
W t m p 1 , W s p a 1 , W t m p 2 and W s p a 2 \mathbf{W}_{\mathrm{tmp1}}, \mathbf{W}_{\mathrm{spa} 1}, \mathbf{W}_{\mathrm{tmp} 2} \text { and } \mathbf{W}_{\mathrm{spa} 2} Wtmp1,Wspa1,Wtmp2 and Wspa2:GCN weights
l l l表示GCN的第l层。
H I T F ( 0 ) H^{(0)}_{ITF} HITF(0)初始化为 G ^ spa \hat{G}_{\text {spa }} G^spa , H T I F ( 0 ) H_{\mathrm{TIF}}^{(0)} HTIF(0)初始化为 G ^ t m p \hat{G}_{\mathrm{tmp}} G^tmp。
轨迹表示 H H H是最后一个GCN输出 H I T F H_{\mathrm{ITF}} HITFand H T I F H_{\mathrm{TIF}} HTIF的和。
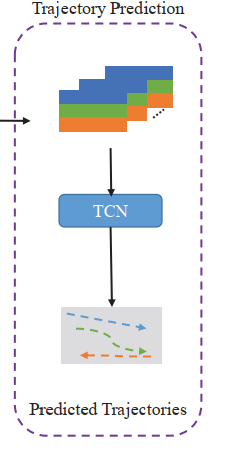
1. Trajectory Prediction and Loss Function
我们遵循Social-LSTM[1]认为轨迹坐标 ( x n t , y n t ) \left(x_{n}^{t}, y_{n}^{t}\right) (xnt,ynt)在时间t的行人n步遵循bi-variate高斯分布 N ( μ ^ n t , σ ^ n t , ρ ^ n t ) \mathcal{N}\left(\hat{\mu}_{n}^{t}, \hat{\sigma}_{n}^{t}, \hat{\rho}_{n}^{t}\right) N(μ^nt,σ^nt,ρ^nt),
μ ^ n t \hat{\mu}_{n}^{t} μ^nt是均值,
标准差 σ ^ n t \hat{\sigma}_{n}^{t} σ^nt
相关系数 ρ ^ n t \hat{\rho}_{n}^{t} ρ^nt。
给定最终轨迹表示 H H H,我们可以预测TCN[4]在时间维度上遵循SocialSTGCNN[32]的双高斯分布参数。值得注意的是,选择TCN是因为它不像传统rnn那样存在梯度消失和计算成本高[14,20,6]。
因此,该方法可以通过将负对数似然损失最小化为来进行训练
L n ( W ) = − ∑ t = T obs + 1 T ped log P ( ( x n t , y n t ) ∣ μ ^ n t , σ ^ n t , ρ ^ n t ) L^{n}(\mathbf{W})=-\sum_{t=T_{\text {obs }}+1}^{T_{\text {ped }}} \log P\left(\left(x_{n}^{t}, y_{n}^{t}\right) \mid \hat{\mu}_{n}^{t}, \hat{\sigma}_{n}^{t}, \hat{\rho}_{n}^{t}\right) Ln(W)=−t=Tobs +1∑Tped logP((xnt,ynt)∣μ^nt,σ^nt,ρ^nt)
W表示方法中所有可训练的参数。
4. Experiments and Analysis
Evaluation Datasets 为了验证我们提出的方法的有效性,我们使用了两个公共的行人轨迹数据集,即ETH[34]和UCY[24],这两个数据集是轨迹预测任务中使用最广泛的基准。其中ETH数据集包含ETH和HOTEL场景,而UCY数据集包含UNIV、ZARA1、ZARA2三个不同场景。我们采用[38]方法进行培训和评估。我们遵循现有的工作,观察8帧(3.2秒)的轨迹,并预测接下来的12帧(4.8秒)。
Evaluation Metrics 我们采用平均位移误差(ADE)[36]和最终位移误差(FDE)[1]两个指标来评价预测结果。ADE测量方法得到的所有预测轨迹点与所有地真未来轨迹点之间的平均L-2距离,而FDE测量方法得到的最终预测目的地与地真未来轨迹点最终目的地之间的L-2距离。
Experimental Settings.
在我们的实验中,自注意的嵌入维数和图嵌入维数均设置为64。
自注意层数为1。
非对称卷积网络由7个卷积层组成,其核大小为S = 3。
时空GCN和时空GCN级联1层。
TCN级联4层。
阈值 ξ ξ ξ根据经验设置为0.5。
采用PRelu[13]作为非线性激活δ(·)。
采用Adam[21]优化器对该方法进行了150个epoch的训练,数据批大小为128。
初始学习率设置为0.001,其衰减系数为0.1,间隔为50个epoch。
在推断阶段,从学习到的双变量高斯分布中抽取20个样本,并使用最接近地面真实的样本来计算ADE和FDE度量。
我们的方法在PyTorch[33]上实现。该准则已被公布。
4.1. Comparison with State-of-the-Arts
我们将我们的方法与过去四年中最先进的9种方法进行了比较,包括Vanilla LSTM[1]、Social-LSTM[1]、SGAN[11]、Sophie[37]、PITF[26]、Social-BiGA T[23]、Social-STGCNN[32]、RSGB[38]和STAR[47]。
结果如表1所示,使用ADE和FDE度量进行了评估。
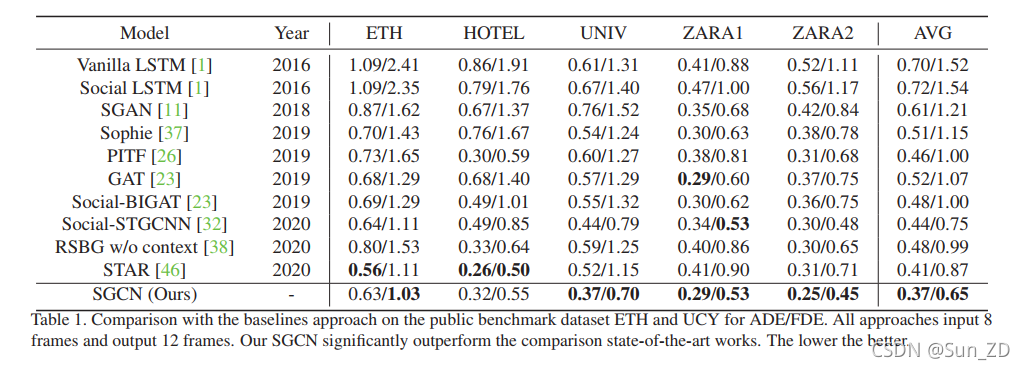
结果表明,该方法在ETH和UCY数据集上都显著优于其他方法。尤其是ADE度量,在ETH和UCY数据集上,我们的方法比之前最好的方法STAR[47]平均高出9%。对于FDE度量,我们的方法优于之前最好的方法Social-STGCNN [32] b,在ETH和UCY数据集上平均有13%的边际值。
据我们所知,潜在的原因是,我们的方法可以通过利用稀疏有向交互去除多余交互的干扰,并利用运动趋势来改进预测。
有趣的是,在以密集人群场景为主的UNIV序列上,我们的方法优于所有基于密集交互的方法,如SGAN[11]、Sophie[37]、GA T[23]、Social-BiGA T[23]、Social-STGCNN[32]和STAR[47]。
我们推测基于密集交互的方法可能会捕获多余的交互对象,从而导致预测误差。不同的是,我们的方法能够通过稀疏有向交互去除多余的交互,这有利于获得更好的性能。
4.2. Ablation Study
首先,我们在ETH和UCY数据集上进行了消融实验,以分离每个组件对最终性能的贡献。其次,我们设置了不同的阈值ξ值,以评估不同稀疏度下所提出的稀疏图的有效性。下面将介绍详细的实验。
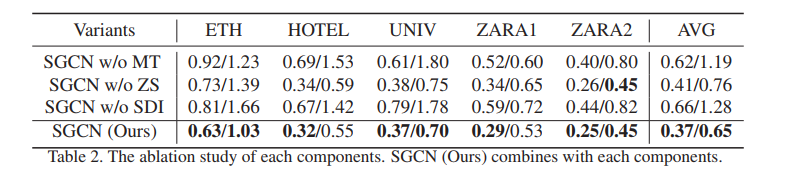
1.Contribution of Each Component各组分的贡献
如表2所示,我们评估了我们的方法的三个不同变体,
其中:
(1)SGCN w/o MT表示我们的方法中删除了运动趋势,其中它仅仅建模稀疏有向交互作用;
(2) SGCN w/o ZS表示用Softmax代替Zero-Softmax进行稀疏邻接矩阵归一化;
(3) SGCN w/o SDI表示在我们的方法中删除了稀疏有向交互作用,仅建模运动趋势。
从结果中,我们可以看到,从模型中删除任何组件都会导致性能大幅下降。特别地,SGCN不带MT的结果显示ADE的性能下降67%,FDE的性能下降83%,这明显验证了运动趋势对行人轨迹预测最终性能的贡献。
此外,SGCN w/o SDI在ADE中性能下降78%,在FDE中性能下降96%,表明稀疏定向交互对行人轨迹预测也很重要。
2 Effectiveness of Sparse Graph.稀疏图的有效性
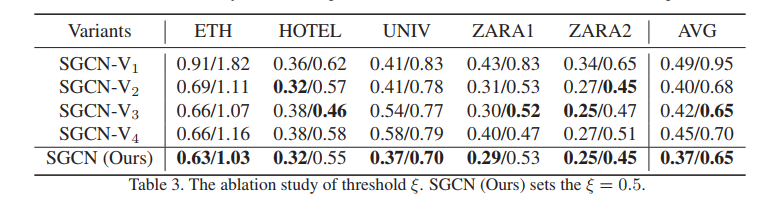
如表3所示,我们评估了我们方法的五个不同变体,其中:
(1)SGCN-V1:设置ξ = 1表示每对行人之间没有相互作用;
(2) SGCN-V2:当ξ = 0.75时,导致非常稀疏的有向相互作用;
(3) SGCN-V3:当ξ = 0.25时,出现相对密集的定向相互作用;
(4) SGCN-V4:设置ξ = 0,导致相互作用密集;
(5)SGCN:当ξ = 0.5时,它响应我们的全方法。
实验结果见表3。
我们发现当ξ = 0.5时,该方法的整体性能达到一个峰值,这意味着在一定程度上增强稀疏性是足够有效的。sgcn - v1的性能最低,说明行人之间建模交互的必要性。此外,sgcn - v2和sgcn - v3结果优于SGCN-V4,说明稀疏交互确实可以提高性能。
4.3. Visualization
1.Trajectory Prediction Visualization.
我们在图4中可视化了几个常见的交互场景,每个轨迹末端的实心点表示开始。更多的场景可视化将在补充材料中呈现。我们将我们的方法与Social-STGCNN[32]和SGAN[11]进行比较,因为它们都学习了未来轨迹的参数化分布。
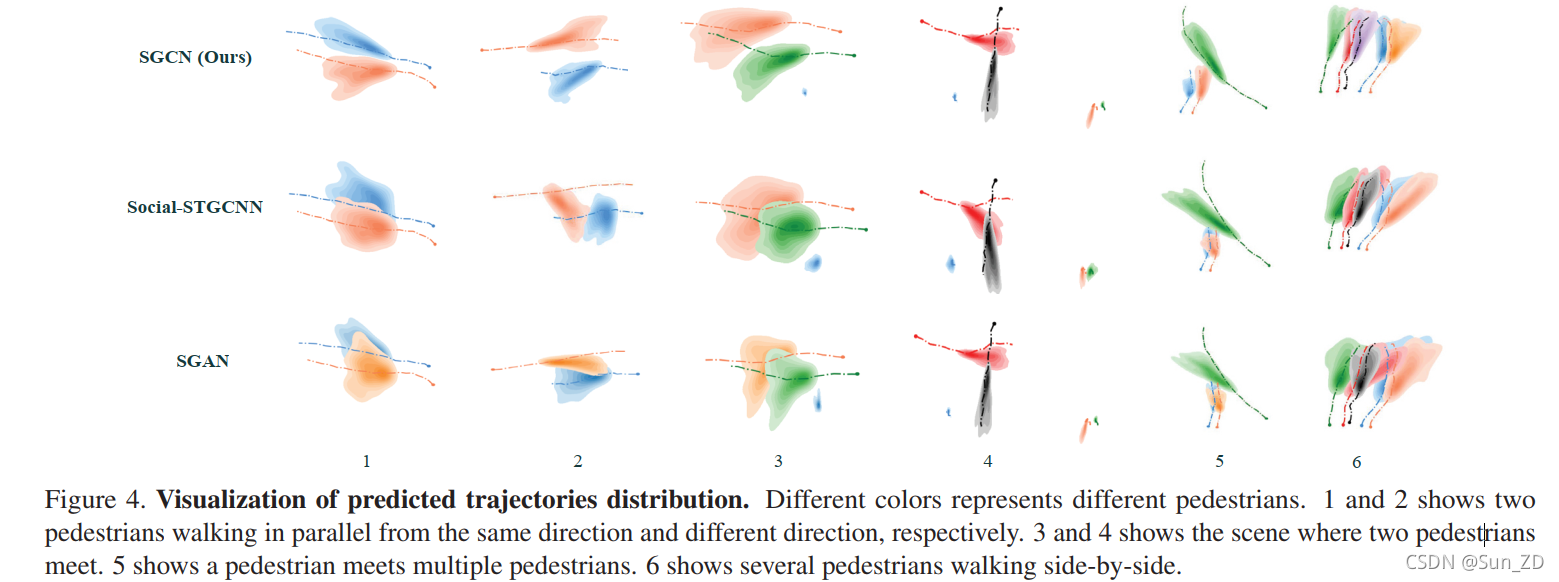
具体来说,场景1和场景2描述了两个行人分别在相同或相反的方向平行行走。在这些情况下,行人不太可能发生碰撞。
可视化显示,我们预测的分布沿地面真相有更好的趋势,而SocialGCNN和SGAN产生更大的重叠,这意味着潜在的碰撞,从而偏离地面真相。
场景3和4显示两个行人走向另一个静止的行人,一个行人和另一个行人分别以垂直的方向相遇。Social-STGCNN和SGAN同样存在重叠问题,碰撞的可能性很大,而我们预测的分布重叠较少。
特别地,绿色行人在场景3中静止不动,因此我们的预测分布方差较小,表明我们的方法捕获了场景3中静止行人不受其他行人影响的事实。
场景5和场景6代表了不止一个行人的相遇,其中我们的结果与ground-truth相当吻合,而Social-STGCNN和SGAN的结果有严重的重叠和偏离ground-truth。
综上所述,Social-STGCNN和SGAN都预测了重叠分布,偏离了ground-truth,而我们预测的分布重叠较少,沿着ground-truth有更好的趋势。对于重叠部分,可能是由于Social-STGCNN和SGAN模型中存在密集的相互作用,不可避免地会引入多余的相互作用,干扰正常轨迹,产生较大的绕道以避免碰撞。
相比之下,SGCN将稀疏的定向相互作用和运动趋势结合起来进行建模,从而得到更好的预测分布。
Sparse Directed Interaction Visualization稀疏有向交互可视化
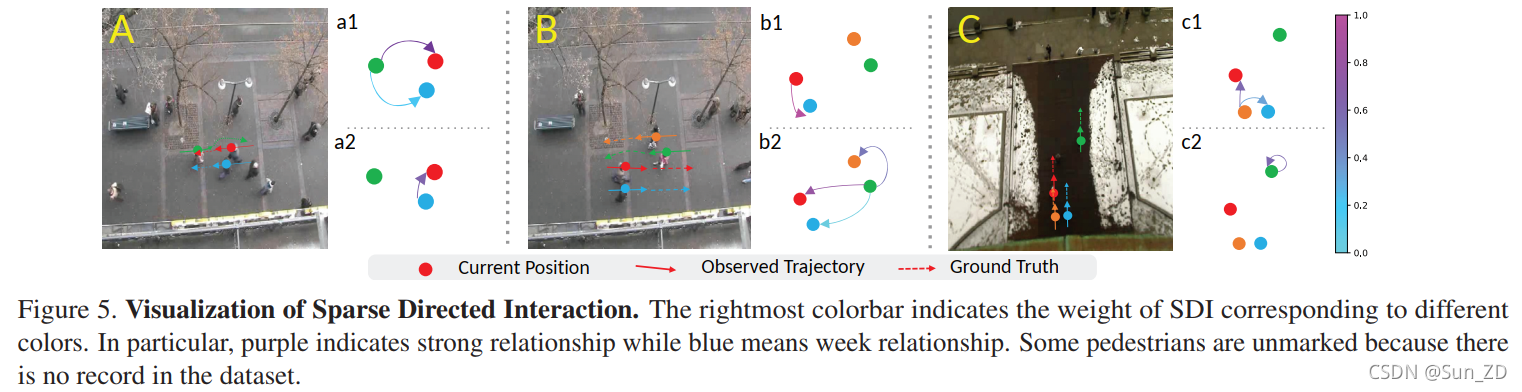
图5可视化了稀疏定向交互,从中我们发现我们的方法能够在不同的交互场景中捕捉有效的交互对象。
图(a2)、(b1)、(c1)和(c2)说明了一个节点只受其他节点的部分影响的稀疏有向交互。
例如图(a2)表示蓝色节点与红色节点之间的稀疏有向交互,符合A场景,根据ground-truth,蓝色节点的轨迹只受红色节点的影响。
此外,我们发现除了图(a2)、(b1)、(c1)和(c2)给出的稀疏有向交互外,我们的方法可以动态捕获交互对象。图(a1)和(b2)显示了绿色节点与所有标记节点的交互。
5. Conclusion
在本文中,我们提出了一个用于轨迹预测的稀疏图卷积网络,它利用了稀疏有向交互和运动趋势。
通过大量的实验评价,我们的方法比以往的方法取得了更好的性能。
此外,我们的方法可以更准确地预测轨迹,甚至在一些复杂的场景下,如一组行人平行行走。这些改进可以归因于我们方法识别稀疏定向交互和运动趋势的能力。
这篇关于论文翻译 SGCN:Sparse Graph Convolution Network for Pedestrian Trajectory Prediction 用于行人轨迹预测的稀疏图卷积网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








